 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Binary Attention: An Energy-Efficient Fusion Framework for Audio-Visual Learning
Jan 31, 2026Effective multimodal fusion requires mechanisms that can capture complex cross-modal dependencies while remaining computationally scalable for real-world deployment. Existing audio-visual fusion approaches face a fundamental trade-off: attention-based methods effectively model cross-modal relationships but incur quadratic computational complexity that prevents hierarchical, multi-scale architectures, while efficient fusion strategies rely on simplistic concatenation that fails to extract complementary cross-modal information. We introduce CMQKA, a novel cross-modal fusion mechanism that achieves linear O(N) complexity through efficient binary operations, enabling scalable hierarchical fusion previously infeasible with conventional attention. CMQKA employs bidirectional cross-modal Query-Key attention to extract complementary spatiotemporal features and uses learnable residual fusion to preserve modality-specific characteristics while enriching representations with cross-modal information. Building upon CMQKA, we present SNNergy, an energy-efficient multimodal fusion framework with a hierarchical architecture that processes inputs through progressively decreasing spatial resolutions and increasing semantic abstraction. This multi-scale fusion capability allows the framework to capture both local patterns and global context across modalities. Implemented with event-driven binary spike operations, SNNergy achieves remarkable energy efficiency while maintaining fusion effectiveness and establishing new state-of-the-art results on challenging audio-visual benchmarks, including CREMA-D, AVE, and UrbanSound8K-AV, significantly outperforming existing multimodal fusion baselines. Our framework advances multimodal fusion by introducing a scalable fusion mechanism that enables hierarchical cross-modal integration with practical energy efficiency for real-world audio-visual intelligence systems.
Learning from the Right Patches: A Two-Stage Wavelet-Driven Masked Autoencoder for Histopathology Representation Learning
Nov 19, 2025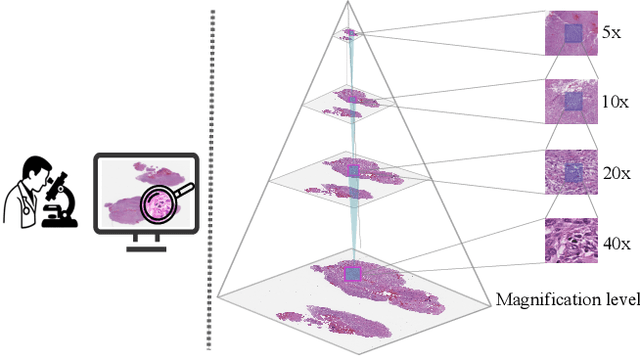
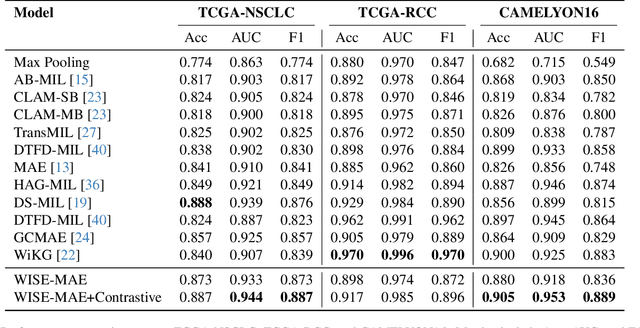
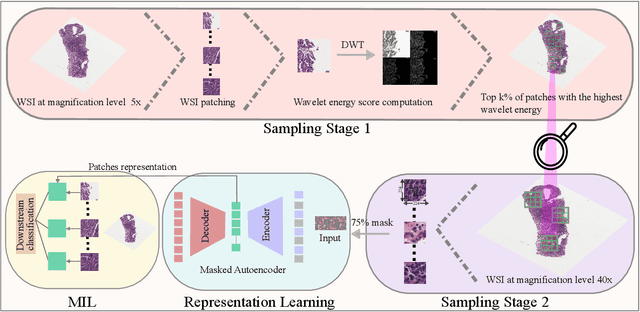
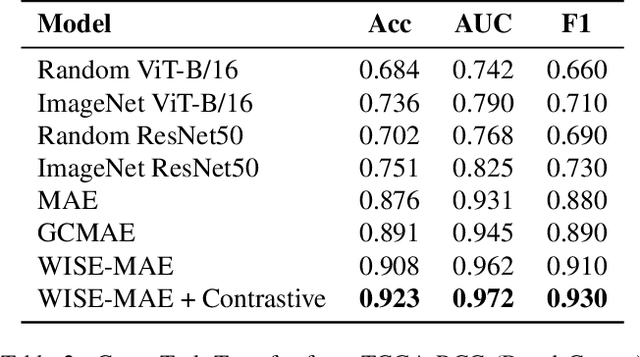
Whole-slide images are central to digital pathology, yet their extreme size and scarce annotations make self-supervised learning essential. Masked Autoencoders (MAEs) with Vision Transformer backbones have recently shown strong potential for histopathology representation learning. However, conventional random patch sampling during MAE pretraining often includes irrelevant or noisy regions, limiting the model's ability to capture meaningful tissue patterns. In this paper, we present a lightweight and domain-adapted framework that brings structure and biological relevance into MAE-based learning through a wavelet-informed patch selection strategy. WISE-MAE applies a two-step coarse-to-fine process: wavelet-based screening at low magnification to locate structurally rich regions, followed by high-resolution extraction for detailed modeling. This approach mirrors the diagnostic workflow of pathologists and improves the quality of learned representations. Evaluations across multiple cancer datasets, including lung, renal, and colorectal tissues, show that WISE-MAE achieves competitive representation quality and downstream classification performance while maintaining efficiency under weak supervision.
