 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeSCAN: ScreenCast ANalysis for Video Programming Tutorials
Sep 27, 2024Programming tutorials in the form of coding screencasts play a crucial role in programming education, serving both novices and experienced developers. However, the video format of these tutorials presents a challenge due to the difficulty of searching for and within videos. Addressing the absence of large-scale and diverse datasets for screencast analysis, we introduce the CodeSCAN dataset. It comprises 12,000 screenshots captured from the Visual Studio Code environment during development, featuring 24 programming languages, 25 fonts, and over 90 distinct themes, in addition to diverse layout changes and realistic user interactions. Moreover, we conduct detailed quantitative and qualitative evaluations to benchmark the performance of Integrated Development Environment (IDE) element detection, color-to-black-and-white conversion, and Optical Character Recognition (OCR). We hope that our contributions facilitate more research in coding screencast analysis, and we make the source code for creating the dataset and the benchmark publicly available on this website.
Heterogeneous Graph-based Trajectory Prediction using Local Map Context and Social Interactions
Nov 30, 2023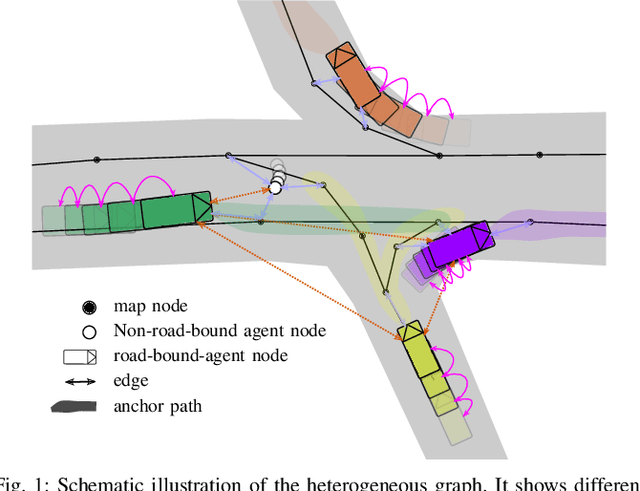
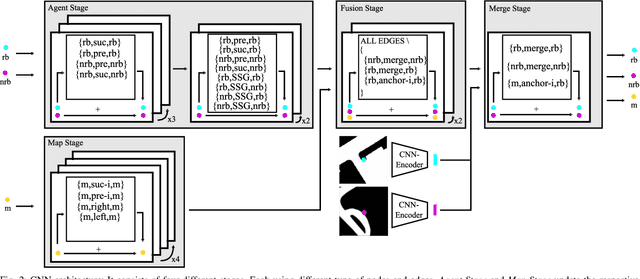
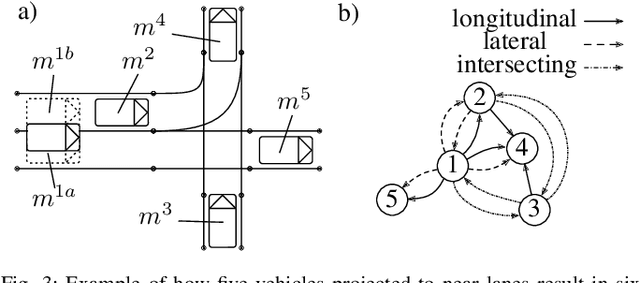
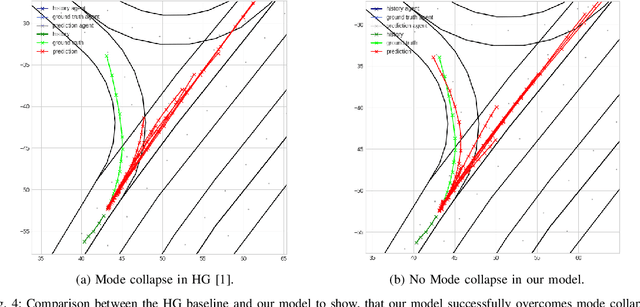
Precisely predicting the future trajectories of surrounding traffic participants is a crucial but challenging problem in autonomous driving, due to complex interactions between traffic agents, map context and traffic rules. Vector-based approaches have recently shown to achieve among the best performances on trajectory prediction benchmarks. These methods model simple interactions between traffic agents but don't distinguish between relation-type and attributes like their distance along the road. Furthermore, they represent lanes only by sequences of vectors representing center lines and ignore context information like lane dividers and other road elements. We present a novel approach for vector-based trajectory prediction that addresses these shortcomings by leveraging three crucial sources of information: First, we model interactions between traffic agents by a semantic scene graph, that accounts for the nature and important features of their relation. Second, we extract agent-centric image-based map features to model the local map context. Finally, we generate anchor paths to enforce the policy in multi-modal prediction to permitted trajectories only. Each of these three enhancements shows advantages over the baseline model HoliGraph.
