 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgepropella-1: Multi-Property Document Annotation for LLM Data Curation at Scale
Feb 12, 2026Since FineWeb-Edu, data curation for LLM pretraining has predominantly relied on single scalar quality scores produced by small classifiers. A single score conflates multiple quality dimensions, prevents flexible filtering, and offers no interpretability. We introduce propella-1, a family of small multilingual LLMs (0.6B, 1.7B, 4B parameters) that annotate text documents across 18 properties organized into six categories: core content, classification, quality and value, audience and purpose, safety and compliance, and geographic relevance. The models support 57 languages and produce structured JSON annotations conforming to a predefined schema. Evaluated against a frontier commercial LLM as a reference annotator, the 4B model achieves higher agreement than much larger general-purpose models. We release propella-annotations, a dataset of over three billion document annotations covering major pretraining corpora including data from FineWeb-2, FinePDFs, HPLT 3.0, and Nemotron-CC. Using these annotations, we present a multi-dimensional compositional analysis of widely used pretraining datasets, revealing substantial differences in quality, reasoning depth, and content composition that single-score approaches cannot capture. All model weights and annotations are released under permissive, commercial-use licenses.
sui-1: Grounded and Verifiable Long-Form Summarization
Jan 13, 2026Large language models frequently generate plausible but unfaithful summaries that users cannot verify against source text, a critical limitation in compliance-sensitive domains such as government and legal analysis. We present sui-1, a 24B parameter model that produces abstractive summaries with inline citations, enabling users to trace each claim to its source sentence. Our synthetic data pipeline combines chain-of-thought prompting with multi-stage verification, generating over 22,000 high-quality training examples across five languages from diverse sources including parliamentary documents, web text, and Wikipedia. Evaluation shows sui-1 significantly outperforms all tested open-weight baselines, including models with 3x more parameters. These results demonstrate that task-specific training substantially outperforms scale alone for citation-grounded summarization. Model weights and an interactive demo are publicly available.
OpenReviewer: A Specialized Large Language Model for Generating Critical Scientific Paper Reviews
Dec 16, 2024



We present OpenReviewer, an open-source system for generating high-quality peer reviews of machine learning and AI conference papers. At its core is Llama-OpenReviewer-8B, an 8B parameter language model specifically fine-tuned on 79,000 expert reviews from top ML conferences. Given a PDF paper submission and review template as input, OpenReviewer extracts the full text, including technical content like equations and tables, and generates a structured review following conference-specific guidelines. Our evaluation on 400 test papers shows that OpenReviewer produces significantly more critical and realistic reviews compared to general-purpose LLMs like GPT-4 and Claude-3.5. While other LLMs tend toward overly positive assessments, OpenReviewer's recommendations closely match the distribution of human reviewer ratings. The system provides authors with rapid, constructive feedback to improve their manuscripts before submission, though it is not intended to replace human peer review. OpenReviewer is available as an online demo and open-source tool.
Explainable Information Retrieval: A Survey
Nov 04, 2022Explainable information retrieval is an emerging research area aiming to make transparent and trustworthy information retrieval systems. Given the increasing use of complex machine learning models in search systems, explainability is essential in building and auditing responsible information retrieval models. This survey fills a vital gap in the otherwise topically diverse literature of explainable information retrieval. It categorizes and discusses recent explainability methods developed for different application domains in information retrieval, providing a common framework and unifying perspectives. In addition, it reflects on the common concern of evaluating explanations and highlights open challenges and opportunities.
Towards Benchmarking the Utility of Explanations for Model Debugging
May 10, 2021
Post-hoc explanation methods are an important class of approaches that help understand the rationale underlying a trained model's decision. But how useful are they for an end-user towards accomplishing a given task? In this vision paper, we argue the need for a benchmark to facilitate evaluations of the utility of post-hoc explanation methods. As a first step to this end, we enumerate desirable properties that such a benchmark should possess for the task of debugging text classifiers. Additionally, we highlight that such a benchmark facilitates not only assessing the effectiveness of explanations but also their efficiency.