OpenReviewer: A Specialized Large Language Model for Generating Critical Scientific Paper Reviews
Dec 16, 2024



We present OpenReviewer, an open-source system for generating high-quality peer reviews of machine learning and AI conference papers. At its core is Llama-OpenReviewer-8B, an 8B parameter language model specifically fine-tuned on 79,000 expert reviews from top ML conferences. Given a PDF paper submission and review template as input, OpenReviewer extracts the full text, including technical content like equations and tables, and generates a structured review following conference-specific guidelines. Our evaluation on 400 test papers shows that OpenReviewer produces significantly more critical and realistic reviews compared to general-purpose LLMs like GPT-4 and Claude-3.5. While other LLMs tend toward overly positive assessments, OpenReviewer's recommendations closely match the distribution of human reviewer ratings. The system provides authors with rapid, constructive feedback to improve their manuscripts before submission, though it is not intended to replace human peer review. OpenReviewer is available as an online demo and open-source tool.
DAMMI:Daily Activities in a Psychologically Annotated Multi-Modal IoT dataset
Oct 05, 2024The growth in the elderly population and the shift in the age pyramid have increased the demand for healthcare and well-being services. To address this concern, alongside the rising cost of medical care, the concept of ageing at home has emerged, driven by recent advances in medical and technological solutions. Experts in computer science, communication technology, and healthcare have collaborated to develop affordable health solutions by employing sensors in living environments, wearable devices, and smartphones, in association with advanced data mining and intelligent systems with learning capabilities, to monitor, analyze, and predict the health status of elderly individuals. However, implementing intelligent healthcare systems and developing analytical techniques requires testing and evaluating algorithms on real-world data. Despite the need, there is a shortage of publicly available datasets that meet these requirements. To address this gap, we present the DAMMI dataset in this work, designed to support researchers in the field. The dataset includes daily activity data of an elderly individual collected via home-installed sensors, smartphone data, and a wristband over 146 days. It also contains daily psychological reports provided by a team of psychologists. Furthermore, the data collection spans significant events such as the COVID-19 pandemic, New Year's holidays, and the religious month of Ramadan, offering additional opportunities for analysis. In this paper, we outline detailed information about the data collection system, the types of data recorded, and pre-processed event logs. This dataset is intended to assist professionals in IoT and data mining in evaluating and implementing their research ideas.
