 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic News Generation for Fake News Classification
Mar 31, 2025This study explores the generation and evaluation of synthetic fake news through fact based manipulations using large language models (LLMs). We introduce a novel methodology that extracts key facts from real articles, modifies them, and regenerates content to simulate fake news while maintaining coherence. To assess the quality of the generated content, we propose a set of evaluation metrics coherence, dissimilarity, and correctness. The research also investigates the application of synthetic data in fake news classification, comparing traditional machine learning models with transformer based models such as BERT. Our experiments demonstrate that transformer models, especially BERT, effectively leverage synthetic data for fake news detection, showing improvements with smaller proportions of synthetic data. Additionally, we find that fact verification features, which focus on identifying factual inconsistencies, provide the most promising results in distinguishing synthetic fake news. The study highlights the potential of synthetic data to enhance fake news detection systems, offering valuable insights for future research and suggesting that targeted improvements in synthetic data generation can further strengthen detection models.
Agent-Based Simulations of Online Political Discussions: A Case Study on Elections in Germany
Mar 31, 2025User engagement on social media platforms is influenced by historical context, time constraints, and reward-driven interactions. This study presents an agent-based simulation approach that models user interactions, considering past conversation history, motivation, and resource constraints. Utilizing German Twitter data on political discourse, we fine-tune AI models to generate posts and replies, incorporating sentiment analysis, irony detection, and offensiveness classification. The simulation employs a myopic best-response model to govern agent behavior, accounting for decision-making based on expected rewards. Our results highlight the impact of historical context on AI-generated responses and demonstrate how engagement evolves under varying constraints.
BAR-Analytics: A Web-based Platform for Analyzing Information Spreading Barriers in News: Comparative Analysis Across Multiple Barriers and Events
Mar 31, 2025This paper presents BAR-Analytics, a web-based, open-source platform designed to analyze news dissemination across geographical, economic, political, and cultural boundaries. Using the Russian-Ukrainian and Israeli-Palestinian conflicts as case studies, the platform integrates four analytical methods: propagation analysis, trend analysis, sentiment analysis, and temporal topic modeling. Over 350,000 articles were collected and analyzed, with a focus on economic disparities and geographical influences using metadata enrichment. We evaluate the case studies using coherence, sentiment polarity, topic frequency, and trend shifts as key metrics. Our results show distinct patterns in news coverage: the Israeli-Palestinian conflict tends to have more negative sentiment with a focus on human rights, while the Russia-Ukraine conflict is more positive, emphasizing election interference. These findings highlight the influence of political, economic, and regional factors in shaping media narratives across different conflicts.
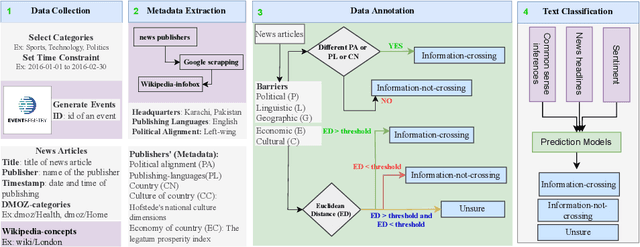
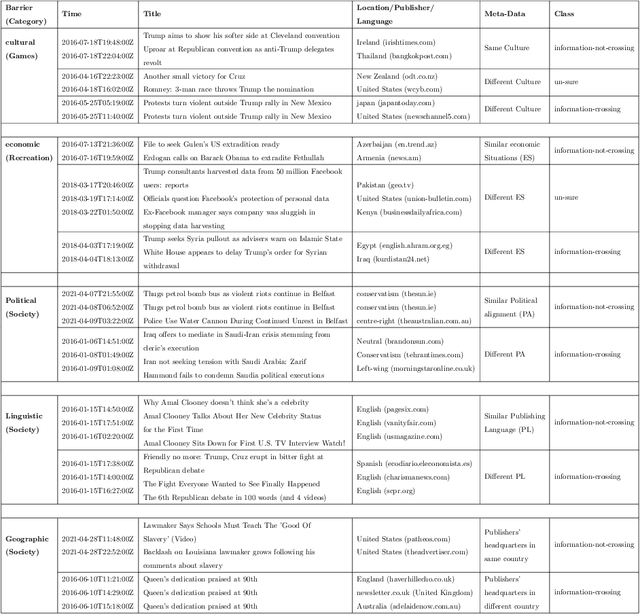
Classification of news spreading barriers
Apr 10, 2023News media is one of the most effective mechanisms for spreading information internationally, and many events from different areas are internationally relevant. However, news coverage for some news events is limited to a specific geographical region because of information spreading barriers, which can be political, geographical, economic, cultural, or linguistic. In this paper, we propose an approach to barrier classification where we infer the semantics of news articles through Wikipedia concepts. To that end, we collected news articles and annotated them for different kinds of barriers using the metadata of news publishers. Then, we utilize the Wikipedia concepts along with the body text of news articles as features to infer the news-spreading barriers. We compare our approach to the classical text classification methods, deep learning, and transformer-based methods. The results show that the proposed approach using Wikipedia concepts based semantic knowledge offers better performance than the usual for classifying the news-spreading barriers.