Multimodal Analytics for Real-world News using Measures of Cross-modal Entity Consistency
Mar 23, 2020
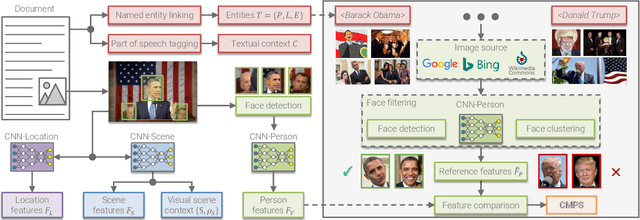

The World Wide Web has become a popular source for gathering information and news. Multimodal information, e.g., enriching text with photos, is typically used to convey the news more effectively or to attract attention. Photo content can range from decorative, depict additional important information, or can even contain misleading information. Therefore, automatic approaches to quantify cross-modal consistency of entity representation can support human assessors to evaluate the overall multimodal message, for instance, with regard to bias or sentiment. In some cases such measures could give hints to detect fake news, which is an increasingly important topic in today's society. In this paper, we introduce a novel task of cross-modal consistency verification in real-world news and present a multimodal approach to quantify the entity coherence between image and text. Named entity linking is applied to extract persons, locations, and events from news texts. Several measures are suggested to calculate cross-modal similarity for these entities using state of the art approaches. In contrast to previous work, our system automatically gathers example data from the Web and is applicable to real-world news. Results on two novel datasets that cover different languages, topics, and domains demonstrate the feasibility of our approach. Datasets and code are publicly available to foster research towards this new direction.
Finding Interpretable Concept Spaces in Node Embeddings using Knowledge Bases
Oct 11, 2019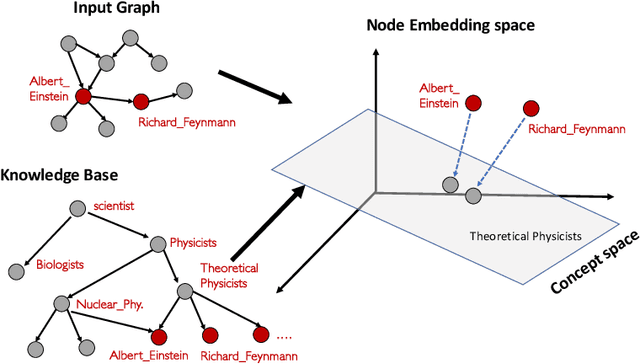
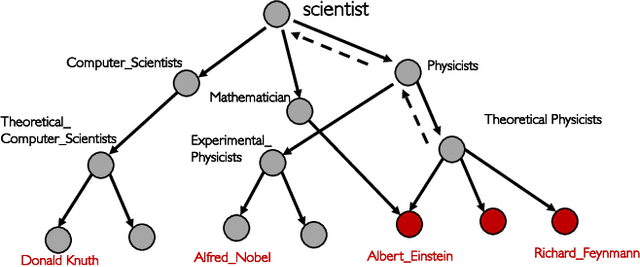
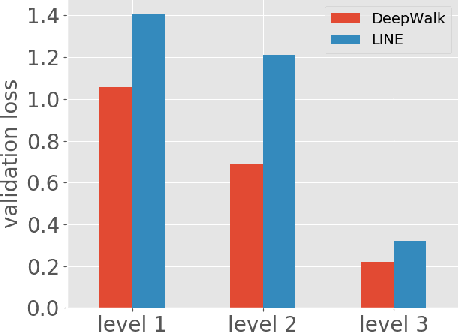
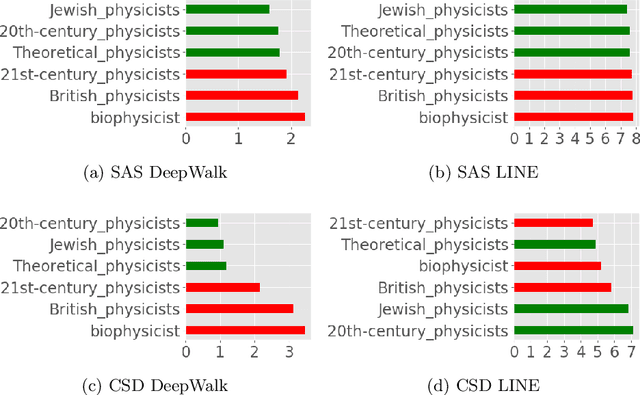
In this paper we propose and study the novel problem of explaining node embeddings by finding embedded human interpretable subspaces in already trained unsupervised node representation embeddings. We use an external knowledge base that is organized as a taxonomy of human-understandable concepts over entities as a guide to identify subspaces in node embeddings learned from an entity graph derived from Wikipedia. We propose a method that given a concept finds a linear transformation to a subspace where the structure of the concept is retained. Our initial experiments show that we obtain low error in finding fine-grained concepts.