 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom If-Statements to ML Pipelines: Revisiting Bias in Code-Generation
Apr 23, 2026Prior work evaluates code generation bias primarily through simple conditional statements, which represent only a narrow slice of real-world programming and reveal solely overt, explicitly encoded bias. We demonstrate that this approach dramatically underestimates bias in practice by examining a more realistic task: generating machine learning (ML) pipelines. Testing both code-specialized and general-instruction large language models, we find that generated pipelines exhibit significant bias during feature selection. Sensitive attributes appear in 87.7% of cases on average, despite models demonstrably excluding irrelevant features (e.g., including "race" while dropping "favorite color" for credit scoring). This bias is substantially more prevalent than that captured by conditional statements, where sensitive attributes appear in only 59.2% of cases. These findings are robust across prompt mitigation strategies, varying numbers of attributes, and different pipeline difficulty levels. Our results challenge simple conditionals as valid proxies for bias evaluation and suggest current benchmarks underestimate bias risk in practical deployments.
Rashomon Sets and Model Multiplicity in Federated Learning
Feb 10, 2026The Rashomon set captures the collection of models that achieve near-identical empirical performance yet may differ substantially in their decision boundaries. Understanding the differences among these models, i.e., their multiplicity, is recognized as a crucial step toward model transparency, fairness, and robustness, as it reveals decision boundaries instabilities that standard metrics obscure. However, the existing definitions of Rashomon set and multiplicity metrics assume centralized learning and do not extend naturally to decentralized, multi-party settings like Federated Learning (FL). In FL, multiple clients collaboratively train models under a central server's coordination without sharing raw data, which preserves privacy but introduces challenges from heterogeneous client data distribution and communication constraints. In this setting, the choice of a single best model may homogenize predictive behavior across diverse clients, amplify biases, or undermine fairness guarantees. In this work, we provide the first formalization of Rashomon sets in FL.First, we adapt the Rashomon set definition to FL, distinguishing among three perspectives: (I) a global Rashomon set defined over aggregated statistics across all clients, (II) a t-agreement Rashomon set representing the intersection of local Rashomon sets across a fraction t of clients, and (III) individual Rashomon sets specific to each client's local distribution.Second, we show how standard multiplicity metrics can be estimated under FL's privacy constraints. Finally, we introduce a multiplicity-aware FL pipeline and conduct an empirical study on standard FL benchmark datasets. Our results demonstrate that all three proposed federated Rashomon set definitions offer valuable insights, enabling clients to deploy models that better align with their local data, fairness considerations, and practical requirements.
Predicting NOx emissions in Biochar Production Plants using Machine Learning
Dec 10, 2024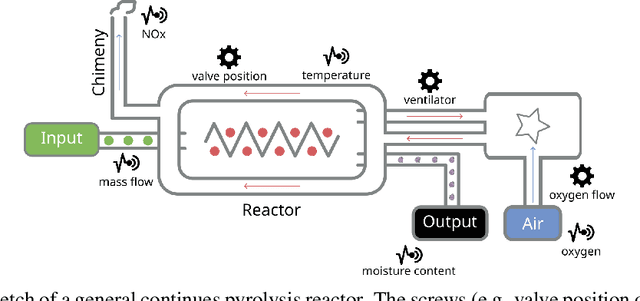
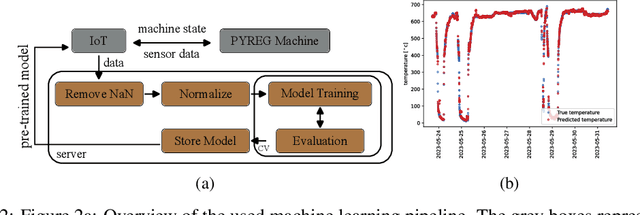
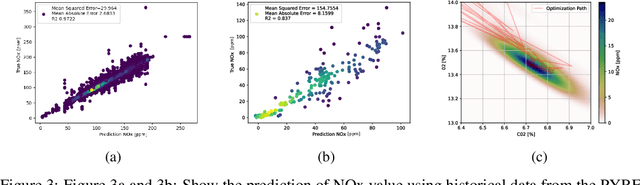
The global Biochar Industry has witnessed a surge in biochar production, with a total of 350k mt/year production in 2023. With the pressing climate goals set and the potential of Biochar Carbon Removal (BCR) as a climate-relevant technology, scaling up the number of new plants to over 1000 facilities per year by 2030 becomes imperative. However, such a massive scale-up presents not only technical challenges but also control and regulation issues, ensuring maximal output of plants while conforming to regulatory requirements. In this paper, we present a novel method of optimizing the process of a biochar plant based on machine learning methods. We show how a standard Random Forest Regressor can be used to model the states of the pyrolysis machine, the physics of which remains highly complex. This model then serves as a surrogate of the machine -- reproducing several key outcomes of the machine -- in a numerical optimization. This, in turn, could enable us to reduce NOx emissions -- a key regulatory goal in that industry -- while achieving maximal output still. In a preliminary test our approach shows remarkable results, proves to be applicable on two different machines from different manufacturers, and can be implemented on standard Internet of Things (IoT) devices more generally.