Profiling the news spreading barriers using news headlines
Apr 07, 2023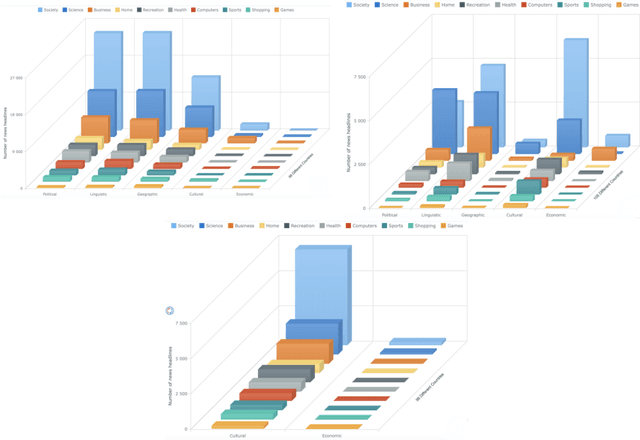
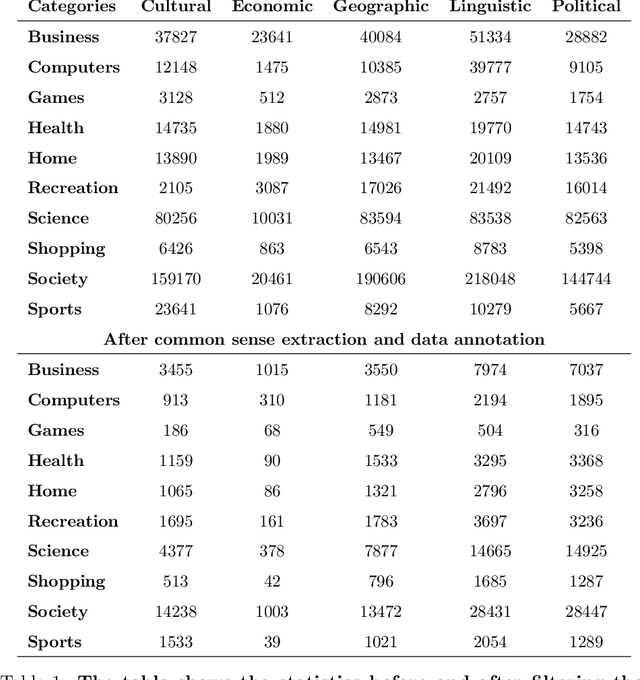
News headlines can be a good data source for detecting the news spreading barriers in news media, which may be useful in many real-world applications. In this paper, we utilize semantic knowledge through the inference-based model COMET and sentiments of news headlines for barrier classification. We consider five barriers including cultural, economic, political, linguistic, and geographical, and different types of news headlines including health, sports, science, recreation, games, homes, society, shopping, computers, and business. To that end, we collect and label the news headlines automatically for the barriers using the metadata of news publishers. Then, we utilize the extracted commonsense inferences and sentiments as features to detect the news spreading barriers. We compare our approach to the classical text classification methods, deep learning, and transformer-based methods. The results show that the proposed approach using inferences-based semantic knowledge and sentiment offers better performance than the usual (the average F1-score of the ten categories improves from 0.41, 0.39, 0.59, and 0.59 to 0.47, 0.55, 0.70, and 0.76 for the cultural, economic, political, and geographical respectively) for classifying the news-spreading barriers.
OEKG: The Open Event Knowledge Graph
Feb 28, 2023



Accessing and understanding contemporary and historical events of global impact such as the US elections and the Olympic Games is a major prerequisite for cross-lingual event analytics that investigate event causes, perception and consequences across country borders. In this paper, we present the Open Event Knowledge Graph (OEKG), a multilingual, event-centric, temporal knowledge graph composed of seven different data sets from multiple application domains, including question answering, entity recommendation and named entity recognition. These data sets are all integrated through an easy-to-use and robust pipeline and by linking to the event-centric knowledge graph EventKG. We describe their common schema and demonstrate the use of the OEKG at the example of three use cases: type-specific image retrieval, hybrid question answering over knowledge graphs and news articles, as well as language-specific event recommendation. The OEKG and its query endpoint are publicly available.
