 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting NOx emissions in Biochar Production Plants using Machine Learning
Dec 10, 2024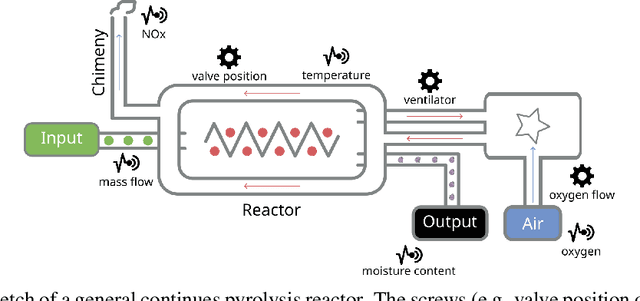
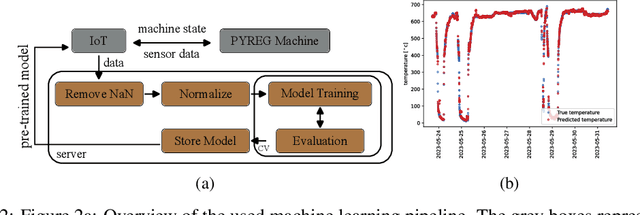
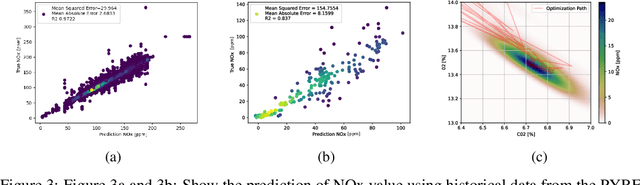
The global Biochar Industry has witnessed a surge in biochar production, with a total of 350k mt/year production in 2023. With the pressing climate goals set and the potential of Biochar Carbon Removal (BCR) as a climate-relevant technology, scaling up the number of new plants to over 1000 facilities per year by 2030 becomes imperative. However, such a massive scale-up presents not only technical challenges but also control and regulation issues, ensuring maximal output of plants while conforming to regulatory requirements. In this paper, we present a novel method of optimizing the process of a biochar plant based on machine learning methods. We show how a standard Random Forest Regressor can be used to model the states of the pyrolysis machine, the physics of which remains highly complex. This model then serves as a surrogate of the machine -- reproducing several key outcomes of the machine -- in a numerical optimization. This, in turn, could enable us to reduce NOx emissions -- a key regulatory goal in that industry -- while achieving maximal output still. In a preliminary test our approach shows remarkable results, proves to be applicable on two different machines from different manufacturers, and can be implemented on standard Internet of Things (IoT) devices more generally.
10 Years of Fair Representations: Challenges and Opportunities
Jul 04, 2024Fair Representation Learning (FRL) is a broad set of techniques, mostly based on neural networks, that seeks to learn new representations of data in which sensitive or undesired information has been removed. Methodologically, FRL was pioneered by Richard Zemel et al. about ten years ago. The basic concepts, objectives and evaluation strategies for FRL methodologies remain unchanged to this day. In this paper, we look back at the first ten years of FRL by i) revisiting its theoretical standing in light of recent work in deep learning theory that shows the hardness of removing information in neural network representations and ii) presenting the results of a massive experimentation (225.000 model fits and 110.000 AutoML fits) we conducted with the objective of improving on the common evaluation scenario for FRL. More specifically, we use automated machine learning (AutoML) to adversarially "mine" sensitive information from supposedly fair representations. Our theoretical and experimental analysis suggests that deterministic, unquantized FRL methodologies have serious issues in removing sensitive information, which is especially troubling as they might seem "fair" at first glance.
