Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable 3D Semantic Segmentation for Gun Detection in CT Scans
Paper and Code
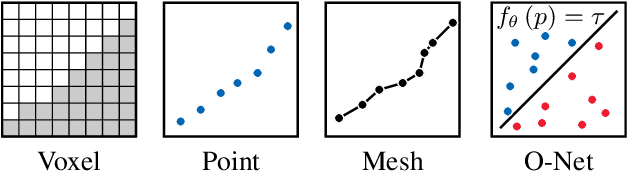
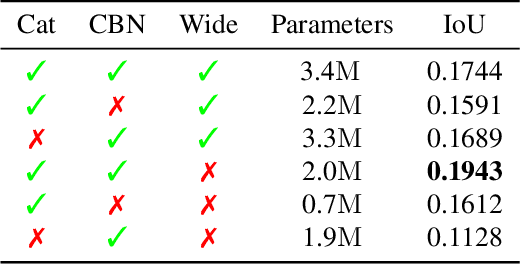
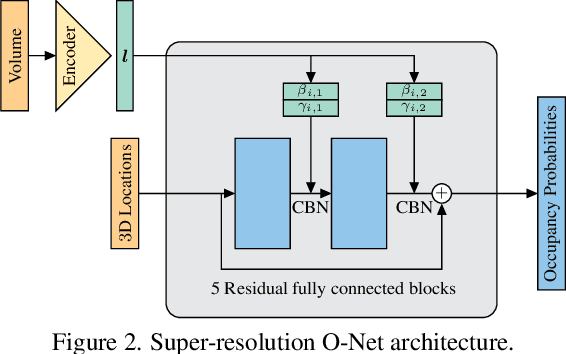
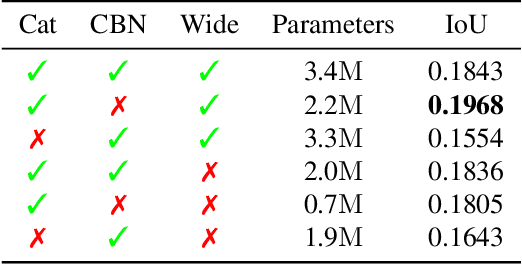
With the increased availability of 3D data, the need for solutions processing those also increased rapidly. However, adding dimension to already reliably accurate 2D approaches leads to immense memory consumption and higher computational complexity. These issues cause current hardware to reach its limitations, with most methods forced to reduce the input resolution drastically. Our main contribution is a novel deep 3D semantic segmentation method for gun detection in baggage CT scans that enables fast training and low video memory consumption for high-resolution voxelized volumes. We introduce a moving pyramid approach that utilizes multiple forward passes at inference time for segmenting an instance.
* This work was part of the Project Lab Deep Learning in Computer
Vision Winter Semester 2019/2020 at TU Darmstadt
View paper on