 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Collaborative Fine-Tuning for On-Device Large Language Models
Apr 15, 2024



We explore on-device self-supervised collaborative fine-tuning of large language models with limited local data availability. Taking inspiration from the collaborative learning community, we introduce three distinct trust-weighted gradient aggregation schemes: weight similarity-based, prediction similarity-based and validation performance-based. To minimize communication overhead, we integrate Low-Rank Adaptation (LoRA) and only exchange LoRA weight updates. Our protocols, driven by prediction and performance metrics, surpass both FedAvg and local fine-tuning methods, which is particularly evident in realistic scenarios with more diverse local data distributions. The results underscore the effectiveness of our approach in addressing heterogeneity and scarcity within local datasets.
Towards Improving Proactive Dialog Agents Using Socially-Aware Reinforcement Learning
Nov 25, 2022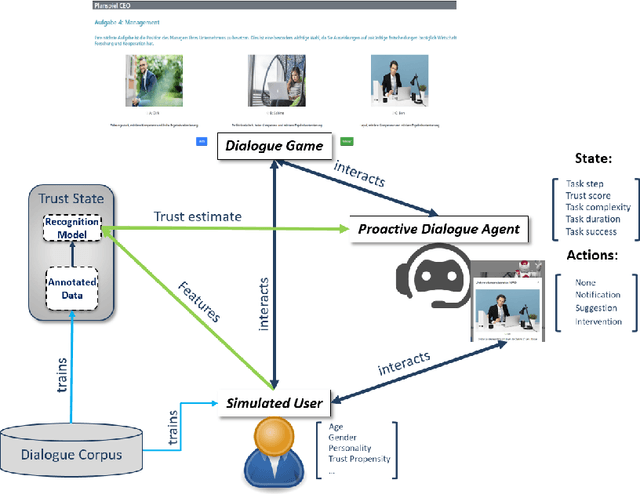
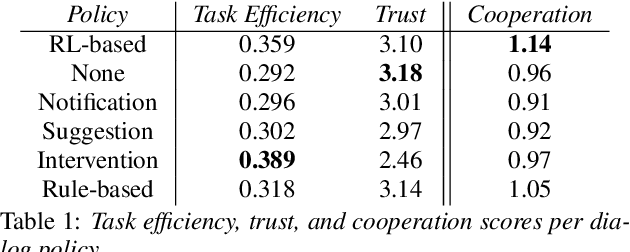
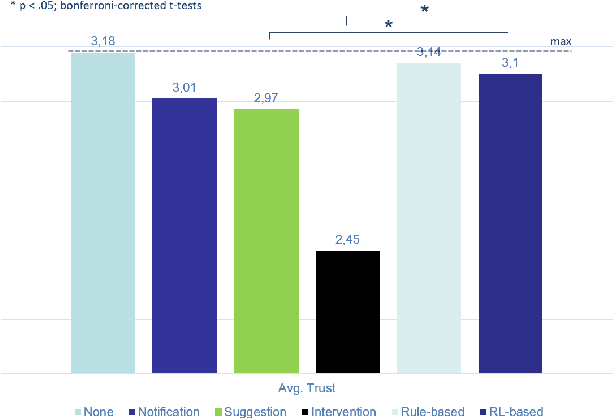
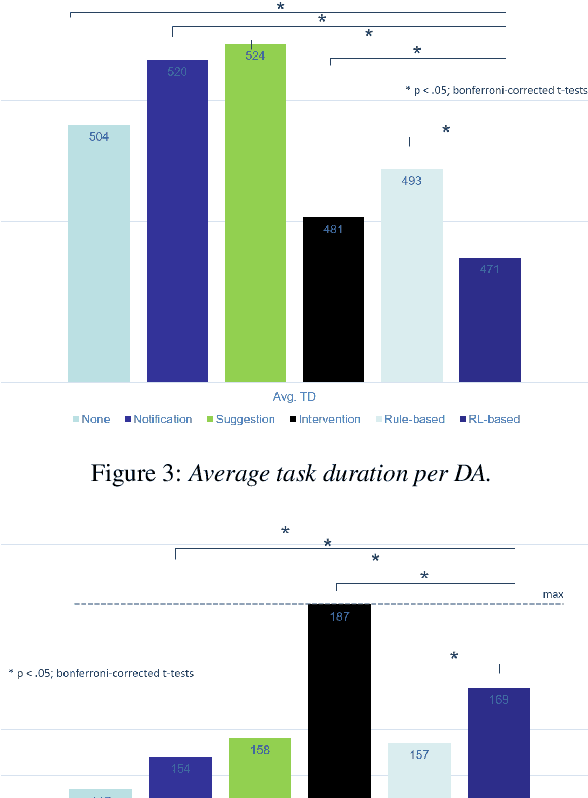
The next step for intelligent dialog agents is to escape their role as silent bystanders and become proactive. Well-defined proactive behavior may improve human-machine cooperation, as the agent takes a more active role during interaction and takes off responsibility from the user. However, proactivity is a double-edged sword because poorly executed pre-emptive actions may have a devastating effect not only on the task outcome but also on the relationship with the user. For designing adequate proactive dialog strategies, we propose a novel approach including both social as well as task-relevant features in the dialog. Here, the primary goal is to optimize proactive behavior so that it is task-oriented - this implies high task success and efficiency - while also being socially effective by fostering user trust. Including both aspects in the reward function for training a proactive dialog agent using reinforcement learning showed the benefit of our approach for more successful human-machine cooperation.