LLM-based event abstraction and integration for IoT-sourced logs
Sep 05, 2024The continuous flow of data collected by Internet of Things (IoT) devices, has revolutionised our ability to understand and interact with the world across various applications. However, this data must be prepared and transformed into event data before analysis can begin. In this paper, we shed light on the potential of leveraging Large Language Models (LLMs) in event abstraction and integration. Our approach aims to create event records from raw sensor readings and merge the logs from multiple IoT sources into a single event log suitable for further Process Mining applications. We demonstrate the capabilities of LLMs in event abstraction considering a case study for IoT application in elderly care and longitudinal health monitoring. The results, showing on average an accuracy of 90% in detecting high-level activities. These results highlight LLMs' promising potential in addressing event abstraction and integration challenges, effectively bridging the existing gap.
Towards Precision Healthcare: Robust Fusion of Time Series and Image Data
May 24, 2024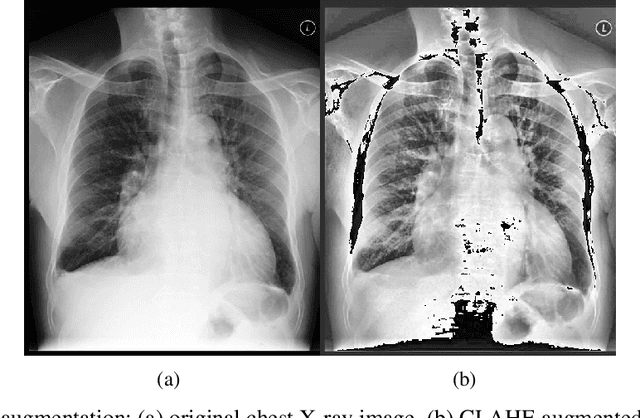
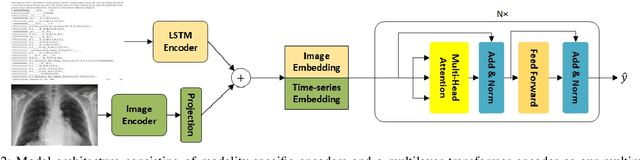
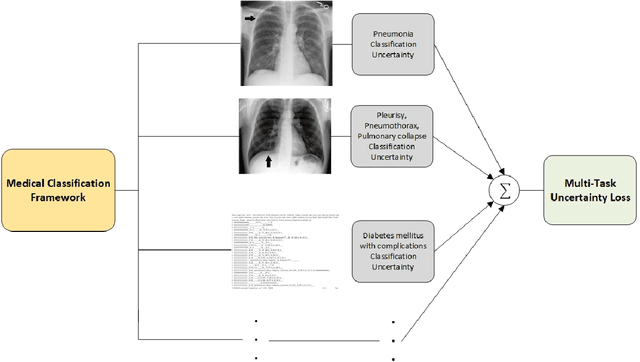
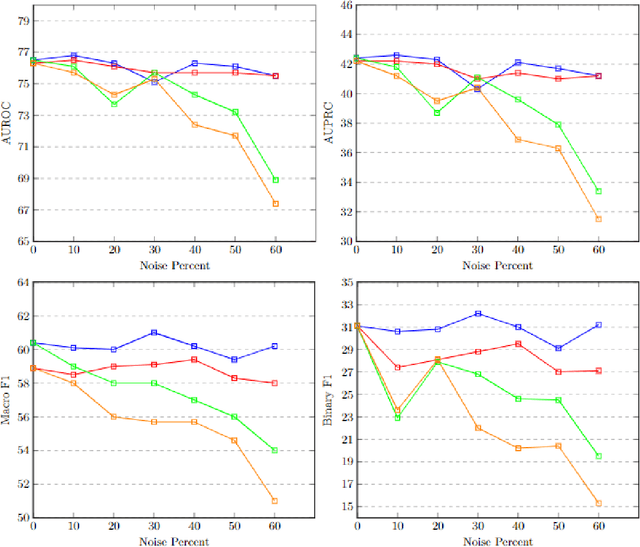
With the increasing availability of diverse data types, particularly images and time series data from medical experiments, there is a growing demand for techniques designed to combine various modalities of data effectively. Our motivation comes from the important areas of predicting mortality and phenotyping where using different modalities of data could significantly improve our ability to predict. To tackle this challenge, we introduce a new method that uses two separate encoders, one for each type of data, allowing the model to understand complex patterns in both visual and time-based information. Apart from the technical challenges, our goal is to make the predictive model more robust in noisy conditions and perform better than current methods. We also deal with imbalanced datasets and use an uncertainty loss function, yielding improved results while simultaneously providing a principled means of modeling uncertainty. Additionally, we include attention mechanisms to fuse different modalities, allowing the model to focus on what's important for each task. We tested our approach using the comprehensive multimodal MIMIC dataset, combining MIMIC-IV and MIMIC-CXR datasets. Our experiments show that our method is effective in improving multimodal deep learning for clinical applications. The code will be made available online.
