 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unsampled Truth: Psychometrics in SLMs Measure Prompt Artifacts, Not Psychological Constructs
Jun 02, 2026When prompting SLMs for psychometric assessments, researchers assume the outputs reflect semantic reasoning. We evaluate this premise across 13 open-weights models (0.6B to 14B parameters) using a prompt variation framework that separates semantic signals from prompt artifacts. By systematically varying personas, instructions, items, and option symbols, we find that artifactual variance frequently overpowers the semantic signal. In these cases, models predominantly reflect prompt compliance rather than simulated psychological traits. While these findings limit SLM utility in psychometrics, our framework provides a diagnostic tool to identify destructive artifacts and isolate semantic understanding for future frontier-model research.
Towards Simulating Social Media Users with LLMs: Evaluating the Operational Validity of Conditioned Comment Prediction
Feb 26, 2026The transition of Large Language Models (LLMs) from exploratory tools to active "silicon subjects" in social science lacks extensive validation of operational validity. This study introduces Conditioned Comment Prediction (CCP), a task in which a model predicts how a user would comment on a given stimulus by comparing generated outputs with authentic digital traces. This framework enables a rigorous evaluation of current LLM capabilities with respect to the simulation of social media user behavior. We evaluated open-weight 8B models (Llama3.1, Qwen3, Ministral) in English, German, and Luxembourgish language scenarios. By systematically comparing prompting strategies (explicit vs. implicit) and the impact of Supervised Fine-Tuning (SFT), we identify a critical form vs. content decoupling in low-resource settings: while SFT aligns the surface structure of the text output (length and syntax), it degrades semantic grounding. Furthermore, we demonstrate that explicit conditioning (generated biographies) becomes redundant under fine-tuning, as models successfully perform latent inference directly from behavioral histories. Our findings challenge current "naive prompting" paradigms and offer operational guidelines prioritizing authentic behavioral traces over descriptive personas for high-fidelity simulation.
Next Reply Prediction X Dataset: Linguistic Discrepancies in Naively Generated Content
Feb 22, 2026The increasing use of Large Language Models (LLMs) as proxies for human participants in social science research presents a promising, yet methodologically risky, paradigm shift. While LLMs offer scalability and cost-efficiency, their "naive" application, where they are prompted to generate content without explicit behavioral constraints, introduces significant linguistic discrepancies that challenge the validity of research findings. This paper addresses these limitations by introducing a novel, history-conditioned reply prediction task on authentic X (formerly Twitter) data, to create a dataset designed to evaluate the linguistic output of LLMs against human-generated content. We analyze these discrepancies using stylistic and content-based metrics, providing a quantitative framework for researchers to assess the quality and authenticity of synthetic data. Our findings highlight the need for more sophisticated prompting techniques and specialized datasets to ensure that LLM-generated content accurately reflects the complex linguistic patterns of human communication, thereby improving the validity of computational social science studies.
Agent-Based Simulations of Online Political Discussions: A Case Study on Elections in Germany
Mar 31, 2025User engagement on social media platforms is influenced by historical context, time constraints, and reward-driven interactions. This study presents an agent-based simulation approach that models user interactions, considering past conversation history, motivation, and resource constraints. Utilizing German Twitter data on political discourse, we fine-tune AI models to generate posts and replies, incorporating sentiment analysis, irony detection, and offensiveness classification. The simulation employs a myopic best-response model to govern agent behavior, accounting for decision-making based on expected rewards. Our results highlight the impact of historical context on AI-generated responses and demonstrate how engagement evolves under varying constraints.
Zero-shot prompt-based classification: topic labeling in times of foundation models in German Tweets
Jun 26, 2024


Filtering and annotating textual data are routine tasks in many areas, like social media or news analytics. Automating these tasks allows to scale the analyses wrt. speed and breadth of content covered and decreases the manual effort required. Due to technical advancements in Natural Language Processing, specifically the success of large foundation models, a new tool for automating such annotation processes by using a text-to-text interface given written guidelines without providing training samples has become available. In this work, we assess these advancements in-the-wild by empirically testing them in an annotation task on German Twitter data about social and political European crises. We compare the prompt-based results with our human annotation and preceding classification approaches, including Naive Bayes and a BERT-based fine-tuning/domain adaptation pipeline. Our results show that the prompt-based approach - despite being limited by local computation resources during the model selection - is comparable with the fine-tuned BERT but without any annotated training data. Our findings emphasize the ongoing paradigm shift in the NLP landscape, i.e., the unification of downstream tasks and elimination of the need for pre-labeled training data.