Can machine learning solve the challenge of adaptive learning and the individualization of learning paths? A field experiment in an online learning platform
Jul 03, 2024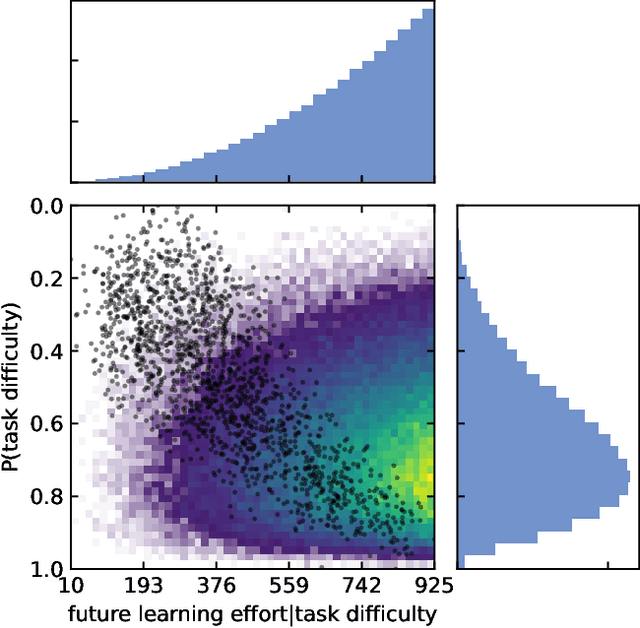


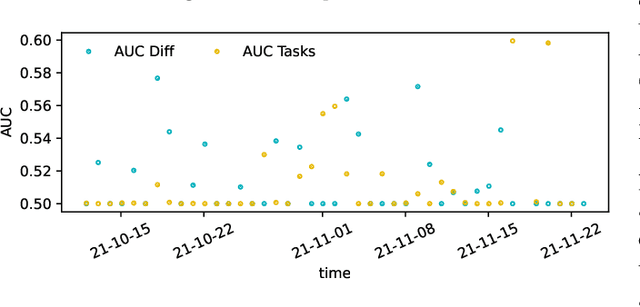
The individualization of learning contents based on digital technologies promises large individual and social benefits. However, it remains an open question how this individualization can be implemented. To tackle this question we conduct a randomized controlled trial on a large digital self-learning platform. We develop an algorithm based on two convolutional neural networks that assigns tasks to $4,365$ learners according to their learning paths. Learners are randomized into three groups: two treatment groups -- a group-based adaptive treatment group and an individual adaptive treatment group -- and one control group. We analyze the difference between the three groups with respect to effort learners provide and their performance on the platform. Our null results shed light on the multiple challenges associated with the individualization of learning paths.
Invariant Representations with Stochastically Quantized Neural Networks
Aug 04, 2022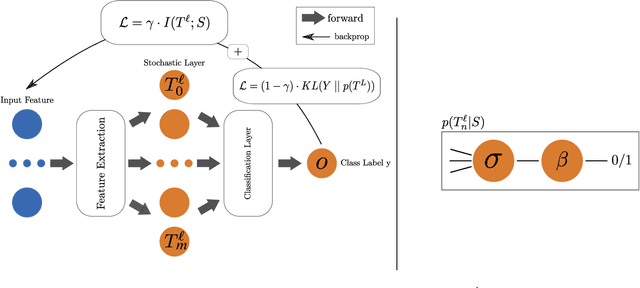
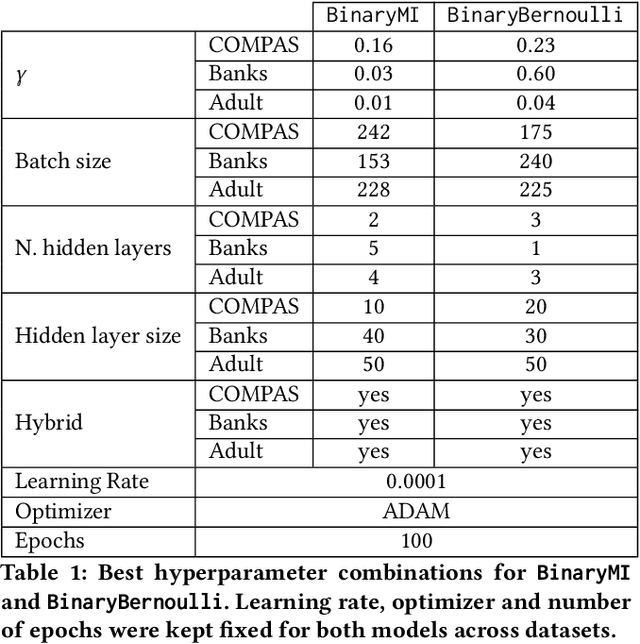
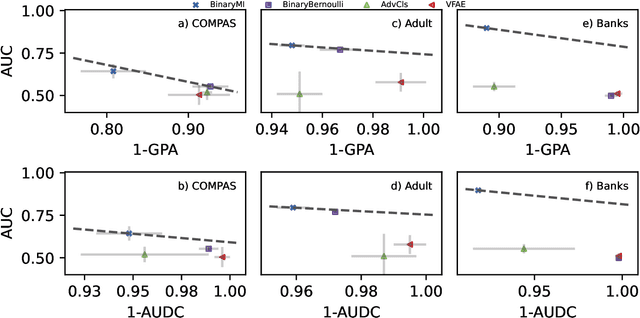

Representation learning algorithms offer the opportunity to learn invariant representations of the input data with regard to nuisance factors. Many authors have leveraged such strategies to learn fair representations, i.e., vectors where information about sensitive attributes is removed. These methods are attractive as they may be interpreted as minimizing the mutual information