 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Analytics for Real-world News using Measures of Cross-modal Entity Consistency
Mar 23, 2020
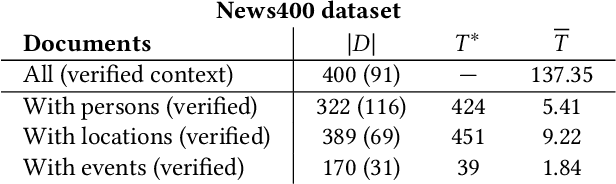
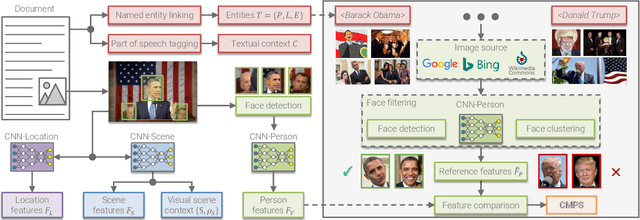

The World Wide Web has become a popular source for gathering information and news. Multimodal information, e.g., enriching text with photos, is typically used to convey the news more effectively or to attract attention. Photo content can range from decorative, depict additional important information, or can even contain misleading information. Therefore, automatic approaches to quantify cross-modal consistency of entity representation can support human assessors to evaluate the overall multimodal message, for instance, with regard to bias or sentiment. In some cases such measures could give hints to detect fake news, which is an increasingly important topic in today's society. In this paper, we introduce a novel task of cross-modal consistency verification in real-world news and present a multimodal approach to quantify the entity coherence between image and text. Named entity linking is applied to extract persons, locations, and events from news texts. Several measures are suggested to calculate cross-modal similarity for these entities using state of the art approaches. In contrast to previous work, our system automatically gathers example data from the Web and is applicable to real-world news. Results on two novel datasets that cover different languages, topics, and domains demonstrate the feasibility of our approach. Datasets and code are publicly available to foster research towards this new direction.
Finding Person Relations in Image Data of the Internet Archive
Jun 21, 2018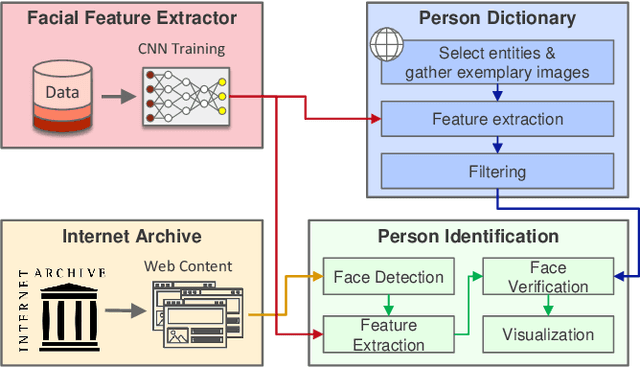

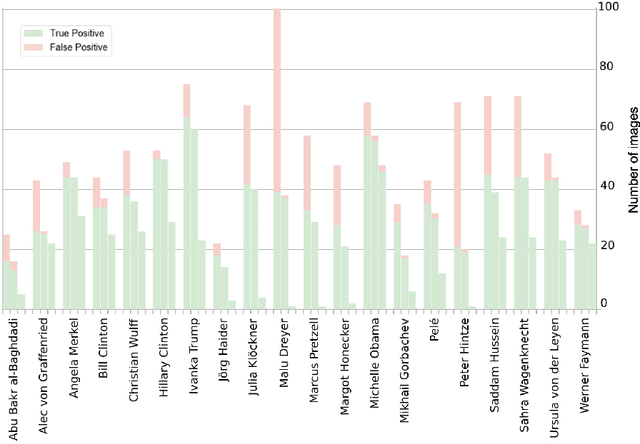
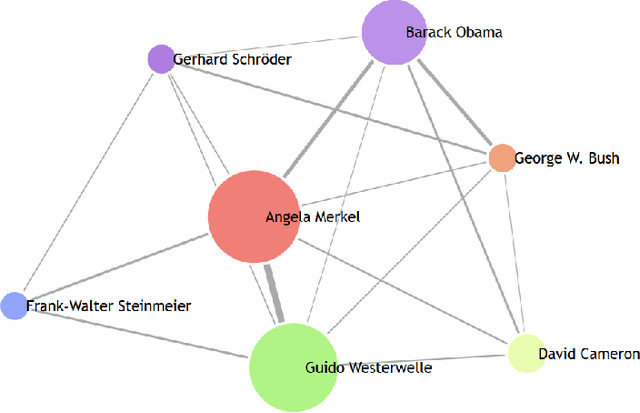
The multimedia content in the World Wide Web is rapidly growing and contains valuable information for many applications in different domains. For this reason, the Internet Archive initiative has been gathering billions of time-versioned web pages since the mid-nineties. However, the huge amount of data is rarely labeled with appropriate metadata and automatic approaches are required to enable semantic search. Normally, the textual content of the Internet Archive is used to extract entities and their possible relations across domains such as politics and entertainment, whereas image and video content is usually neglected. In this paper, we introduce a system for person recognition in image content of web news stored in the Internet Archive. Thus, the system complements entity recognition in text and allows researchers and analysts to track media coverage and relations of persons more precisely. Based on a deep learning face recognition approach, we suggest a system that automatically detects persons of interest and gathers sample material, which is subsequently used to identify them in the image data of the Internet Archive. We evaluate the performance of the face recognition system on an appropriate standard benchmark dataset and demonstrate the feasibility of the approach with two use cases.