 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Fake News Detection using Large Language Models under Adversarial Sentiment Attacks
Jan 21, 2026Misinformation and fake news have become a pressing societal challenge, driving the need for reliable automated detection methods. Prior research has highlighted sentiment as an important signal in fake news detection, either by analyzing which sentiments are associated with fake news or by using sentiment and emotion features for classification. However, this poses a vulnerability since adversaries can manipulate sentiment to evade detectors especially with the advent of large language models (LLMs). A few studies have explored adversarial samples generated by LLMs, but they mainly focus on stylistic features such as writing style of news publishers. Thus, the crucial vulnerability of sentiment manipulation remains largely unexplored. In this paper, we investigate the robustness of state-of-the-art fake news detectors under sentiment manipulation. We introduce AdSent, a sentiment-robust detection framework designed to ensure consistent veracity predictions across both original and sentiment-altered news articles. Specifically, we (1) propose controlled sentiment-based adversarial attacks using LLMs, (2) analyze the impact of sentiment shifts on detection performance. We show that changing the sentiment heavily impacts the performance of fake news detection models, indicating biases towards neutral articles being real, while non-neutral articles are often classified as fake content. (3) We introduce a novel sentiment-agnostic training strategy that enhances robustness against such perturbations. Extensive experiments on three benchmark datasets demonstrate that AdSent significantly outperforms competitive baselines in both accuracy and robustness, while also generalizing effectively to unseen datasets and adversarial scenarios.
Verifying Cross-modal Entity Consistency in News using Vision-language Models
Jan 20, 2025The web has become a crucial source of information, but it is also used to spread disinformation, often conveyed through multiple modalities like images and text. The identification of inconsistent cross-modal information, in particular entities such as persons, locations, and events, is critical to detect disinformation. Previous works either identify out-of-context disinformation by assessing the consistency of images to the whole document, neglecting relations of individual entities, or focus on generic entities that are not relevant to news. So far, only few approaches have addressed the task of validating entity consistency between images and text in news. However, the potential of large vision-language models (LVLMs) has not been explored yet. In this paper, we propose an LVLM-based framework for verifying Cross-modal Entity Consistency~(LVLM4CEC), to assess whether persons, locations and events in news articles are consistent across both modalities. We suggest effective prompting strategies for LVLMs for entity verification that leverage reference images crawled from web. Moreover, we extend three existing datasets for the task of entity verification in news providing manual ground-truth data. Our results show the potential of LVLMs for automating cross-modal entity verification, showing improved accuracy in identifying persons and events when using evidence images. Moreover, our method outperforms a baseline for location and event verification in documents. The datasets and source code are available on GitHub at \url{https://github.com/TIBHannover/LVLM4CEC}.
Multimodal Misinformation Detection using Large Vision-Language Models
Jul 19, 2024The increasing proliferation of misinformation and its alarming impact have motivated both industry and academia to develop approaches for misinformation detection and fact checking. Recent advances on large language models (LLMs) have shown remarkable performance in various tasks, but whether and how LLMs could help with misinformation detection remains relatively underexplored. Most of existing state-of-the-art approaches either do not consider evidence and solely focus on claim related features or assume the evidence to be provided. Few approaches consider evidence retrieval as part of the misinformation detection but rely on fine-tuning models. In this paper, we investigate the potential of LLMs for misinformation detection in a zero-shot setting. We incorporate an evidence retrieval component into the process as it is crucial to gather pertinent information from various sources to detect the veracity of claims. To this end, we propose a novel re-ranking approach for multimodal evidence retrieval using both LLMs and large vision-language models (LVLM). The retrieved evidence samples (images and texts) serve as the input for an LVLM-based approach for multimodal fact verification (LVLM4FV). To enable a fair evaluation, we address the issue of incomplete ground truth for evidence samples in an existing evidence retrieval dataset by annotating a more complete set of evidence samples for both image and text retrieval. Our experimental results on two datasets demonstrate the superiority of the proposed approach in both evidence retrieval and fact verification tasks and also better generalization capability across dataset compared to the supervised baseline.
