 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020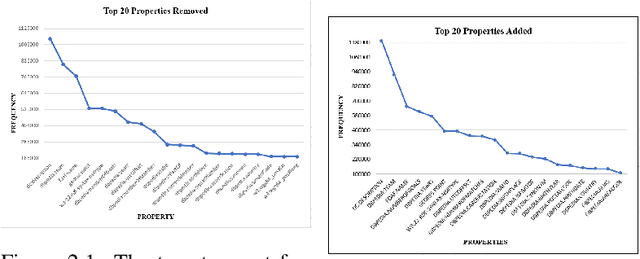
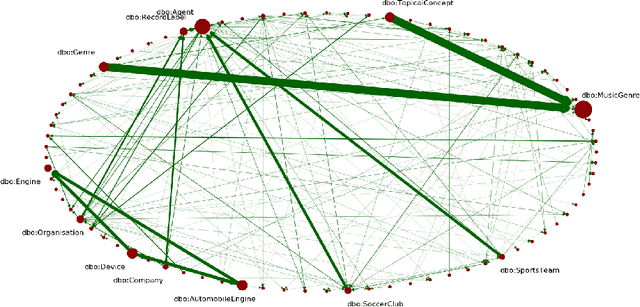

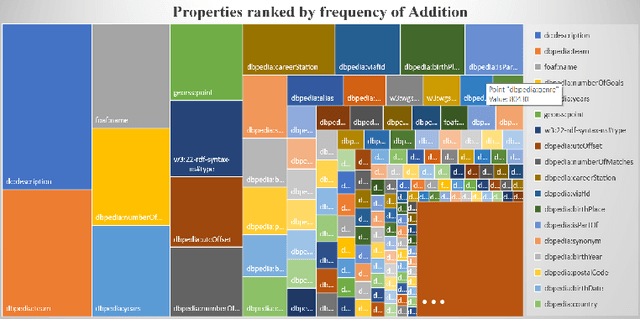
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
Investigating Correlations of Inter-coder Agreement and Machine Annotation Performance for Historical Video Data
Jul 24, 2019
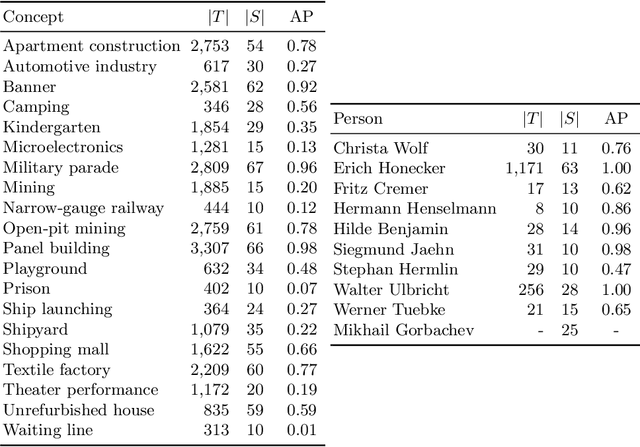
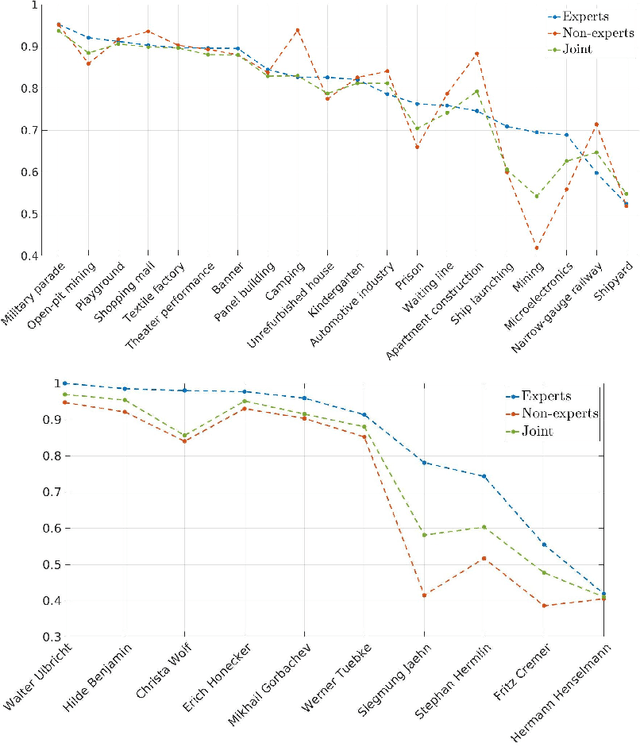
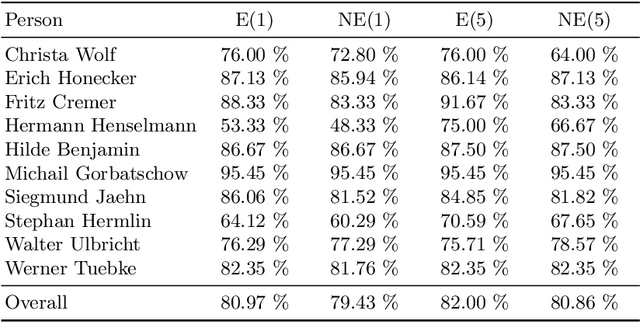
Video indexing approaches such as visual concept classification and person recognition are essential to enable fine-grained semantic search in large-scale video archives such as the historical video collection of former German Democratic Republic (GDR) maintained by the German Broadcasting Archive (DRA). Typically, a lexicon of visual concepts has to be defined for semantic search. However, the definition of visual concepts can be more or less subjective due to individually differing judgments of annotators, which may have an impact on annotation quality and subsequently training of supervised machine learning methods. In this paper, we analyze the inter-coder agreement for historical TV data of the former GDR for visual concept classification and person recognition. The inter-coder agreement is evaluated for a group of expert as well as non-expert annotators in order to determine differences in annotation homogeneity. Furthermore, correlations between visual recognition performance and inter-annotator agreement are measured. In this context, information about image quantity and agreement are used to predict average precision for concept classification. Finally, the influence of expert vs. non-expert annotations acquired in the study are used to evaluate person recognition.