MTS2Graph: Interpretable Multivariate Time Series Classification with Temporal Evolving Graphs
Jun 06, 2023Conventional time series classification approaches based on bags of patterns or shapelets face significant challenges in dealing with a vast amount of feature candidates from high-dimensional multivariate data. In contrast, deep neural networks can learn low-dimensional features efficiently, and in particular, Convolutional Neural Networks (CNN) have shown promising results in classifying Multivariate Time Series (MTS) data. A key factor in the success of deep neural networks is this astonishing expressive power. However, this power comes at the cost of complex, black-boxed models, conflicting with the goals of building reliable and human-understandable models. An essential criterion in understanding such predictive deep models involves quantifying the contribution of time-varying input variables to the classification. Hence, in this work, we introduce a new framework for interpreting multivariate time series data by extracting and clustering the input representative patterns that highly activate CNN neurons. This way, we identify each signal's role and dependencies, considering all possible combinations of signals in the MTS input. Then, we construct a graph that captures the temporal relationship between the extracted patterns for each layer. An effective graph merging strategy finds the connection of each node to the previous layer's nodes. Finally, a graph embedding algorithm generates new representations of the created interpretable time-series features. To evaluate the performance of our proposed framework, we run extensive experiments on eight datasets of the UCR/UEA archive, along with HAR and PAM datasets. The experiments indicate the benefit of our time-aware graph-based representation in MTS classification while enriching them with more interpretability.
MANDO: Multi-Level Heterogeneous Graph Embeddings for Fine-Grained Detection of Smart Contract Vulnerabilities
Aug 28, 2022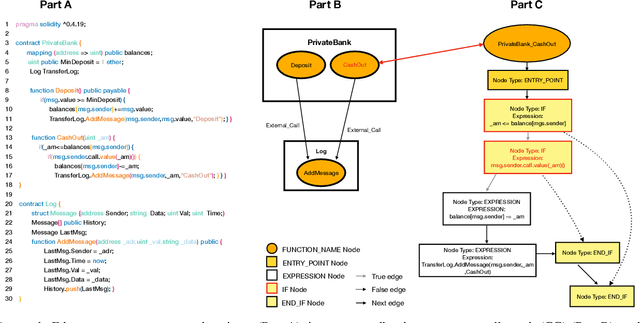
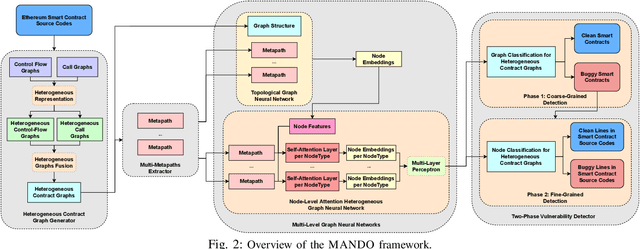
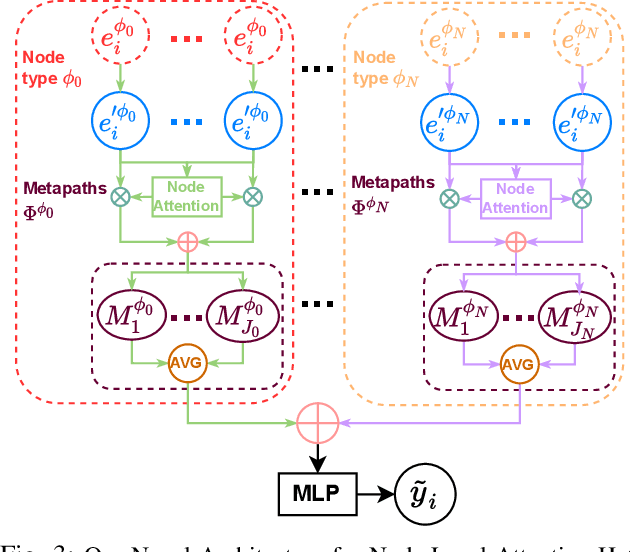

Learning heterogeneous graphs consisting of different types of nodes and edges enhances the results of homogeneous graph techniques. An interesting example of such graphs is control-flow graphs representing possible software code execution flows. As such graphs represent more semantic information of code, developing techniques and tools for such graphs can be highly beneficial for detecting vulnerabilities in software for its reliability. However, existing heterogeneous graph techniques are still insufficient in handling complex graphs where