10 Years of Fair Representations: Challenges and Opportunities
Jul 04, 2024Fair Representation Learning (FRL) is a broad set of techniques, mostly based on neural networks, that seeks to learn new representations of data in which sensitive or undesired information has been removed. Methodologically, FRL was pioneered by Richard Zemel et al. about ten years ago. The basic concepts, objectives and evaluation strategies for FRL methodologies remain unchanged to this day. In this paper, we look back at the first ten years of FRL by i) revisiting its theoretical standing in light of recent work in deep learning theory that shows the hardness of removing information in neural network representations and ii) presenting the results of a massive experimentation (225.000 model fits and 110.000 AutoML fits) we conducted with the objective of improving on the common evaluation scenario for FRL. More specifically, we use automated machine learning (AutoML) to adversarially "mine" sensitive information from supposedly fair representations. Our theoretical and experimental analysis suggests that deterministic, unquantized FRL methodologies have serious issues in removing sensitive information, which is especially troubling as they might seem "fair" at first glance.
Peer Learning: Learning Complex Policies in Groups from Scratch via Action Recommendations
Dec 15, 2023Peer learning is a novel high-level reinforcement learning framework for agents learning in groups. While standard reinforcement learning trains an individual agent in trial-and-error fashion, all on its own, peer learning addresses a related setting in which a group of agents, i.e., peers, learns to master a task simultaneously together from scratch. Peers are allowed to communicate only about their own states and actions recommended by others: "What would you do in my situation?". Our motivation is to study the learning behavior of these agents. We formalize the teacher selection process in the action advice setting as a multi-armed bandit problem and therefore highlight the need for exploration. Eventually, we analyze the learning behavior of the peers and observe their ability to rank the agents' performance within the study group and understand which agents give reliable advice. Further, we compare peer learning with single agent learning and a state-of-the-art action advice baseline. We show that peer learning is able to outperform single-agent learning and the baseline in several challenging discrete and continuous OpenAI Gym domains. Doing so, we also show that within such a framework complex policies from action recommendations beyond discrete action spaces can evolve.
Automated Scientific Discovery: From Equation Discovery to Autonomous Discovery Systems
May 03, 2023



The paper surveys automated scientific discovery, from equation discovery and symbolic regression to autonomous discovery systems and agents. It discusses the individual approaches from a "big picture" perspective and in context, but also discusses open issues and recent topics like the various roles of deep neural networks in this area, aiding in the discovery of human-interpretable knowledge. Further, we will present closed-loop scientific discovery systems, starting with the pioneering work on the Adam system up to current efforts in fields from material science to astronomy. Finally, we will elaborate on autonomy from a machine learning perspective, but also in analogy to the autonomy levels in autonomous driving. The maximal level, level five, is defined to require no human intervention at all in the production of scientific knowledge. Achieving this is one step towards solving the Nobel Turing Grand Challenge to develop AI Scientists: AI systems capable of making Nobel-quality scientific discoveries highly autonomously at a level comparable, and possibly superior, to the best human scientists by 2050.