Federated Stain Normalization for Computational Pathology
Sep 29, 2022Although deep federated learning has received much attention in recent years, progress has been made mainly in the context of natural images and barely for computational pathology. However, deep federated learning is an opportunity to create datasets that reflect the data diversity of many laboratories. Further, the effort of dataset construction can be divided among many. Unfortunately, existing algorithms cannot be easily applied to computational pathology since previous work presupposes that data distributions of laboratories must be similar. This is an unlikely assumption, mainly since different laboratories have different staining styles. As a solution, we propose BottleGAN, a generative model that can computationally align the staining styles of many laboratories and can be trained in a privacy-preserving manner to foster federated learning in computational pathology. We construct a heterogenic multi-institutional dataset based on the PESO segmentation dataset and improve the IOU by 42\% compared to existing federated learning algorithms. An implementation of BottleGAN is available at https://github.com/MECLabTUDA/BottleGAN
Scalable 3D Semantic Segmentation for Gun Detection in CT Scans
Dec 07, 2021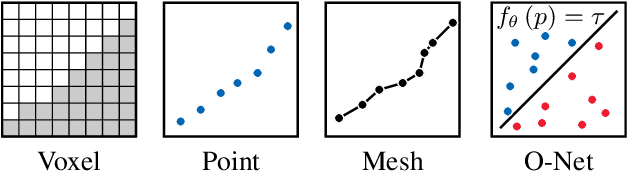
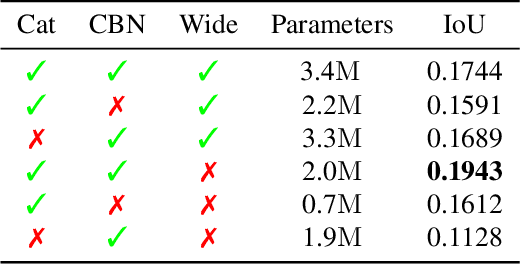
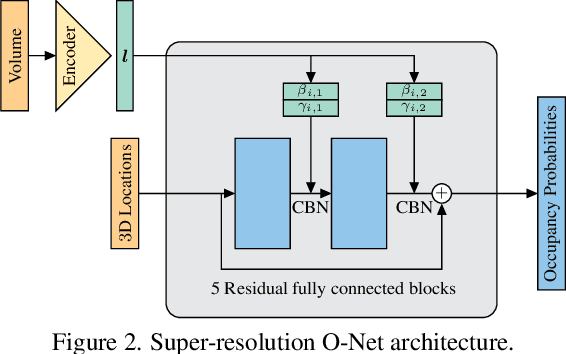
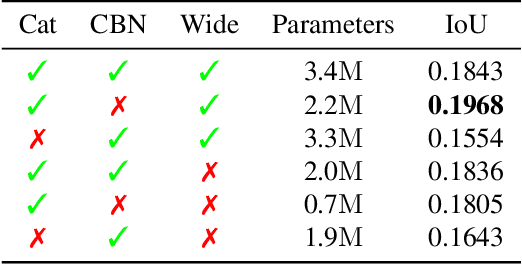
With the increased availability of 3D data, the need for solutions processing those also increased rapidly. However, adding dimension to already reliably accurate 2D approaches leads to immense memory consumption and higher computational complexity. These issues cause current hardware to reach its limitations, with most methods forced to reduce the input resolution drastically. Our main contribution is a novel deep 3D semantic segmentation method for gun detection in baggage CT scans that enables fast training and low video memory consumption for high-resolution voxelized volumes. We introduce a moving pyramid approach that utilizes multiple forward passes at inference time for segmenting an instance.