TAMPAR: Visual Tampering Detection for Parcel Logistics in Postal Supply Chains
Nov 06, 2023



Due to the steadily rising amount of valuable goods in supply chains, tampering detection for parcels is becoming increasingly important. In this work, we focus on the use-case last-mile delivery, where only a single RGB image is taken and compared against a reference from an existing database to detect potential appearance changes that indicate tampering. We propose a tampering detection pipeline that utilizes keypoint detection to identify the eight corner points of a parcel. This permits applying a perspective transformation to create normalized fronto-parallel views for each visible parcel side surface. These viewpoint-invariant parcel side surface representations facilitate the identification of signs of tampering on parcels within the supply chain, since they reduce the problem to parcel side surface matching with pair-wise appearance change detection. Experiments with multiple classical and deep learning-based change detection approaches are performed on our newly collected TAMpering detection dataset for PARcels, called TAMPAR. We evaluate keypoint and change detection separately, as well as in a unified system for tampering detection. Our evaluation shows promising results for keypoint (Keypoint AP 75.76) and tampering detection (81% accuracy, F1-Score 0.83) on real images. Furthermore, a sensitivity analysis for tampering types, lens distortion and viewing angles is presented. Code and dataset are available at https://a-nau.github.io/tampar.
Parcel3D: Shape Reconstruction from Single RGB Images for Applications in Transportation Logistics
Apr 18, 2023



We focus on enabling damage and tampering detection in logistics and tackle the problem of 3D shape reconstruction of potentially damaged parcels. As input we utilize single RGB images, which corresponds to use-cases where only simple handheld devices are available, e.g. for postmen during delivery or clients on delivery. We present a novel synthetic dataset, named Parcel3D, that is based on the Google Scanned Objects (GSO) dataset and consists of more than 13,000 images of parcels with full 3D annotations. The dataset contains intact, i.e. cuboid-shaped, parcels and damaged parcels, which were generated in simulations. We work towards detecting mishandling of parcels by presenting a novel architecture called CubeRefine R-CNN, which combines estimating a 3D bounding box with an iterative mesh refinement. We benchmark our approach on Parcel3D and an existing dataset of cuboid-shaped parcels in real-world scenarios. Our results show, that while training on Parcel3D enables transfer to the real world, enabling reliable deployment in real-world scenarios is still challenging. CubeRefine R-CNN yields competitive performance in terms of Mesh AP and is the only model that directly enables deformation assessment by 3D mesh comparison and tampering detection by comparing viewpoint invariant parcel side surface representations. Dataset and code are available at https://a-nau.github.io/parcel3d.
Literature Review: Computer Vision Applications in Transportation Logistics and Warehousing
Apr 12, 2023
Computer vision applications in transportation logistics and warehousing have a huge potential for process automation. We present a structured literature review on research in the field to help leverage this potential. All literature is categorized w.r.t. the application, i.e. the task it tackles and w.r.t. the computer vision techniques that are used. Regarding applications, we subdivide the literature in two areas: Monitoring, i.e. observing and retrieving relevant information from the environment, and manipulation, where approaches are used to analyze and interact with the environment. In addition to that, we point out directions for future research and link to recent developments in computer vision that are suitable for application in logistics. Finally, we present an overview of existing datasets and industrial solutions. We conclude that while already many research areas have been investigated, there is still huge potential for future research. The results of our analysis are also available online at https://a-nau.github.io/cv-in-logistics.