Invariant Representations with Stochastically Quantized Neural Networks
Aug 04, 2022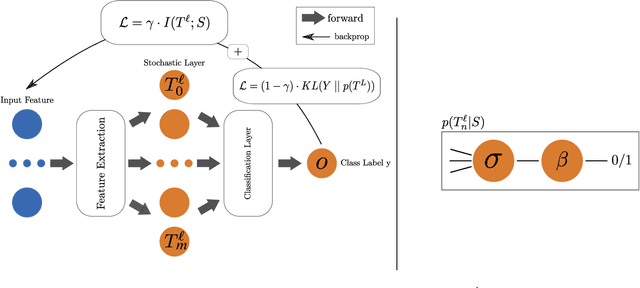
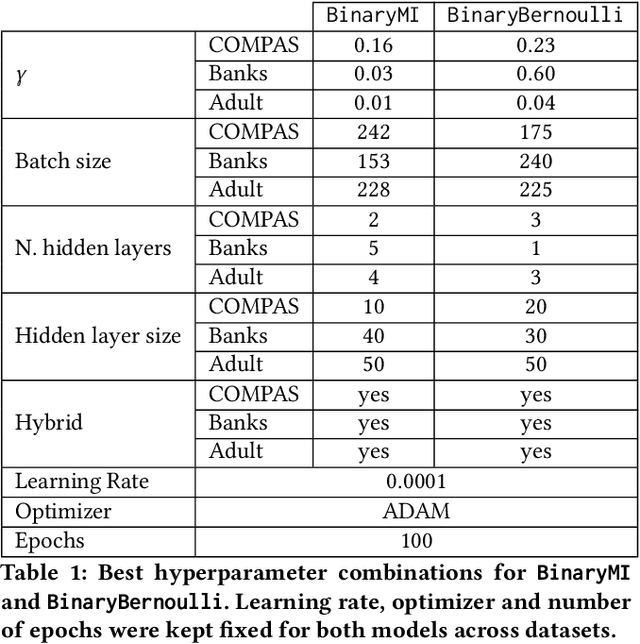
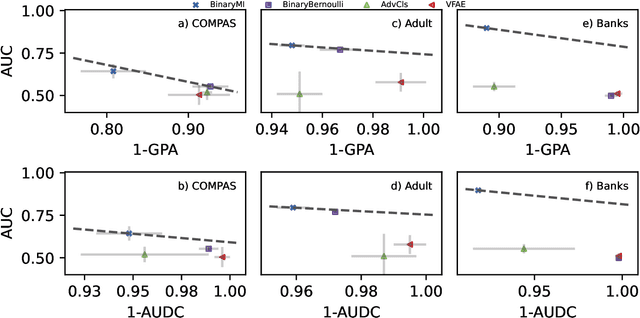

Representation learning algorithms offer the opportunity to learn invariant representations of the input data with regard to nuisance factors. Many authors have leveraged such strategies to learn fair representations, i.e., vectors where information about sensitive attributes is removed. These methods are attractive as they may be interpreted as minimizing the mutual information between a neural layer's activations and a sensitive attribute. However, the theoretical grounding of such methods relies either on the computation of infinitely accurate adversaries or on minimizing a variational upper bound of a mutual information estimate. In this paper, we propose a methodology for direct computation of the mutual information between a neural layer and a sensitive attribute. We employ stochastically-activated binary neural networks, which lets us treat neurons as random variables. We are then able to compute (not bound) the mutual information between a layer and a sensitive attribute and use this information as a regularization factor during gradient descent. We show that this method compares favorably with the state of the art in fair representation learning and that the learned representations display a higher level of invariance compared to full-precision neural networks.
Fair Interpretable Representation Learning with Correction Vectors
Feb 07, 2022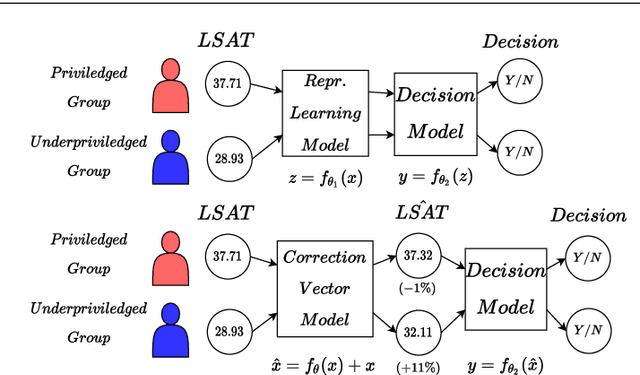
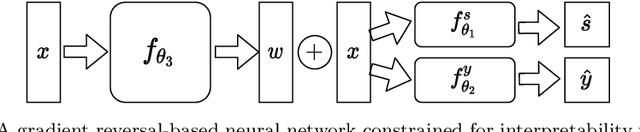
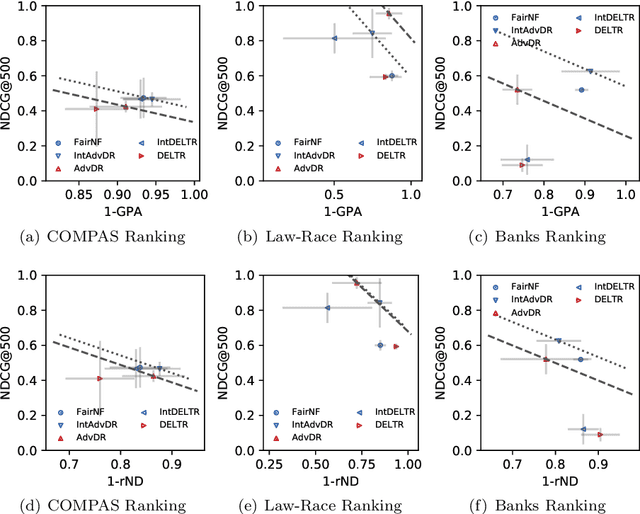
Neural network architectures have been extensively employed in the fair representation learning setting, where the objective is to learn a new representation for a given vector which is independent of sensitive information. Various representation debiasing techniques have been proposed in the literature. However, as neural networks are inherently opaque, these methods are hard to comprehend, which limits their usefulness. We propose a new framework for fair representation learning that is centered around the learning of "correction vectors", which have the same dimensionality as the given data vectors. Correction vectors may be computed either explicitly via architectural constraints or implicitly by training an invertible model based on Normalizing Flows. We show experimentally that several fair representation learning models constrained in such a way do not exhibit losses in ranking or classification performance. Furthermore, we demonstrate that state-of-the-art results can be achieved by the invertible model. Finally, we discuss the law standing of our methodology in light of recent legislation in the European Union.