Classification of Visualization Types and Perspectives in Patents
Jul 19, 2023



Due to the swift growth of patent applications each year, information and multimedia retrieval approaches that facilitate patent exploration and retrieval are of utmost importance. Different types of visualizations (e.g., graphs, technical drawings) and perspectives (e.g., side view, perspective) are used to visualize details of innovations in patents. The classification of these images enables a more efficient search and allows for further analysis. So far, datasets for image type classification miss some important visualization types for patents. Furthermore, related work does not make use of recent deep learning approaches including transformers. In this paper, we adopt state-of-the-art deep learning methods for the classification of visualization types and perspectives in patent images. We extend the CLEF-IP dataset for image type classification in patents to ten classes and provide manual ground truth annotations. In addition, we derive a set of hierarchical classes from a dataset that provides weakly-labeled data for image perspectives. Experimental results have demonstrated the feasibility of the proposed approaches. Source code, models, and dataset will be made publicly available.
Improving Generalization for Multimodal Fake News Detection
May 29, 2023The increasing proliferation of misinformation and its alarming impact have motivated both industry and academia to develop approaches for fake news detection. However, state-of-the-art approaches are usually trained on datasets of smaller size or with a limited set of specific topics. As a consequence, these models lack generalization capabilities and are not applicable to real-world data. In this paper, we propose three models that adopt and fine-tune state-of-the-art multimodal transformers for multimodal fake news detection. We conduct an in-depth analysis by manipulating the input data aimed to explore models performance in realistic use cases on social media. Our study across multiple models demonstrates that these systems suffer significant performance drops against manipulated data. To reduce the bias and improve model generalization, we suggest training data augmentation to conduct more meaningful experiments for fake news detection on social media. The proposed data augmentation techniques enable models to generalize better and yield improved state-of-the-art results.
MM-Locate-News: Multimodal Focus Location Estimation in News
Nov 15, 2022