the number of different types of nodes and edges is large and variable. This paper concentrates on the Ethereum smart contracts as a sample of software codes represented by heterogeneous contract graphs built upon both control-flow graphs and call graphs containing different types of nodes and links. We propose MANDO, a new heterogeneous graph representation to learn such heterogeneous contract graphs' structures. MANDO extracts customized metapaths, which compose relational connections between different types of nodes and their neighbors. Moreover, it develops a multi-metapath heterogeneous graph attention network to learn multi-level embeddings of different types of nodes and their metapaths in the heterogeneous contract graphs, which can capture the code semantics of smart contracts more accurately and facilitate both fine-grained line-level and coarse-grained contract-level vulnerability detection. Our extensive evaluation of large smart contract datasets shows that MANDO improves the vulnerability detection results of other techniques at the coarse-grained contract level. More importantly, it is the first learning-based approach capable of identifying vulnerabilities at the fine-grained line-level, and significantly improves the traditional code analysis-based vulnerability detection approaches by 11.35% to 70.81% in terms of F1-score.
Focusing Knowledge-based Graph Argument Mining via Topic Modeling
Feb 03, 2021
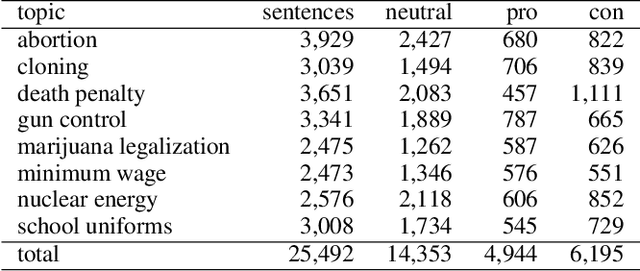
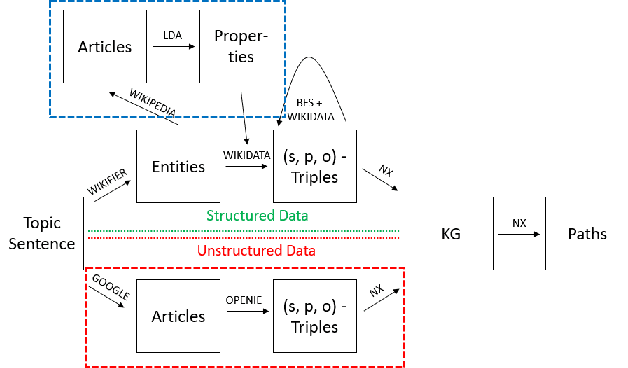

Decision-making usually takes five steps: identifying the problem, collecting data, extracting evidence, identifying pro and con arguments, and making decisions. Focusing on extracting evidence, this paper presents a hybrid model that combines latent Dirichlet allocation and word embeddings to obtain external knowledge from structured and unstructured data. We study the task of sentence-level argument mining, as arguments mostly require some degree of world knowledge to be identified and understood. Given a topic and a sentence, the goal is to classify whether a sentence represents an argument in regard to the topic. We use a topic model to extract topic- and sentence-specific evidence from the structured knowledge base Wikidata, building a graph based on the cosine similarity between the entity word vectors of Wikidata and the vector of the given sentence. Also, we build a second graph based on topic-specific articles found via Google to tackle the general incompleteness of structured knowledge bases. Combining these graphs, we obtain a graph-based model which, as our evaluation shows, successfully capitalizes on both structured and unstructured data.