Fair Interpretable Learning via Correction Vectors
Jan 17, 2022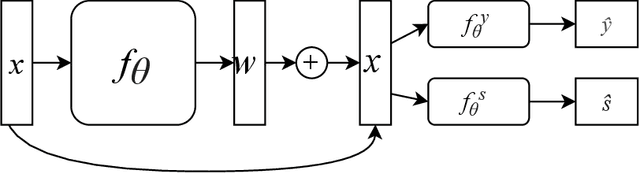
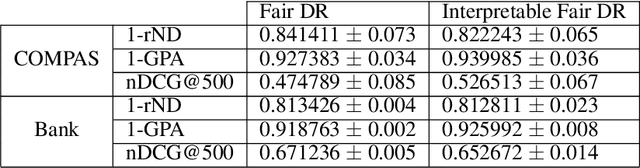

Neural network architectures have been extensively employed in the fair representation learning setting, where the objective is to learn a new representation for a given vector which is independent of sensitive information. Various "representation debiasing" techniques have been proposed in the literature. However, as neural networks are inherently opaque, these methods are hard to comprehend, which limits their usefulness. We propose a new framework for fair representation learning which is centered around the learning of "correction vectors", which have the same dimensionality as the given data vectors. The corrections are then simply summed up to the original features, and can therefore be analyzed as an explicit penalty or bonus to each feature. We show experimentally that a fair representation learning problem constrained in such a way does not impact performance.
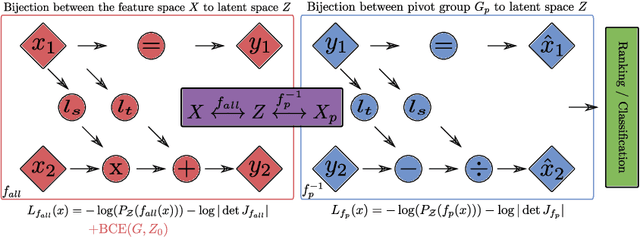
Fair Group-Shared Representations with Normalizing Flows
Jan 17, 2022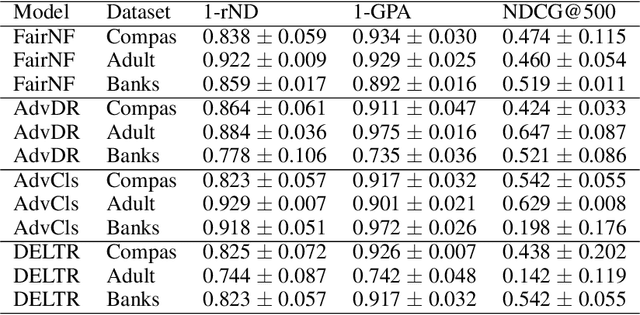
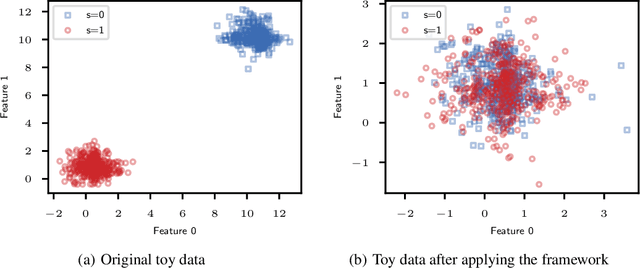

The issue of fairness in machine learning stems from the fact that historical data often displays biases against specific groups of people which have been underprivileged in the recent past, or still are. In this context, one of the possible approaches is to employ fair representation learning algorithms which are able to remove biases from data, making groups statistically indistinguishable. In this paper, we instead develop a fair representation learning algorithm which is able to map individuals belonging to different groups in a single group. This is made possible by training a pair of Normalizing Flow models and constraining them to not remove information about the ground truth by training a ranking or classification model on top of them. The overall, ``chained'' model is invertible and has a tractable Jacobian, which allows to relate together the probability densities for different groups and ``translate'' individuals from one group to another. We show experimentally that our methodology is competitive with other fair representation learning algorithms. Furthermore, our algorithm achieves stronger invariance w.r.t. the sensitive attribute.