Finding Person Relations in Image Data of the Internet Archive
Jun 21, 2018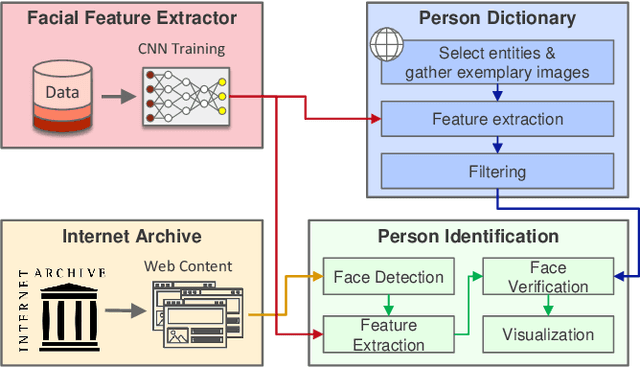

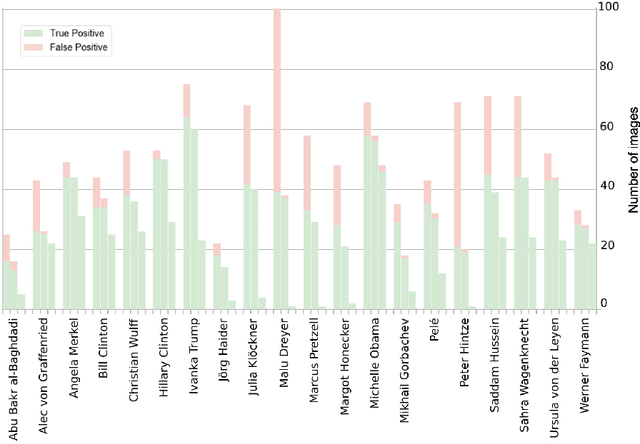
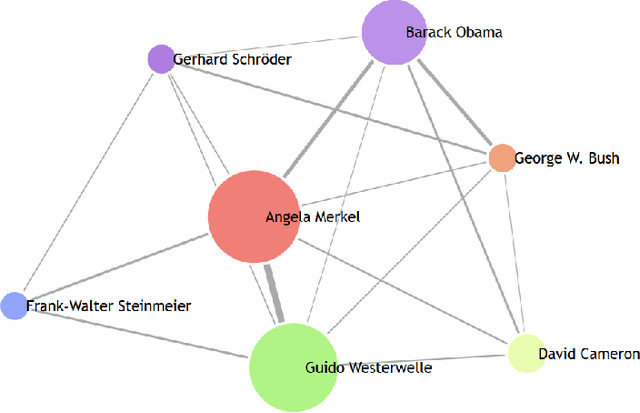
The multimedia content in the World Wide Web is rapidly growing and contains valuable information for many applications in different domains. For this reason, the Internet Archive initiative has been gathering billions of time-versioned web pages since the mid-nineties. However, the huge amount of data is rarely labeled with appropriate metadata and automatic approaches are required to enable semantic search. Normally, the textual content of the Internet Archive is used to extract entities and their possible relations across domains such as politics and entertainment, whereas image and video content is usually neglected. In this paper, we introduce a system for person recognition in image content of web news stored in the Internet Archive. Thus, the system complements entity recognition in text and allows researchers and analysts to track media coverage and relations of persons more precisely. Based on a deep learning face recognition approach, we suggest a system that automatically detects persons of interest and gathers sample material, which is subsequently used to identify them in the image data of the Internet Archive. We evaluate the performance of the face recognition system on an appropriate standard benchmark dataset and demonstrate the feasibility of the approach with two use cases.