 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable 3D Semantic Segmentation for Gun Detection in CT Scans
Dec 07, 2021
With the increased availability of 3D data, the need for solutions processing those also increased rapidly. However, adding dimension to already reliably accurate 2D approaches leads to immense memory consumption and higher computational complexity. These issues cause current hardware to reach its limitations, with most methods forced to reduce the input resolution drastically. Our main contribution is a novel deep 3D semantic segmentation method for gun detection in baggage CT scans that enables fast training and low video memory consumption for high-resolution voxelized volumes. We introduce a moving pyramid approach that utilizes multiple forward passes at inference time for segmenting an instance.
Detail-Preserving Pooling in Deep Networks
Apr 11, 2018
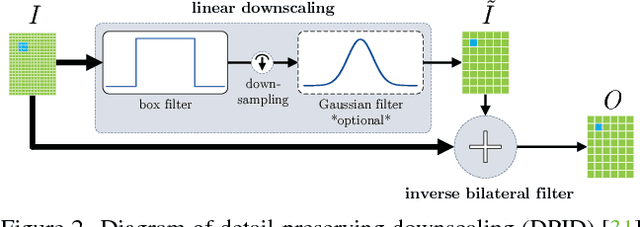
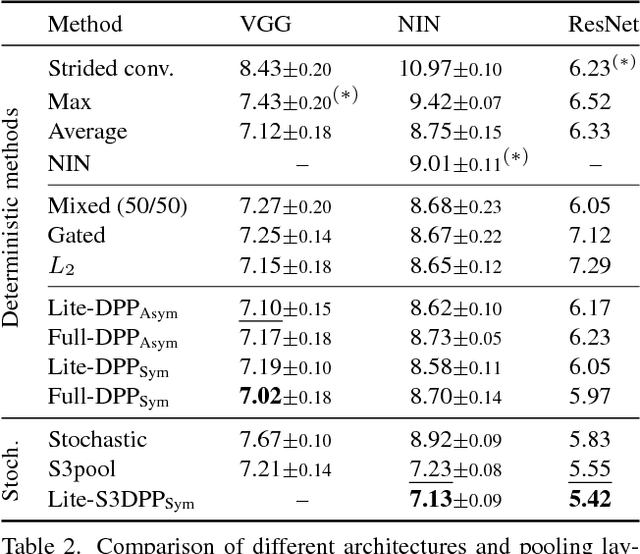
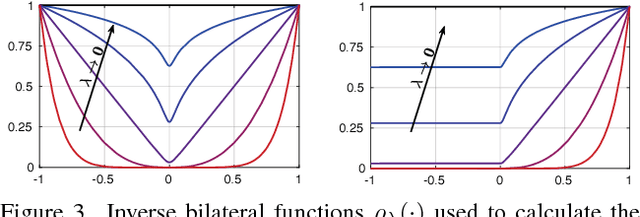
Most convolutional neural networks use some method for gradually downscaling the size of the hidden layers. This is commonly referred to as pooling, and is applied to reduce the number of parameters, improve invariance to certain distortions, and increase the receptive field size. Since pooling by nature is a lossy process, it is crucial that each such layer maintains the portion of the activations that is most important for the network's discriminability. Yet, simple maximization or averaging over blocks, max or average pooling, or plain downsampling in the form of strided convolutions are the standard. In this paper, we aim to leverage recent results on image downscaling for the purposes of deep learning. Inspired by the human visual system, which focuses on local spatial changes, we propose detail-preserving pooling (DPP), an adaptive pooling method that magnifies spatial changes and preserves important structural detail. Importantly, its parameters can be learned jointly with the rest of the network. We analyze some of its theoretical properties and show its empirical benefits on several datasets and networks, where DPP consistently outperforms previous pooling approaches.
Towards Learning free Naive Bayes Nearest Neighbor-based Domain Adaptation
Mar 26, 2015



As of today, object categorization algorithms are not able to achieve the level of robustness and generality necessary to work reliably in the real world. Even the most powerful convolutional neural network we can train fails to perform satisfactorily when trained and tested on data from different databases. This issue, known as domain adaptation and/or dataset bias in the literature, is due to a distribution mismatch between data collections. Methods addressing it go from max-margin classifiers to learning how to modify the features and obtain a more robust representation. Recent work showed that by casting the problem into the image-to-class recognition framework, the domain adaptation problem is significantly alleviated \cite{danbnn}. Here we follow this approach, and show how a very simple, learning free Naive Bayes Nearest Neighbor (NBNN)-based domain adaptation algorithm can significantly alleviate the distribution mismatch among source and target data, especially when the number of classes and the number of sources grow. Experiments on standard benchmarks used in the literature show that our approach (a) is competitive with the current state of the art on small scale problems, and (b) achieves the current state of the art as the number of classes and sources grows, with minimal computational requirements.