 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Random Forests' Probabilistic Forecasts
Aug 22, 2024Since their introduction by Breiman, Random Forests (RFs) have proven to be useful for both classification and regression tasks. The RF prediction of a previously unseen observation can be represented as a weighted sum of all training sample observations. This nearest-neighbor-type representation is useful, among other things, for constructing forecast distributions (Meinshausen, 2006). In this paper, we consider simplifying RF-based forecast distributions by sparsifying them. That is, we focus on a small subset of nearest neighbors while setting the remaining weights to zero. This sparsification step greatly improves the interpretability of RF predictions. It can be applied to any forecasting task without re-training existing RF models. In empirical experiments, we document that the simplified predictions can be similar to or exceed the original ones in terms of forecasting performance. We explore the statistical sources of this finding via a stylized analytical model of RFs. The model suggests that simplification is particularly promising if the unknown true forecast distribution contains many small weights that are estimated imprecisely.
Signing the Supermask: Keep, Hide, Invert
Feb 17, 2022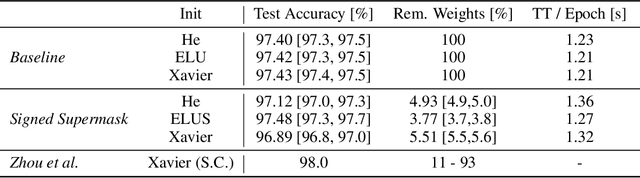
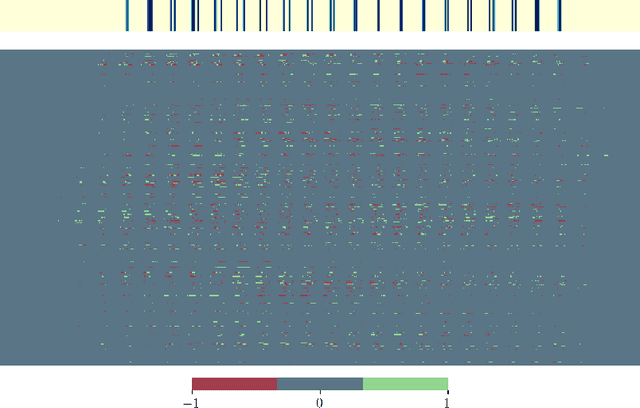

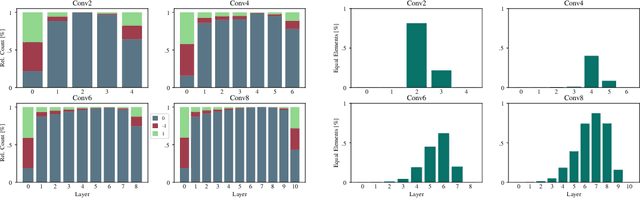
The exponential growth in numbers of parameters of neural networks over the past years has been accompanied by an increase in performance across several fields. However, due to their sheer size, the networks not only became difficult to interpret but also problematic to train and use in real-world applications, since hardware requirements increased accordingly. Tackling both issues, we present a novel approach that either drops a neural network's initial weights or inverts their respective sign. Put simply, a network is trained by weight selection and inversion without changing their absolute values. Our contribution extends previous work on masking by additionally sign-inverting the initial weights and follows the findings of the Lottery Ticket Hypothesis. Through this extension and adaptations of initialization methods, we achieve a pruning rate of up to 99%, while still matching or exceeding the performance of various baseline and previous models. Our approach has two main advantages. First, and most notable, signed Supermask models drastically simplify a model's structure, while still performing well on given tasks. Second, by reducing the neural network to its very foundation, we gain insights into which weights matter for performance. The code is available on GitHub.