 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precision Healthcare: Robust Fusion of Time Series and Image Data
May 24, 2024
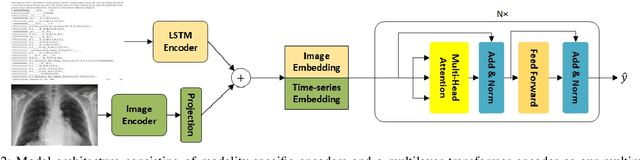
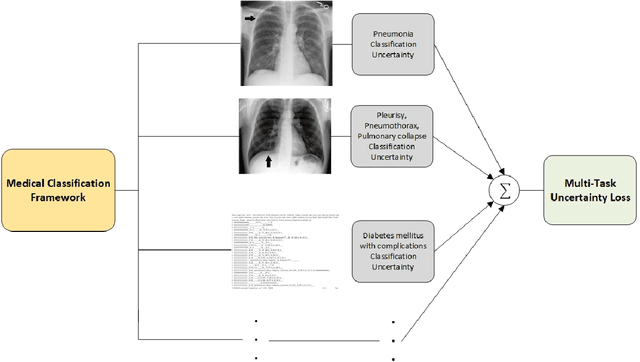
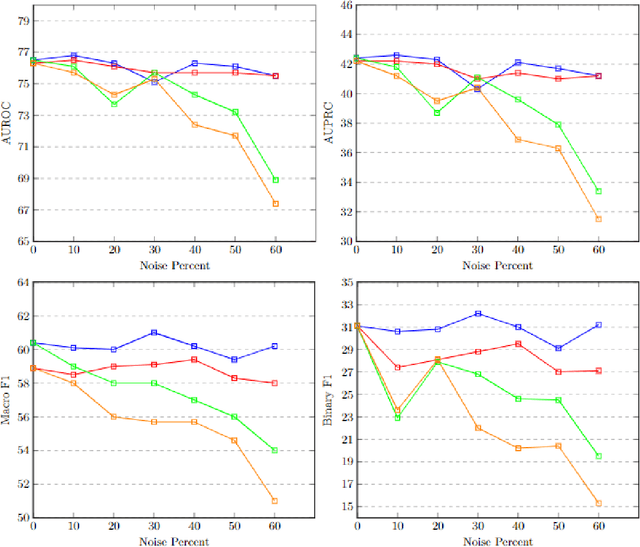
With the increasing availability of diverse data types, particularly images and time series data from medical experiments, there is a growing demand for techniques designed to combine various modalities of data effectively. Our motivation comes from the important areas of predicting mortality and phenotyping where using different modalities of data could significantly improve our ability to predict. To tackle this challenge, we introduce a new method that uses two separate encoders, one for each type of data, allowing the model to understand complex patterns in both visual and time-based information. Apart from the technical challenges, our goal is to make the predictive model more robust in noisy conditions and perform better than current methods. We also deal with imbalanced datasets and use an uncertainty loss function, yielding improved results while simultaneously providing a principled means of modeling uncertainty. Additionally, we include attention mechanisms to fuse different modalities, allowing the model to focus on what's important for each task. We tested our approach using the comprehensive multimodal MIMIC dataset, combining MIMIC-IV and MIMIC-CXR datasets. Our experiments show that our method is effective in improving multimodal deep learning for clinical applications. The code will be made available online.