between a neural layer's activations and a sensitive attribute. However, the theoretical grounding of such methods relies either on the computation of infinitely accurate adversaries or on minimizing a variational upper bound of a mutual information estimate. In this paper, we propose a methodology for direct computation of the mutual information between a neural layer and a sensitive attribute. We employ stochastically-activated binary neural networks, which lets us treat neurons as random variables. We are then able to compute (not bound) the mutual information between a layer and a sensitive attribute and use this information as a regularization factor during gradient descent. We show that this method compares favorably with the state of the art in fair representation learning and that the learned representations display a higher level of invariance compared to full-precision neural networks.
Fair Interpretable Representation Learning with Correction Vectors
Feb 07, 2022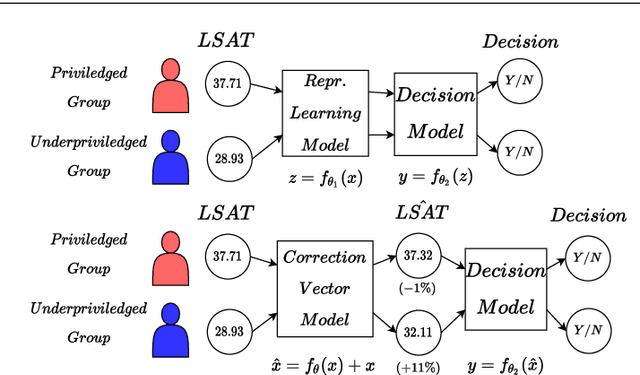
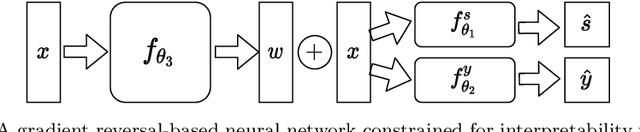
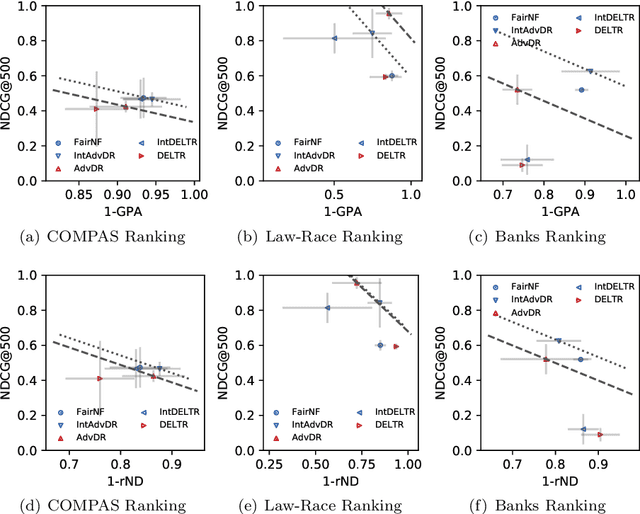
Neural network architectures have been extensively employed in the fair representation learning setting, where the objective is to learn a new representation for a given vector which is independent of sensitive information. Various representation debiasing techniques have been proposed in the literature. However, as neural networks are inherently opaque, these methods are hard to comprehend, which limits their usefulness. We propose a new framework for fair representation learning that is centered around the learning of "correction vectors", which have the same dimensionality as the given data