POV Learning: Individual Alignment of Multimodal Models using Human Perception
May 07, 2024Aligning machine learning systems with human expectations is mostly attempted by training with manually vetted human behavioral samples, typically explicit feedback. This is done on a population level since the context that is capturing the subjective Point-Of-View (POV) of a concrete person in a specific situational context is not retained in the data. However, we argue that alignment on an individual level can boost the subjective predictive performance for the individual user interacting with the system considerably. Since perception differs for each person, the same situation is observed differently. Consequently, the basis for decision making and the subsequent reasoning processes and observable reactions differ. We hypothesize that individual perception patterns can be used for improving the alignment on an individual level. We test this, by integrating perception information into machine learning systems and measuring their predictive performance wrt.~individual subjective assessments. For our empirical study, we collect a novel data set of multimodal stimuli and corresponding eye tracking sequences for the novel task of Perception-Guided Crossmodal Entailment and tackle it with our Perception-Guided Multimodal Transformer. Our findings suggest that exploiting individual perception signals for the machine learning of subjective human assessments provides a valuable cue for individual alignment. It does not only improve the overall predictive performance from the point-of-view of the individual user but might also contribute to steering AI systems towards every person's individual expectations and values.
Heterogeneous Graph-based Trajectory Prediction using Local Map Context and Social Interactions
Nov 30, 2023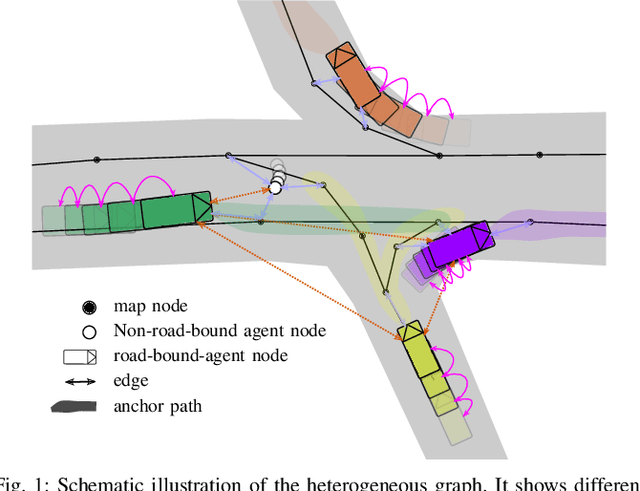
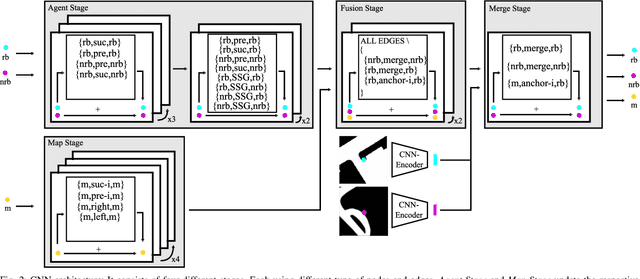
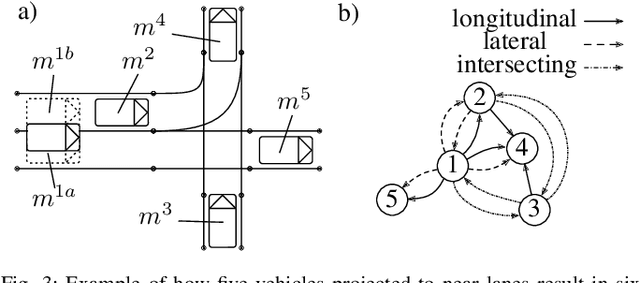
