 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptable Hindsight Experience Replay for Search-Based Learning
Nov 05, 2025AlphaZero-like Monte Carlo Tree Search systems, originally introduced for two-player games, dynamically balance exploration and exploitation using neural network guidance. This combination makes them also suitable for classical search problems. However, the original method of training the network with simulation results is limited in sparse reward settings, especially in the early stages, where the network cannot yet give guidance. Hindsight Experience Replay (HER) addresses this issue by relabeling unsuccessful trajectories from the search tree as supervised learning signals. We introduce Adaptable HER (\ours{}), a flexible framework that integrates HER with AlphaZero, allowing easy adjustments to HER properties such as relabeled goals, policy targets, and trajectory selection. Our experiments, including equation discovery, show that the possibility of modifying HER is beneficial and surpasses the performance of pure supervised or reinforcement learning.
Amplifying Exploration in Monte-Carlo Tree Search by Focusing on the Unknown
Feb 13, 2024



Monte-Carlo tree search (MCTS) is an effective anytime algorithm with a vast amount of applications. It strategically allocates computational resources to focus on promising segments of the search tree, making it a very attractive search algorithm in large search spaces. However, it often expends its limited resources on reevaluating previously explored regions when they remain the most promising path. Our proposed methodology, denoted as AmEx-MCTS, solves this problem by introducing a novel MCTS formulation. Central to AmEx-MCTS is the decoupling of value updates, visit count updates, and the selected path during the tree search, thereby enabling the exclusion of already explored subtrees or leaves. This segregation preserves the utility of visit counts for both exploration-exploitation balancing and quality metrics within MCTS. The resultant augmentation facilitates in a considerably broader search using identical computational resources, preserving the essential characteristics of MCTS. The expanded coverage not only yields more precise estimations but also proves instrumental in larger and more complex problems. Our empirical evaluation demonstrates the superior performance of AmEx-MCTS, surpassing classical MCTS and related approaches by a substantial margin.
Peer Learning: Learning Complex Policies in Groups from Scratch via Action Recommendations
Dec 15, 2023Peer learning is a novel high-level reinforcement learning framework for agents learning in groups. While standard reinforcement learning trains an individual agent in trial-and-error fashion, all on its own, peer learning addresses a related setting in which a group of agents, i.e., peers, learns to master a task simultaneously together from scratch. Peers are allowed to communicate only about their own states and actions recommended by others: "What would you do in my situation?". Our motivation is to study the learning behavior of these agents. We formalize the teacher selection process in the action advice setting as a multi-armed bandit problem and therefore highlight the need for exploration. Eventually, we analyze the learning behavior of the peers and observe their ability to rank the agents' performance within the study group and understand which agents give reliable advice. Further, we compare peer learning with single agent learning and a state-of-the-art action advice baseline. We show that peer learning is able to outperform single-agent learning and the baseline in several challenging discrete and continuous OpenAI Gym domains. Doing so, we also show that within such a framework complex policies from action recommendations beyond discrete action spaces can evolve.
Rule Extraction from Binary Neural Networks with Convolutional Rules for Model Validation
Dec 15, 2020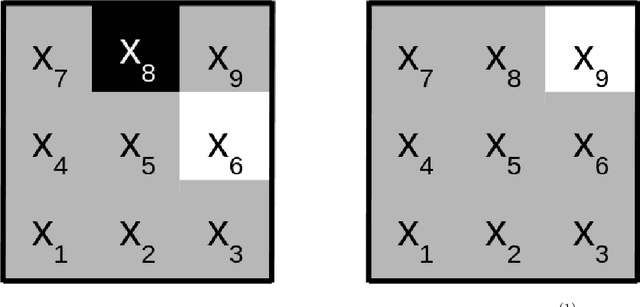
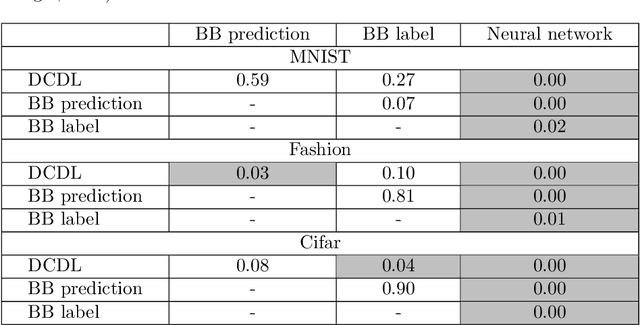
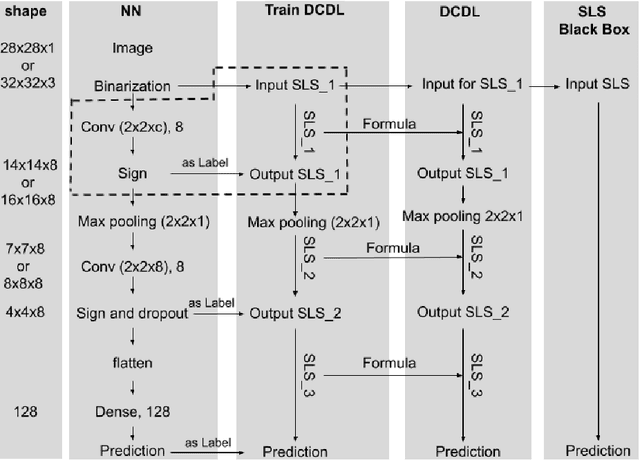
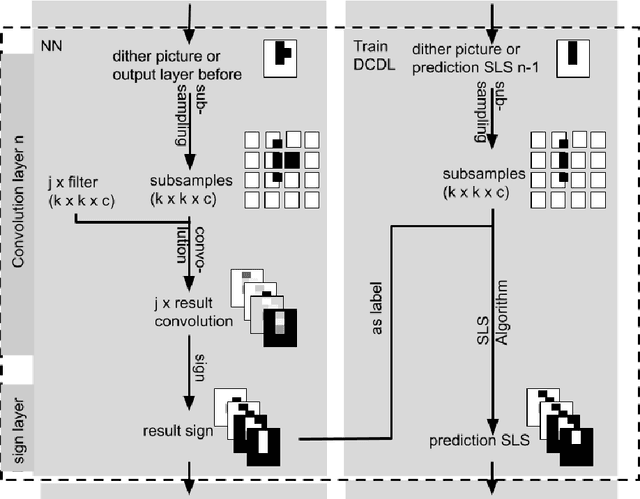
Most deep neural networks are considered to be black boxes, meaning their output is hard to interpret. In contrast, logical expressions are considered to be more comprehensible since they use symbols that are semantically close to natural language instead of distributed representations. However, for high-dimensional input data such as images, the individual symbols, i.e. pixels, are not easily interpretable. We introduce the concept of first-order convolutional rules, which are logical rules that can be extracted using a convolutional neural network (CNN), and whose complexity depends on the size of the convolutional filter and not on the dimensionality of the input. Our approach is based on rule extraction from binary neural networks with stochastic local search. We show how to extract rules that are not necessarily short, but characteristic of the input, and easy to visualize. Our experiments show that the proposed approach is able to model the functionality of the neural network while at the same time producing interpretable logical rules.