vectors. Correction vectors may be computed either explicitly via architectural constraints or implicitly by training an invertible model based on Normalizing Flows. We show experimentally that several fair representation learning models constrained in such a way do not exhibit losses in ranking or classification performance. Furthermore, we demonstrate that state-of-the-art results can be achieved by the invertible model. Finally, we discuss the law standing of our methodology in light of recent legislation in the European Union.
Fair Interpretable Learning via Correction Vectors
Jan 17, 2022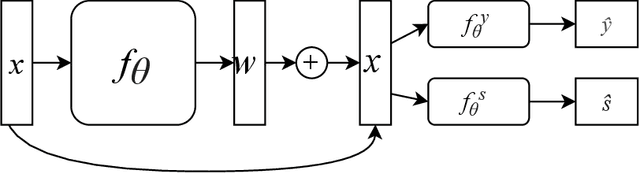
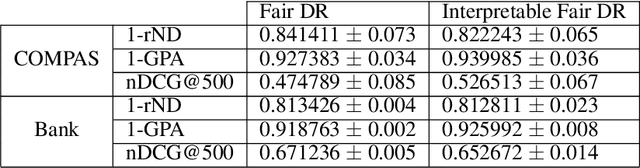

Neural network architectures have been extensively employed in the fair representation learning setting, where the objective is to learn a new representation for a given vector which is independent of sensitive information. Various "representation debiasing" techniques have been proposed in the literature. However, as neural networks are inherently opaque, these methods are hard to comprehend, which limits their usefulness. We propose a new framework for fair representation learning which is centered around the learning of "correction vectors", which have the same dimensionality as the given data vectors. The corrections are then simply summed up to the original features, and can therefore be analyzed as an explicit penalty or bonus to each feature. We show experimentally that a fair representation learning problem constrained in such a way does not impact performance.
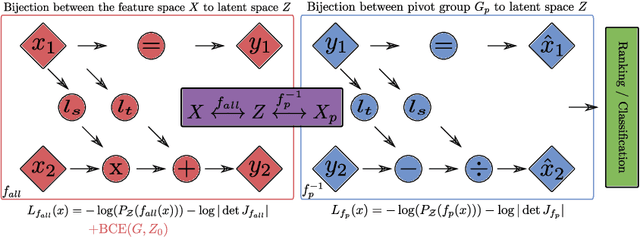
Fair Group-Shared Representations with Normalizing Flows
Jan 17, 2022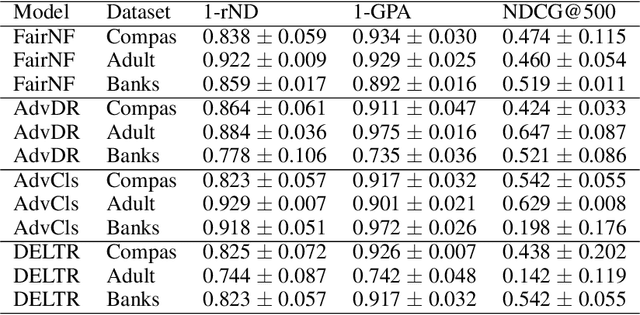
