 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models to Develop Heuristics for Emerging Optimization Problems
Mar 05, 2025Combinatorial optimization problems often rely on heuristic algorithms to generate efficient solutions. However, the manual design of heuristics is resource-intensive and constrained by the designer's expertise. Recent advances in artificial intelligence, particularly large language models (LLMs), have demonstrated the potential to automate heuristic generation through evolutionary frameworks. Recent works focus only on well-known combinatorial optimization problems like the traveling salesman problem and online bin packing problem when designing constructive heuristics. This study investigates whether LLMs can effectively generate heuristics for niche, not yet broadly researched optimization problems, using the unit-load pre-marshalling problem as an example case. We propose the Contextual Evolution of Heuristics (CEoH) framework, an extension of the Evolution of Heuristics (EoH) framework, which incorporates problem-specific descriptions to enhance in-context learning during heuristic generation. Through computational experiments, we evaluate CEoH and EoH and compare the results. Results indicate that CEoH enables smaller LLMs to generate high-quality heuristics more consistently and even outperform larger models. Larger models demonstrate robust performance with or without contextualized prompts. The generated heuristics exhibit scalability to diverse instance configurations.
TAMPAR: Visual Tampering Detection for Parcel Logistics in Postal Supply Chains
Nov 06, 2023



Due to the steadily rising amount of valuable goods in supply chains, tampering detection for parcels is becoming increasingly important. In this work, we focus on the use-case last-mile delivery, where only a single RGB image is taken and compared against a reference from an existing database to detect potential appearance changes that indicate tampering. We propose a tampering detection pipeline that utilizes keypoint detection to identify the eight corner points of a parcel. This permits applying a perspective transformation to create normalized fronto-parallel views for each visible parcel side surface. These viewpoint-invariant parcel side surface representations facilitate the identification of signs of tampering on parcels within the supply chain, since they reduce the problem to parcel side surface matching with pair-wise appearance change detection. Experiments with multiple classical and deep learning-based change detection approaches are performed on our newly collected TAMpering detection dataset for PARcels, called TAMPAR. We evaluate keypoint and change detection separately, as well as in a unified system for tampering detection. Our evaluation shows promising results for keypoint (Keypoint AP 75.76) and tampering detection (81% accuracy, F1-Score 0.83) on real images. Furthermore, a sensitivity analysis for tampering types, lens distortion and viewing angles is presented. Code and dataset are available at https://a-nau.github.io/tampar.
Parcel3D: Shape Reconstruction from Single RGB Images for Applications in Transportation Logistics
Apr 18, 2023



We focus on enabling damage and tampering detection in logistics and tackle the problem of 3D shape reconstruction of potentially damaged parcels. As input we utilize single RGB images, which corresponds to use-cases where only simple handheld devices are available, e.g. for postmen during delivery or clients on delivery. We present a novel synthetic dataset, named Parcel3D, that is based on the Google Scanned Objects (GSO) dataset and consists of more than 13,000 images of parcels with full 3D annotations. The dataset contains intact, i.e. cuboid-shaped, parcels and damaged parcels, which were generated in simulations. We work towards detecting mishandling of parcels by presenting a novel architecture called CubeRefine R-CNN, which combines estimating a 3D bounding box with an iterative mesh refinement. We benchmark our approach on Parcel3D and an existing dataset of cuboid-shaped parcels in real-world scenarios. Our results show, that while training on Parcel3D enables transfer to the real world, enabling reliable deployment in real-world scenarios is still challenging. CubeRefine R-CNN yields competitive performance in terms of Mesh AP and is the only model that directly enables deformation assessment by 3D mesh comparison and tampering detection by comparing viewpoint invariant parcel side surface representations. Dataset and code are available at https://a-nau.github.io/parcel3d.
Scrape, Cut, Paste and Learn: Automated Dataset Generation Applied to Parcel Logistics
Oct 18, 2022