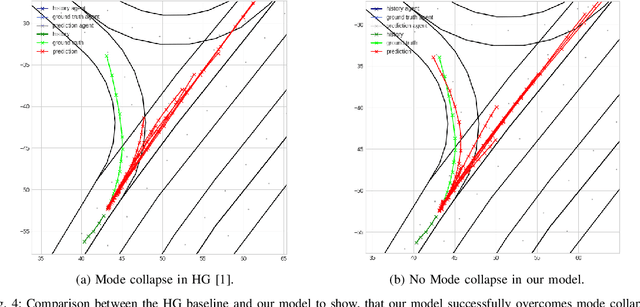
Precisely predicting the future trajectories of surrounding traffic participants is a crucial but challenging problem in autonomous driving, due to complex interactions between traffic agents, map context and traffic rules. Vector-based approaches have recently shown to achieve among the best performances on trajectory prediction benchmarks. These methods model simple interactions between traffic agents but don't distinguish between relation-type and attributes like their distance along the road. Furthermore, they represent lanes only by sequences of vectors representing center lines and ignore context information like lane dividers and other road elements. We present a novel approach for vector-based trajectory prediction that addresses these shortcomings by leveraging three crucial sources of information: First, we model interactions between traffic agents by a semantic scene graph, that accounts for the nature and important features of their relation. Second, we extract agent-centric image-based map features to model the local map context. Finally, we generate anchor paths to enforce the policy in multi-modal prediction to permitted trajectories only. Each of these three enhancements shows advantages over the baseline model HoliGraph.
Relation-based Motion Prediction using Traffic Scene Graphs
Nov 24, 2022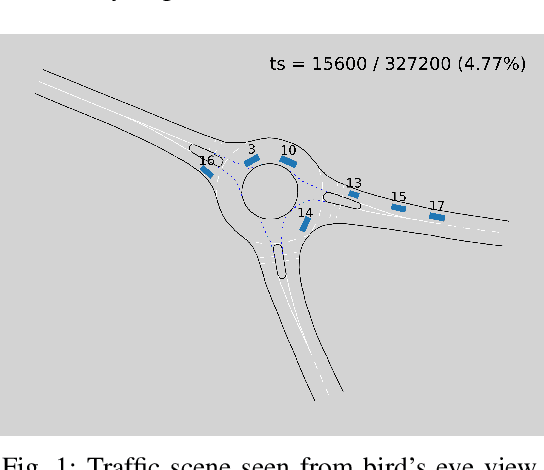
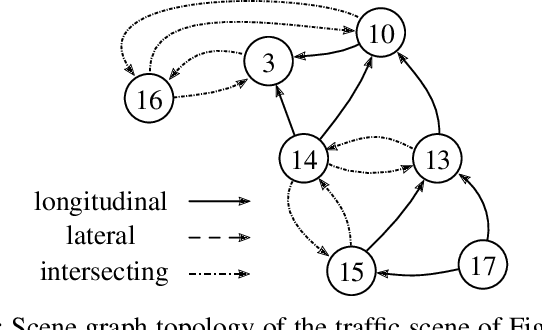
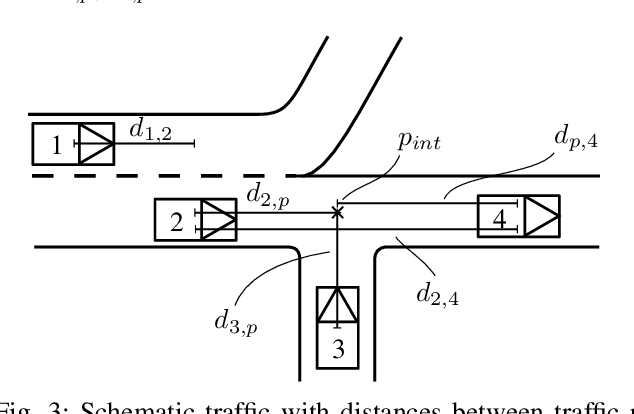
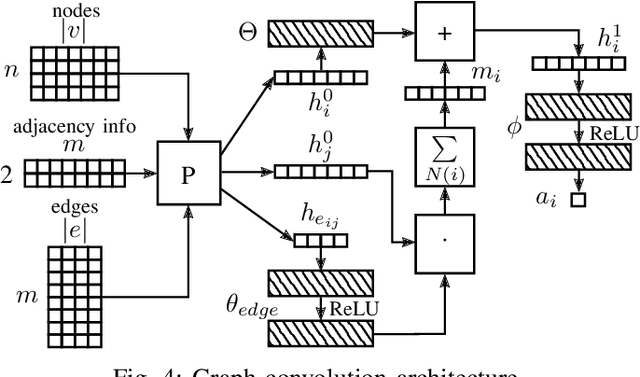
Representing relevant information of a traffic scene and understanding its environment is crucial for the success of autonomous driving. Modeling the surrounding of an autonomous car using semantic relations, i.e., how different traffic participants relate in the context of traffic rule based behaviors, is hardly been considered in previous work. This stems from the fact that these relations are hard to extract from