Relation-based Motion Prediction using Traffic Scene Graphs
Nov 24, 2022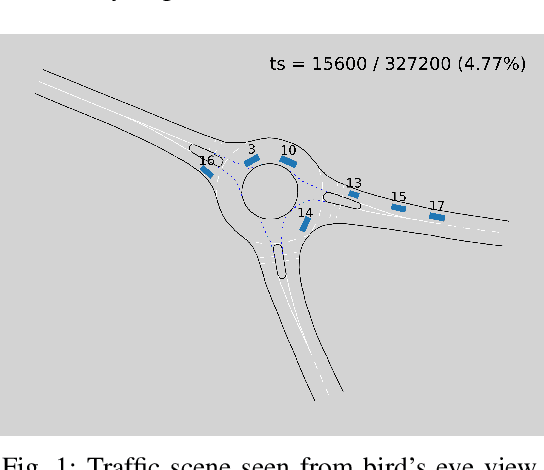
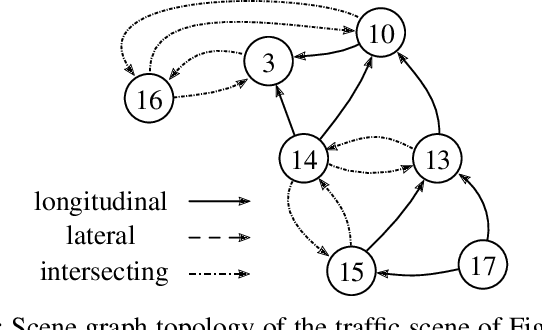
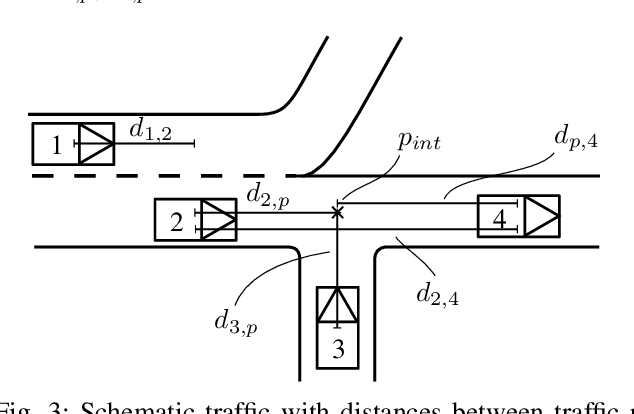
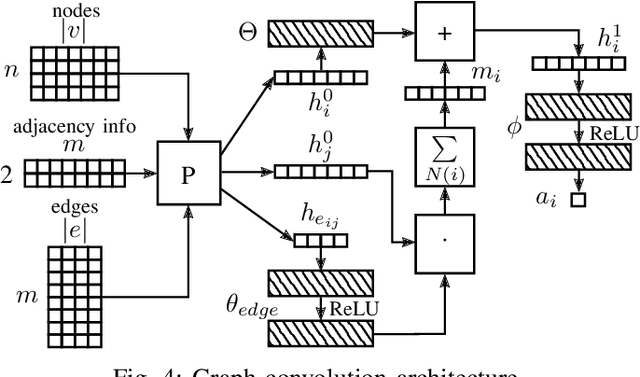
Representing relevant information of a traffic scene and understanding its environment is crucial for the success of autonomous driving. Modeling the surrounding of an autonomous car using semantic relations, i.e., how different traffic participants relate in the context of traffic rule based behaviors, is hardly been considered in previous work. This stems from the fact that these relations are hard to extract from real-world traffic scenes. In this work, we model traffic scenes in a form of spatial semantic scene graphs for various different predictions about the traffic participants, e.g., acceleration and deceleration. Our learning and inference approach uses Graph Neural Networks (GNNs) and shows that incorporating explicit information about the spatial semantic relations between traffic participants improves the predicdtion results. Specifically, the acceleration prediction of traffic participants is improved by up to 12% compared to the baselines, which do not exploit this explicit information. Furthermore, by including additional information about previous scenes, we achieve 73% improvements.
Scrape, Cut, Paste and Learn: Automated Dataset Generation Applied to Parcel Logistics
Oct 18, 2022


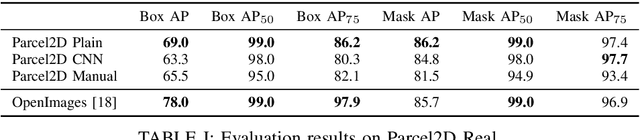
State-of-the-art approaches in computer vision heavily rely on sufficiently large training datasets. For real-world applications, obtaining such a dataset is usually a tedious task. In this paper, we present a fully automated pipeline to generate a synthetic dataset for instance segmentation in four steps. In contrast to existing work, our pipeline covers every step from data acquisition to the final dataset. We first scrape images for the objects of interest from popular image search engines and since we rely only on text-based queries the resulting data comprises a wide variety of images. Hence, image selection is necessary as a second step. This approach of image scraping and selection relaxes the need for a real-world domain-specific dataset that must be either publicly available or created for this purpose. We employ an object-agnostic background removal model and compare three different methods for image selection: Object-agnostic pre-processing, manual image selection and CNN-based image selection. In the third step, we generate random arrangements of the object of interest and distractors on arbitrary backgrounds. Finally, the composition of the images is done by pasting the objects using four different blending methods. We present a case study for our dataset generation approach by considering parcel segmentation. For the evaluation we created a dataset of parcel photos that were annotated automatically. We find that (1) our dataset generation pipeline allows a successful transfer to real test images (Mask AP 86.2), (2) a very accurate image selection process - in contrast to human intuition - is not crucial and a broader category definition can help to bridge the domain gap, (3) the usage of blending methods is beneficial compared to simple copy-and-paste. We made our full code for scraping, image composition and training publicly available at https://a-nau.github.io/parcel2d.