The consumption of news has changed significantly as the Web has become the most influential medium for information. To analyze and contextualize the large amount of news published every day, the geographic focus of an article is an important aspect in order to enable content-based news retrieval. There are methods and datasets for geolocation estimation from text or photos, but they are typically considered as separate tasks. However, the photo might lack geographical cues and text can include multiple locations, making it challenging to recognize the focus location using a single modality. In this paper, a novel dataset called Multimodal Focus Location of News (MM-Locate-News) is introduced. We evaluate state-of-the-art methods on the new benchmark dataset and suggest novel models to predict the focus location of news using both textual and image content. The experimental results show that the multimodal model outperforms unimodal models.
MM-Claims: A Dataset for Multimodal Claim Detection in Social Media
May 04, 2022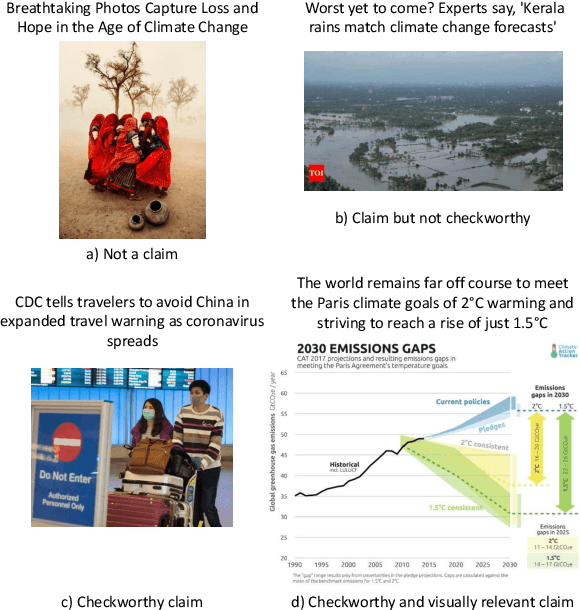
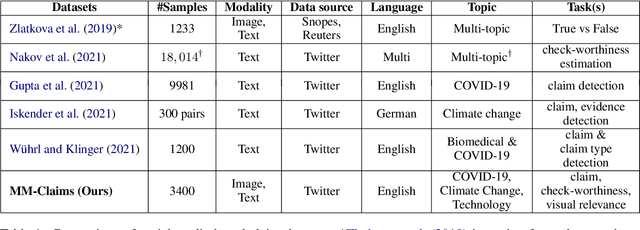
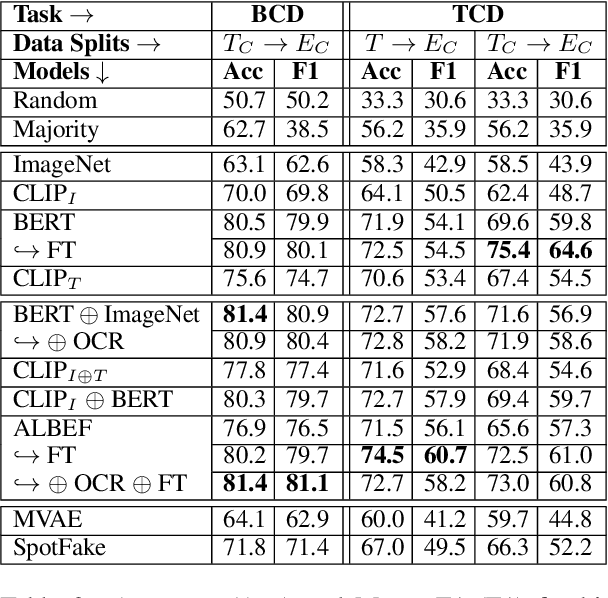
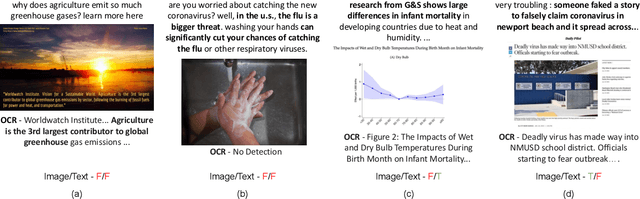
In recent years, the problem of misinformation on the web has become widespread across languages, countries, and various social media platforms. Although there has been much work on automated fake news detection, the role of images and their variety are not well explored. In this paper, we investigate the roles of image and text at an earlier stage of the fake news detection pipeline, called claim detection. For this purpose, we introduce a novel dataset, MM-Claims, which consists of tweets and corresponding images over three topics: COVID-19, Climate Change and broadly Technology. The dataset contains roughly 86000 tweets, out of which 3400 are labeled manually by multiple annotators for the training and evaluation of multimodal models. We describe the dataset in detail, evaluate strong unimodal and multimodal baselines, and analyze the potential and drawbacks of current models.
Extraction of Positional Player Data from Broadcast Soccer Videos
Oct 21, 2021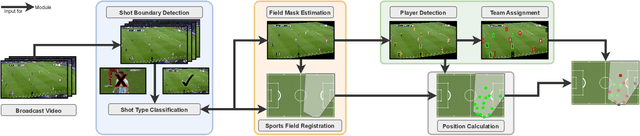

Computer-aided support and analysis are becoming increasingly important in the modern world of sports. The scouting of potential prospective players, performance as well as match analysis, and the monitoring of training programs rely more and more on data-driven technologies to ensure success. Therefore, many approaches require large amounts of data, which are, however, not easy to obtain in general. In this paper, we propose a pipeline for the fully-automated extraction of positional data from broadcast video recordings of soccer matches. In contrast to previous work, the system integrates all necessary sub-tasks like sports field registration, player detection, or team assignment that are crucial for player position estimation. The quality of the modules and the entire system is interdependent. A comprehensive experimental evaluation is presented for the individual modules as well as the entire pipeline to identify the influence of errors to subsequent modules and the overall result. In this context, we propose novel evaluation metrics to compare the output with ground-truth positional data.