real-world traffic scenes. In this work, we model traffic scenes in a form of spatial semantic scene graphs for various different predictions about the traffic participants, e.g., acceleration and deceleration. Our learning and inference approach uses Graph Neural Networks (GNNs) and shows that incorporating explicit information about the spatial semantic relations between traffic participants improves the predicdtion results. Specifically, the acceleration prediction of traffic participants is improved by up to 12% compared to the baselines, which do not exploit this explicit information. Furthermore, by including additional information about previous scenes, we achieve 73% improvements.
Context-driven Visual Object Recognition based on Knowledge Graphs
Oct 20, 2022
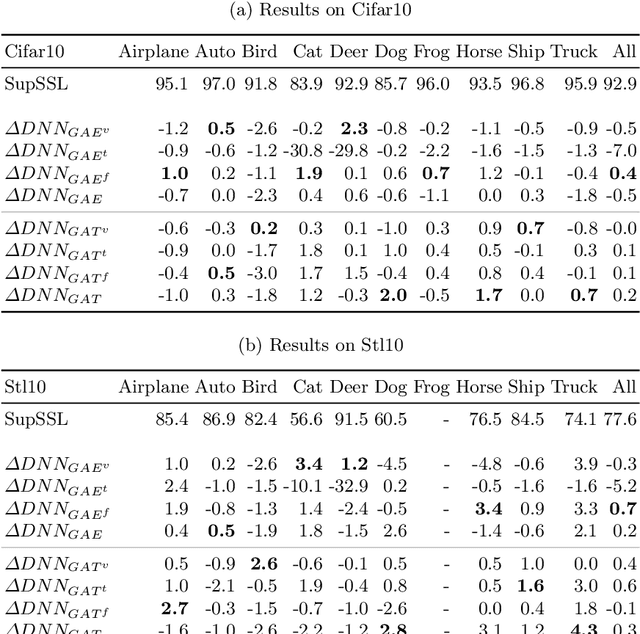
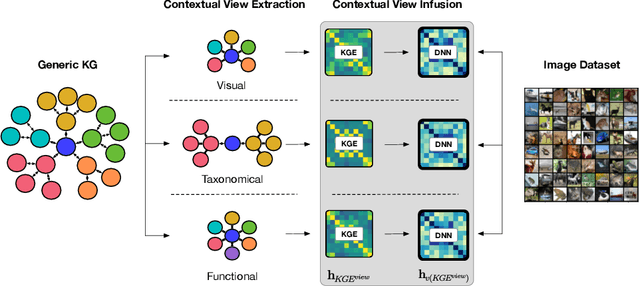
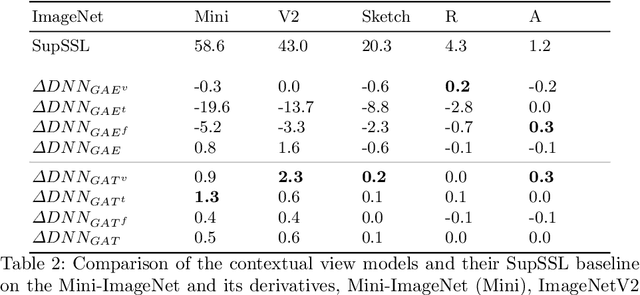
Current deep learning methods for object recognition are purely data-driven and require a large number of training samples to achieve good results. Due to their sole dependence on image data, these methods tend to fail when confronted with new environments where even small deviations occur. Human perception, however, has proven to be significantly more robust to such distribution shifts. It is assumed that their ability to deal with unknown scenarios is based on extensive incorporation of contextual knowledge. Context can be based either on object co-occurrences in a scene or on memory of experience. In accordance with the human visual cortex which uses context to form different object representations for a seen image, we propose an approach that enhances deep learning methods by using external contextual knowledge encoded in a knowledge graph. Therefore, we extract different contextual views from a generic knowledge graph, transform the views into vector space and infuse it into a DNN. We conduct a series of experiments to investigate the