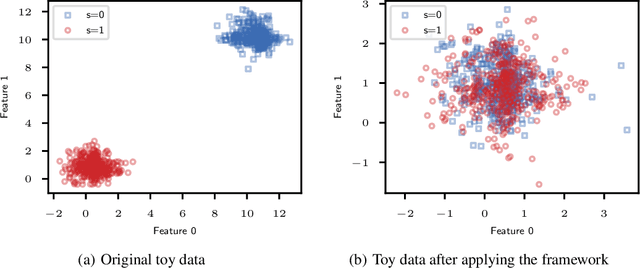

The issue of fairness in machine learning stems from the fact that historical data often displays biases against specific groups of people which have been underprivileged in the recent past, or still are. In this context, one of the possible approaches is to employ fair representation learning algorithms which are able to remove biases from data, making groups statistically indistinguishable. In this paper, we instead develop a fair representation learning algorithm which is able to map individuals belonging to different groups in a single group. This is made possible by training a pair of Normalizing Flow models and constraining them to not remove information about the ground truth by training a ranking or classification model on top of them. The overall, ``chained'' model is invertible and has a tractable Jacobian, which allows to relate together the probability densities for different groups and ``translate'' individuals from one group to another. We show experimentally that our methodology is competitive with other fair representation learning algorithms. Furthermore, our algorithm achieves stronger invariance w.r.t. the sensitive attribute.
Ranking Creative Language Characteristics in Small Data Scenarios
Oct 23, 2020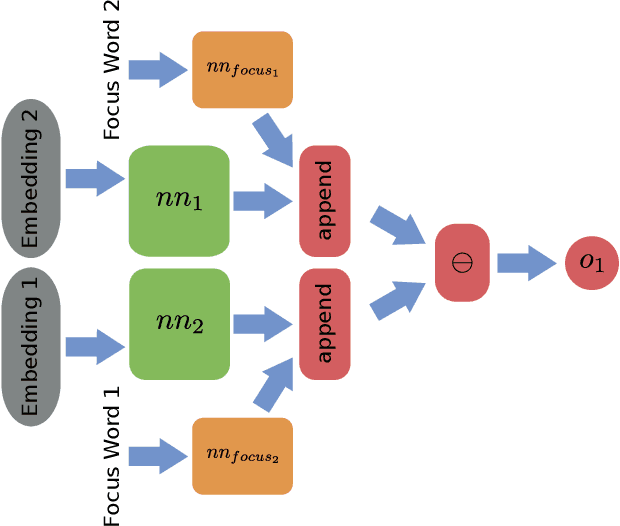
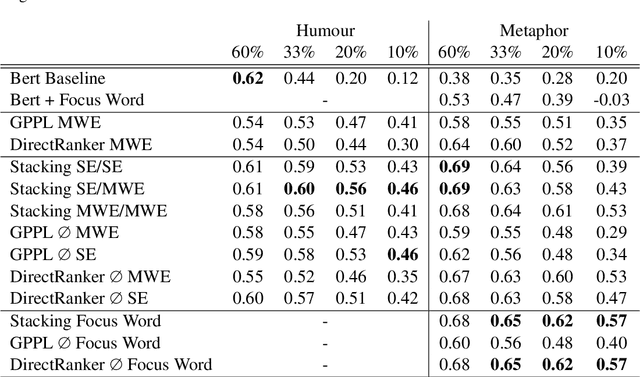
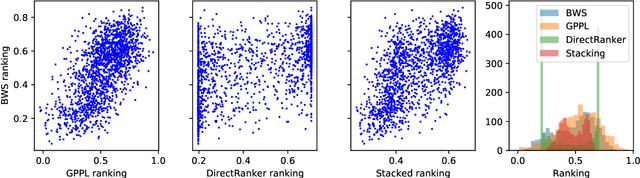
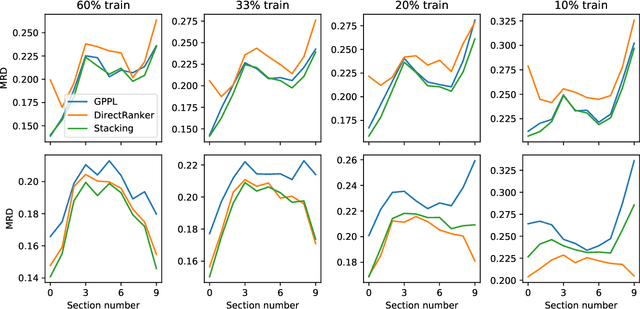
The ability to rank creative natural language provides an important general tool for downstream language understanding and generation. However, current deep ranking models require substantial amounts of labeled data that are difficult and expensive to obtain for