Rule Extraction from Binary Neural Networks with Convolutional Rules for Model Validation
Dec 15, 2020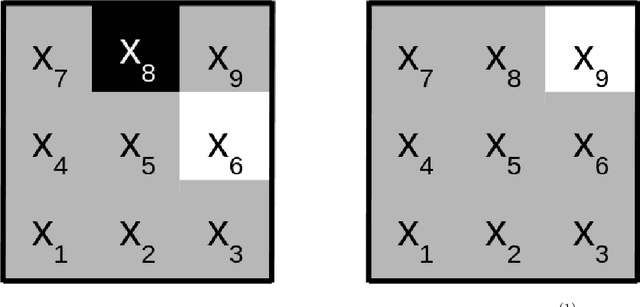
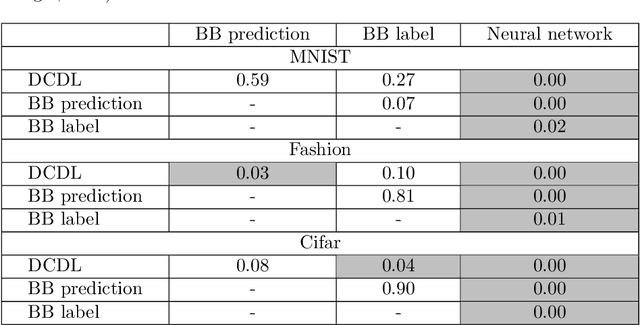
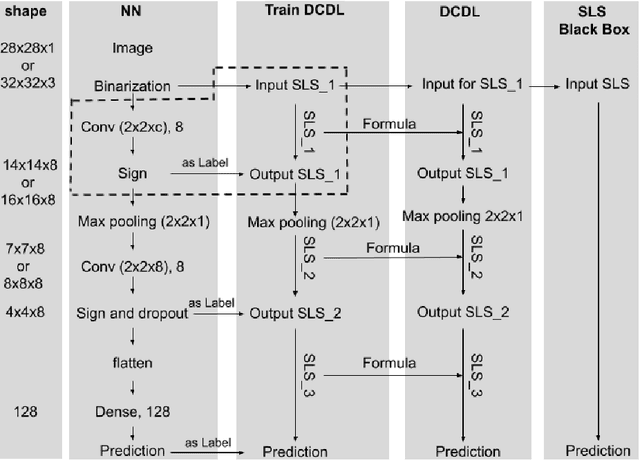
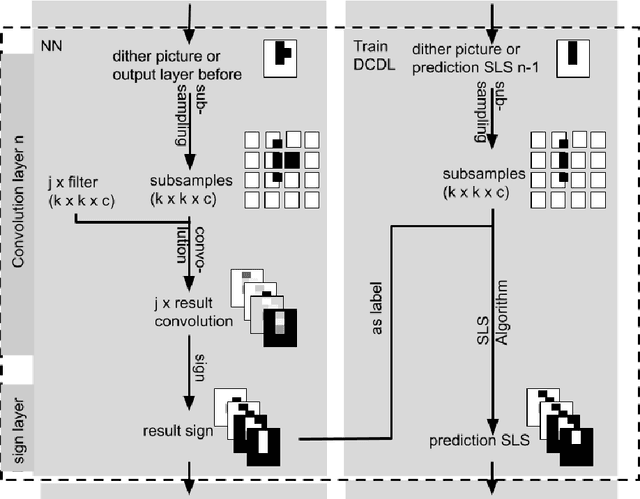
Most deep neural networks are considered to be black boxes, meaning their output is hard to interpret. In contrast, logical expressions are considered to be more comprehensible since they use symbols that are semantically close to natural language instead of distributed representations. However, for high-dimensional input data such as images, the individual symbols, i.e. pixels, are not easily interpretable. We introduce the concept of first-order convolutional rules, which are logical rules that can be extracted using a convolutional neural network (CNN), and whose complexity depends on the size of the convolutional filter and not on the dimensionality of the input. Our approach is based on rule extraction from binary neural networks with stochastic local search. We show how to extract rules that are not necessarily short, but characteristic of the input, and easy to visualize. Our experiments show that the proposed approach is able to model the functionality of the neural network while at the same time producing interpretable logical rules.