Rule Extraction from Binary Neural Networks with Convolutional Rules for Model Validation
Dec 15, 2020
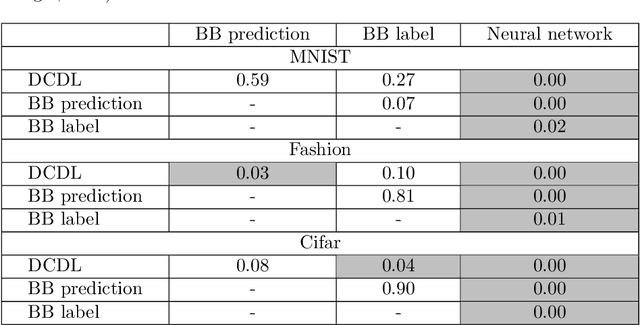
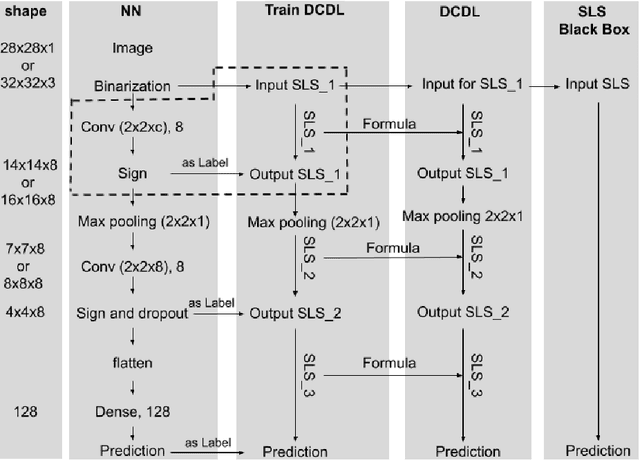
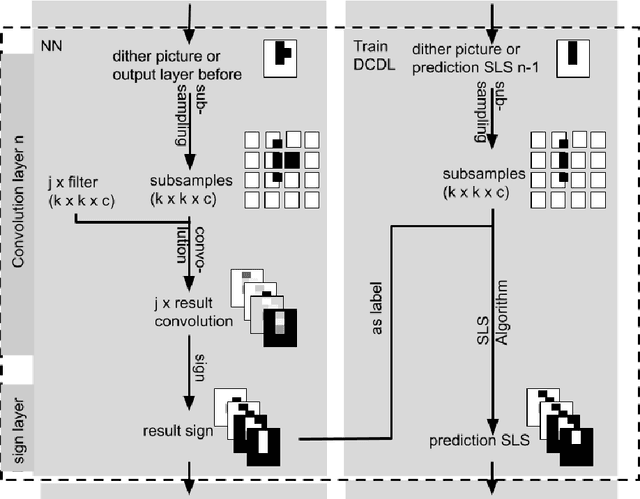
Most deep neural networks are considered to be black boxes, meaning their output is hard to interpret. In contrast, logical expressions are considered to be more comprehensible since they use symbols that are semantically close to natural language instead of distributed representations. However, for high-dimensional input data such as images, the individual symbols, i.e. pixels, are not easily interpretable. We introduce the concept of first-order convolutional rules, which are logical rules that can be extracted using a convolutional neural network (CNN), and whose complexity depends on the size of the convolutional filter and not on the dimensionality of the input. Our approach is based on rule extraction from binary neural networks with stochastic local search. We show how to extract rules that are not necessarily short, but characteristic of the input, and easy to visualize. Our experiments show that the proposed approach is able to model the functionality of the neural network while at the same time producing interpretable logical rules.