impact of different contextual views on the learned object representations for the same image dataset. The experimental results provide evidence that the contextual views influence the image representations in the DNN differently and therefore lead to different predictions for the same images. We also show that context helps to strengthen the robustness of object recognition models for out-of-distribution images, usually occurring in transfer learning tasks or real-world scenarios.
Signing the Supermask: Keep, Hide, Invert
Feb 17, 2022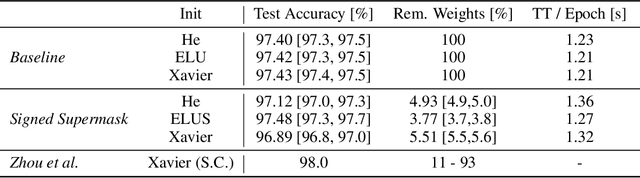
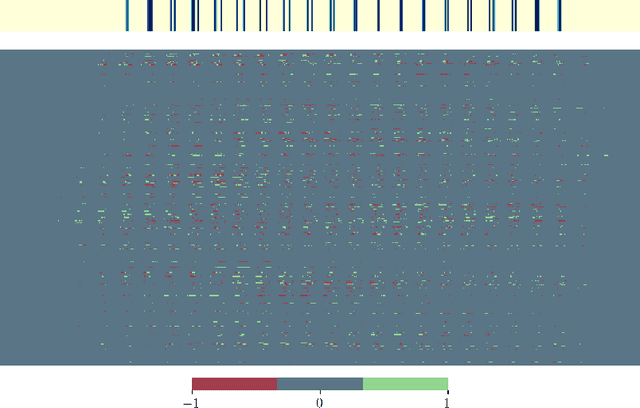

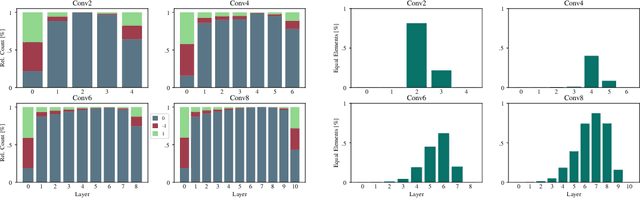
The exponential growth in numbers of parameters of neural networks over the past years has been accompanied by an increase in performance across several fields. However, due to their sheer size, the networks not only became difficult to interpret but also problematic to train and use in real-world applications, since hardware requirements increased accordingly. Tackling both issues, we present a novel approach that either drops a neural network's initial weights or inverts their respective sign. Put simply, a network is trained by weight selection and inversion without changing their absolute values. Our contribution extends previous work on masking by additionally sign-inverting the initial weights and follows the findings of the Lottery Ticket Hypothesis. Through this extension and adaptations of initialization methods, we achieve a pruning rate of up to 99%, while still matching or exceeding the performance of various baseline and previous models. Our approach has two main advantages. First, and most notable, signed Supermask models drastically simplify a model's structure, while still performing well on given tasks. Second, by reducing the neural network to its very foundation, we gain insights into which weights matter for performance. The code is available on GitHub.