NeuralQAAD: An Efficient Differentiable Framework for High Resolution Point Cloud Compression
Dec 15, 2020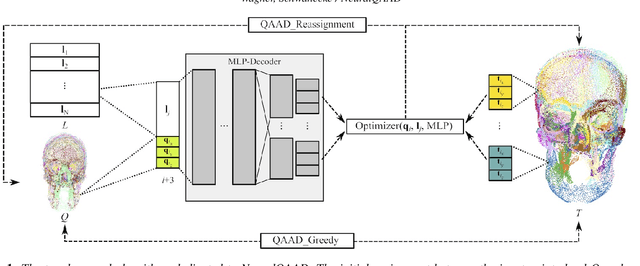
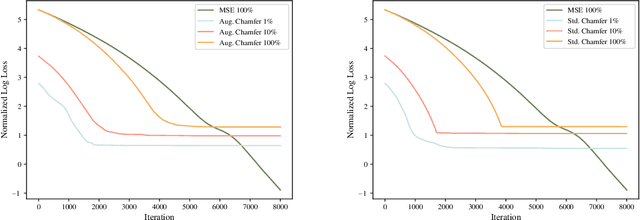
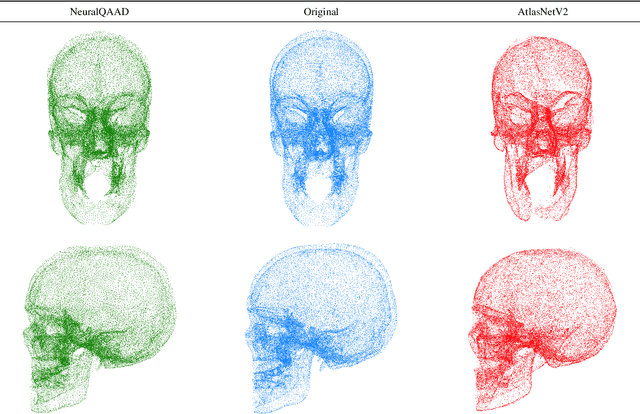

In this paper, we propose NeuralQAAD, a differentiable point cloud compression framework that is fast, robust to sampling, and applicable to high resolutions. Previous work that is able to handle complex and non-smooth topologies is hardly scaleable to more than just a few thousand points. We tackle the task with a novel neural network architecture characterized by weight sharing and autodecoding. Our architecture uses parameters much more efficiently than previous work, allowing us to be deeper and scalable. Futhermore, we show that the currently only tractable training criterion for point cloud compression, the Chamfer distance, performances poorly for high resolutions. To overcome this issue, we pair our architecture with a new training procedure based upon a quadratic assignment problem (QAP) for which we state two approximation algorithms. We solve the QAP in parallel to gradient descent. This procedure acts as a surrogate loss and allows to implicitly minimize the more expressive Earth Movers Distance (EMD) even for point clouds with way more than $10^6$ points. As evaluating the EMD on high resolution point clouds is intractable, we propose a divide-and-conquer approach based on k-d trees, the EM-kD, as a scaleable and fast but still reliable upper bound for the EMD. NeuralQAAD is demonstrated on COMA, D-FAUST, and Skulls to significantly outperform the current state-of-the-art visually and in terms of the EM-kD. Skulls is a novel dataset of skull CT-scans which we will make publicly available together with our implementation of NeuralQAAD.
Super-Selfish: Self-Supervised Learning on Images with PyTorch
Dec 07, 2020Super-Selfish is an easy to use PyTorch framework for image-based self-supervised learning. Features can be learned with 13 algorithms that span from simple classification to more complex state of theart contrastive pretext tasks. The framework is easy to use and allows for pretraining any PyTorch neural network with only two lines of code. Simultaneously, full flexibility is maintained through modular design choices. The code can be found at https://github.com/MECLabTUDA/Super_Selfish and installed using pip install super-selfish.