Unsupervised Training Data Generation of Handwritten Formulas using Generative Adversarial Networks with Self-Attention
Jun 17, 2021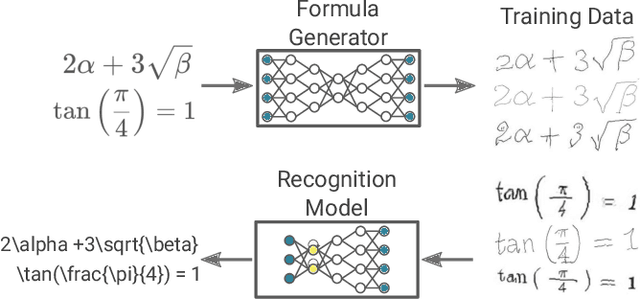
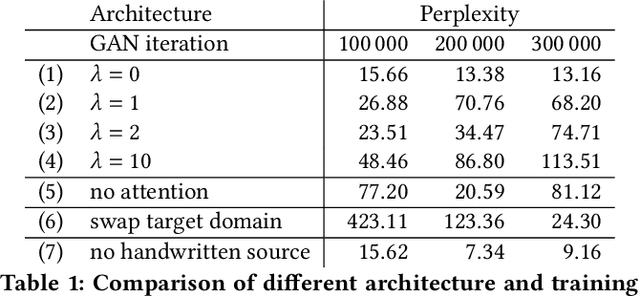
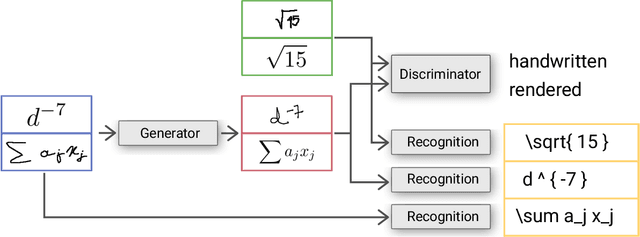
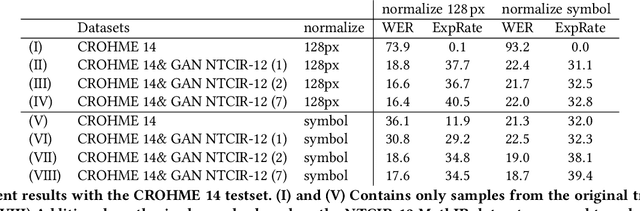
The recognition of handwritten mathematical expressions in images and video frames is a difficult and unsolved problem yet. Deep convectional neural networks are basically a promising approach, but typically require a large amount of labeled training data. However, such a large training dataset does not exist for the task of handwritten formula recognition. In this paper, we introduce a system that creates a large set of synthesized training examples of mathematical expressions which are derived from LaTeX documents. For this purpose, we propose a novel attention-based generative adversarial network to translate rendered equations to handwritten formulas. The datasets generated by this approach contain hundreds of thousands of formulas, making it ideal for pretraining or the design of more complex models. We evaluate our synthesized dataset and the recognition approach on the CROHME 2014 benchmark dataset. Experimental results demonstrate the feasibility of the approach.