different domains, languages and creative characteristics. A recent neural approach, the DirectRanker, promises to reduce the amount of training data needed but its application to text isn't fully explored. We therefore adapt the DirectRanker to provide a new deep model for ranking creative language with small data. We compare DirectRanker with a Bayesian approach, Gaussian process preference learning (GPPL), which has previously been shown to work well with sparse data. Our experiments with sparse training data show that while the performance of standard neural ranking approaches collapses with small training datasets, DirectRanker remains effective. We find that combining DirectRanker with GPPL increases performance across different settings by leveraging the complementary benefits of both models. Our combined approach outperforms the previous state-of-the-art on humor and metaphor novelty tasks, increasing Spearman's $\rho$ by 14% and 16% on average.
Pairwise Learning to Rank by Neural Networks Revisited: Reconstruction, Theoretical Analysis and Practical Performance
Sep 06, 2019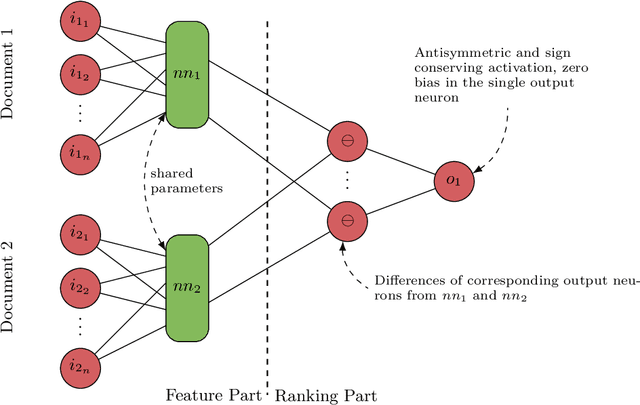
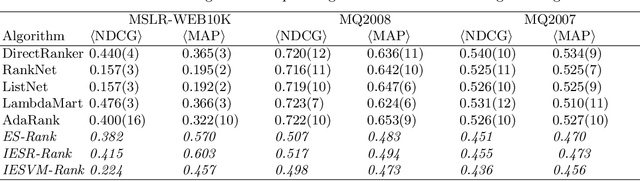
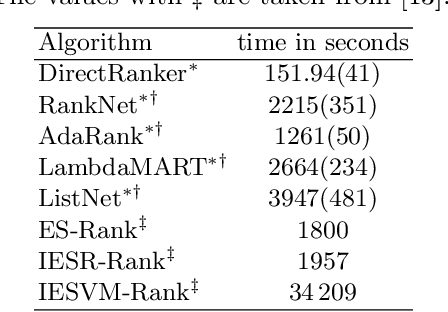
We present a pairwise learning to rank approach based on a neural net, called DirectRanker, that generalizes the RankNet architecture. We show mathematically that our model is reflexive, antisymmetric, and transitive allowing for simplified training and improved performance. Experimental results on the LETOR MSLR-WEB10K, MQ2007 and MQ2008 datasets show that our model outperforms numerous state-of-the-art methods, while being inherently simpler in structure and using a pairwise approach only.