Classification of Cross-cultural News Events
Jan 13, 2023



We present a methodology to support the analysis of culture from text such as news events and demonstrate its usefulness on categorizing news events from different categories (society, business, health, recreation, science, shopping, sports, arts, computers, games and home) across different geographical locations (different places in 117 countries). We group countries based on the culture that they follow and then filter the news events based on their content category. The news events are automatically labelled with the help of Hofstedes cultural dimensions. We present combinations of events across different categories and check the performances of different classification methods. We also presents experimental comparison of different number of features in order to find a suitable set to represent the culture.
Using the profile of publishers to predict barriers across news articles
Jan 13, 2023



Detection of news propagation barriers, being economical, cultural, political, time zonal, or geographical, is still an open research issue. We present an approach to barrier detection in news spreading by utilizing Wikipedia-concepts and metadata associated with each barrier. Solving this problem can not only convey the information about the coverage of an event but it can also show whether an event has been able to cross a specific barrier or not. Experimental results on IPoNews dataset (dataset for information spreading over the news) reveals that simple classification models are able to detect barriers with high accuracy. We believe that our approach can serve to provide useful insights which pave the way for the future development of a system for predicting information spreading barriers over the news.
Political and Economic Patterns in COVID-19 News: From Lockdown to Vaccination
Dec 15, 2022
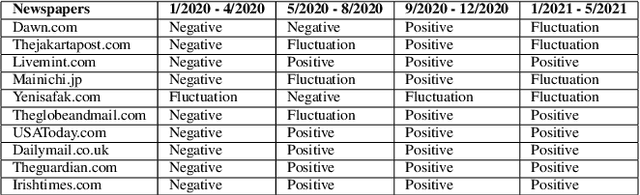
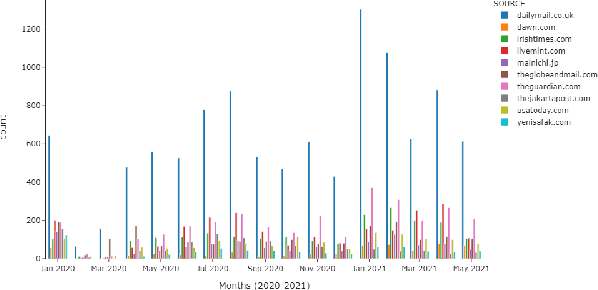
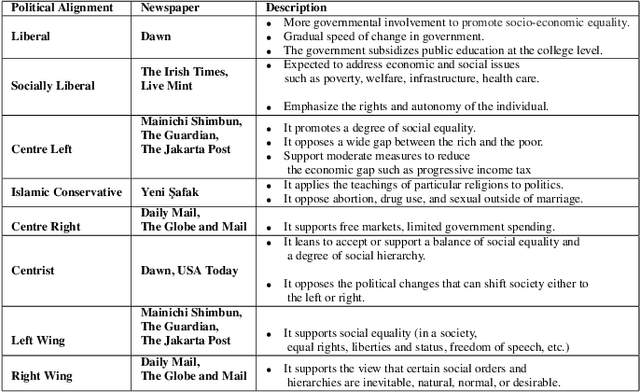
The purpose of this study is to analyse COVID-19 related news published across different geographical places, in order to gain insights in reporting differences. The COVID-19 pandemic had a major outbreak in January 2020 and was followed by different preventive measures, lockdown, and finally by the process of vaccination. To date, more comprehensive analysis of news related to COVID-19 pandemic are missing, especially those which explain what aspects of this pandemic are being reported by newspapers inserted in different economies and belonging to different political alignments. Since LDA is often less coherent when there are news articles published across the world about an event and you look answers for specific queries. It is because of having semantically different content. To address this challenge, we performed pooling of news articles based on information retrieval using TF-IDF score in a data processing step and topic modeling using LDA with combination of 1 to 6 ngrams. We used VADER sentiment analyzer to analyze the differences in sentiments in news articles reported across different geographical places. The novelty of this study is to look at how COVID-19 pandemic was reported by the media, providing a comparison among countries in different political and economic contexts. Our findings suggest that the news reporting by newspapers with different political alignment support the reported content. Also, economic issues reported by newspapers depend on economy of the place where a newspaper resides.
Analysis of information cascading and propagation barriers across distinctive news events
Dec 15, 2022News reporting on events that occur in our society can have different styles and structures as well as different dynamics of news spreading over time. News publishers have the potential to spread their news and reach out to a large number of readers worldwide. In this paper we would like to understand how well they are doing it and which kind of obstacles the news may encounter when spreading. The news to be spread wider cross multiple barriers such as linguistic (the most evident one as they get published in other natural languages), economic, geographical, political, time zone, and cultural barriers. Observing potential differences between spreading of news on different events published by multiple publishers can bring insights into what may influence the differences in the spreading patterns. There are multiple reasons, possibly many hidden, influencing the speed and geographical spread of news. This paper studies information cascading and propagation barriers, applying the proposed methodology on three distinctive kinds of events: Global Warming, earthquakes, and FIFA World Cup.