A Fair and Comprehensive Comparison of Multimodal Tweet Sentiment Analysis Methods
Jun 16, 2021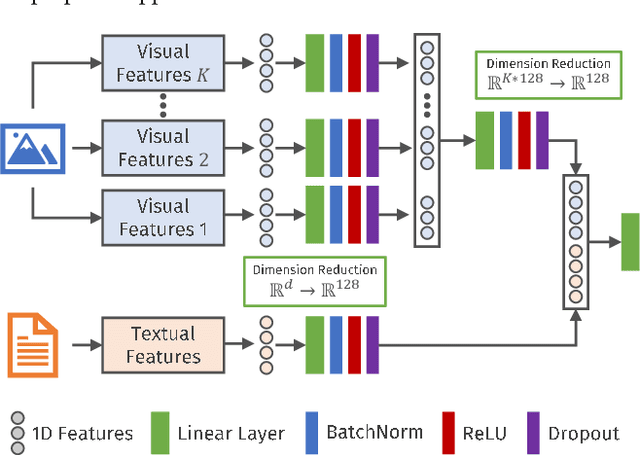
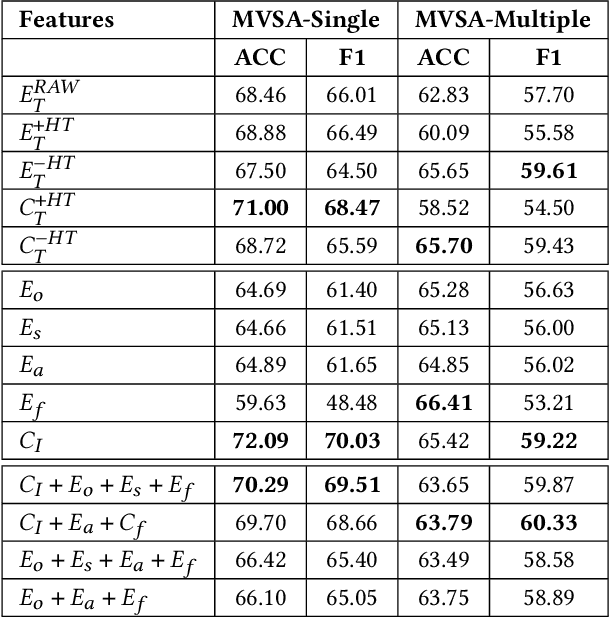
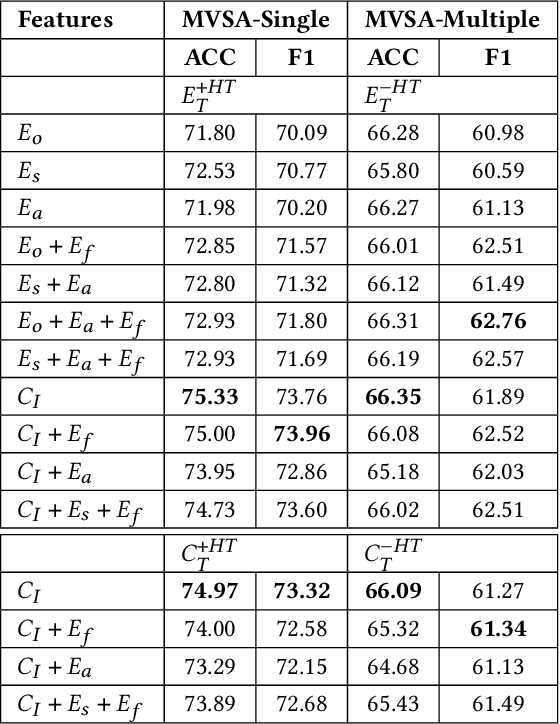
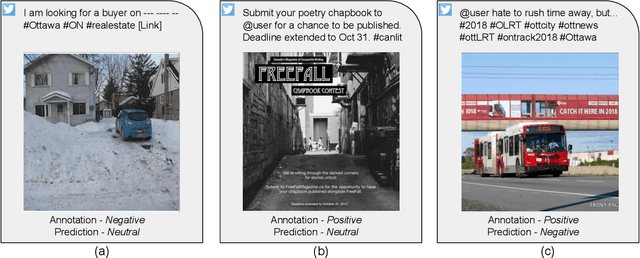
Opinion and sentiment analysis is a vital task to characterize subjective information in social media posts. In this paper, we present a comprehensive experimental evaluation and comparison with six state-of-the-art methods, from which we have re-implemented one of them. In addition, we investigate different textual and visual feature embeddings that cover different aspects of the content, as well as the recently introduced multimodal CLIP embeddings. Experimental results are presented for two different publicly available benchmark datasets of tweets and corresponding images. In contrast to the evaluation methodology of previous work, we introduce a reproducible and fair evaluation scheme to make results comparable. Finally, we conduct an error analysis to outline the limitations of the methods and possibilities for the future work.