 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Nonparametric High-Dimensional Generative Models: The Empirical-Beta-Copula Autoencoder
Sep 18, 2023By sampling from the latent space of an autoencoder and decoding the latent space samples to the original data space, any autoencoder can simply be turned into a generative model. For this to work, it is necessary to model the autoencoder's latent space with a distribution from which samples can be obtained. Several simple possibilities (kernel density estimates, Gaussian distribution) and more sophisticated ones (Gaussian mixture models, copula models, normalization flows) can be thought of and have been tried recently. This study aims to discuss, assess, and compare various techniques that can be used to capture the latent space so that an autoencoder can become a generative model while striving for simplicity. Among them, a new copula-based method, the Empirical Beta Copula Autoencoder, is considered. Furthermore, we provide insights into further aspects of these methods, such as targeted sampling or synthesizing new data with specific features.
Signing the Supermask: Keep, Hide, Invert
Feb 17, 2022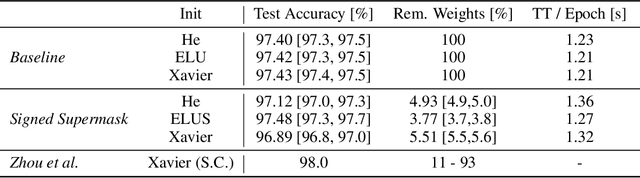
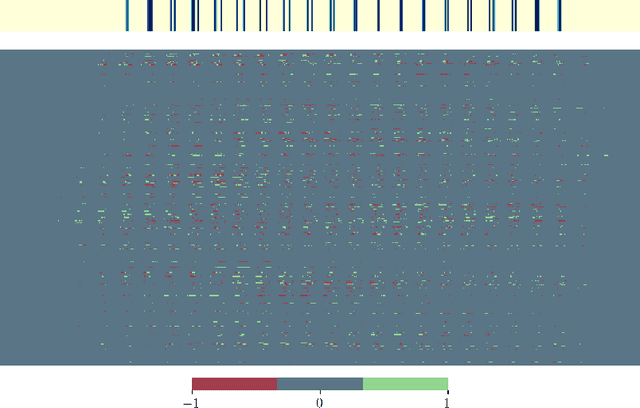

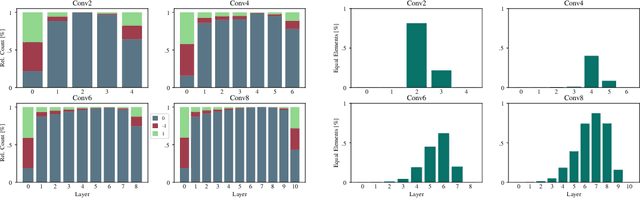
The exponential growth in numbers of parameters of neural networks over the past years has been accompanied by an increase in performance across several fields. However, due to their sheer size, the networks not only became difficult to interpret but also problematic to train and use in real-world applications, since hardware requirements increased accordingly. Tackling both issues, we present a novel approach that either drops a neural network's initial weights or inverts their respective sign. Put simply, a network is trained by weight selection and inversion without changing their absolute values. Our contribution extends previous work on masking by additionally sign-inverting the initial weights and follows the findings of the Lottery Ticket Hypothesis. Through this extension and adaptations of initialization methods, we achieve a pruning rate of up to 99%, while still matching or exceeding the performance of various baseline and previous models. Our approach has two main advantages. First, and most notable, signed Supermask models drastically simplify a model's structure, while still performing well on given tasks. Second, by reducing the neural network to its very foundation, we gain insights into which weights matter for performance. The code is available on GitHub.