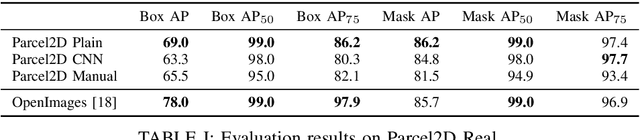
State-of-the-art approaches in computer vision heavily rely on sufficiently large training datasets. For real-world applications, obtaining such a dataset is usually a tedious task. In this paper, we present a fully automated pipeline to generate a synthetic dataset for instance segmentation in four steps. In contrast to existing work, our pipeline covers every step from data acquisition to the final dataset. We first scrape images for the objects of interest from popular image search engines and since we rely only on text-based queries the resulting data comprises a wide variety of images. Hence, image selection is necessary as a second step. This approach of image scraping and selection relaxes the need for a real-world domain-specific dataset that must be either publicly available or created for this purpose. We employ an object-agnostic background removal model and compare three different methods for image selection: Object-agnostic pre-processing, manual image selection and CNN-based image selection. In the third step, we generate random arrangements of the object of interest and distractors on arbitrary backgrounds. Finally, the composition of the images is done by pasting the objects using four different blending methods. We present a case study for our dataset generation approach by considering parcel segmentation. For the evaluation we created a dataset of parcel photos that were annotated automatically. We find that (1) our dataset generation pipeline allows a successful transfer to real test images (Mask AP 86.2), (2) a very accurate image selection process - in contrast to human intuition - is not crucial and a broader category definition can help to bridge the domain gap, (3) the usage of blending methods is beneficial compared to simple copy-and-paste. We made our full code for scraping, image composition and training publicly available at https://a-nau.github.io/parcel2d.
TetraPackNet: Four-Corner-Based Object Detection in Logistics Use-Cases
Apr 19, 2021



While common image object detection tasks focus on bounding boxes or segmentation masks as object representations, we propose a novel method, named TetraPackNet, using fourcorner based object representations. TetraPackNet is inspired by and based on CornerNet and uses similar base algorithms and ideas. It is designated for applications were the high-accuracy detection of regularly shaped objects is crucial, which is the case in the logistics use-case of packaging structure recognition. We evaluate our model on our specific real-world dataset for this use-case. Baselined against a previous solution, consisting of a a Mask R-CNN model and suitable post-processing steps, TetraPackNet achieves superior results (6% higher in accuracy) in the application of four-corner based transport unit side detection.
An Image Processing Pipeline for Automated Packaging Structure Recognition
Sep 29, 2020
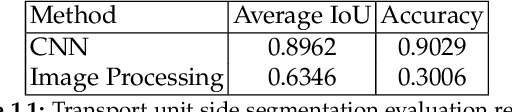


Dispatching and receiving logistics goods, as well as transportation itself, involve a high amount of manual efforts. The transported goods, including their packaging and labeling, need to be double-checked, verified or recognized at many supply chain network points. These processes hold automation potentials, which we aim to exploit using computer vision techniques. More precisely, we propose a cognitive system for the fully automated recognition of packaging structures for standardized logistics shipments based on single RGB images. Our contribution contains descriptions of a suitable system design and its evaluation on relevant real-world data. Further, we discuss our algorithmic choices.
Fully-Automated Packaging Structure Recognition in Logistics Environments
Aug 11, 2020


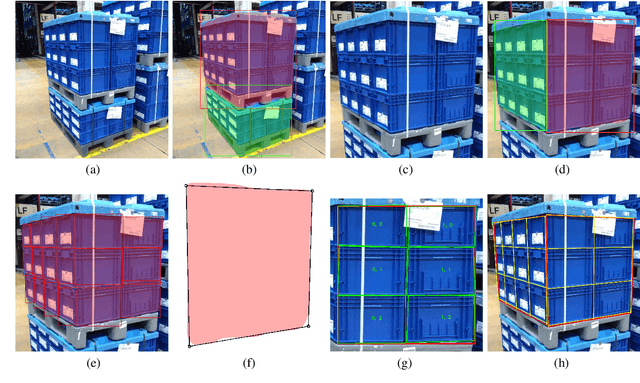
Within a logistics supply chain, a large variety of transported goods need to be handled, recognized and checked at many different network points. Often, huge manual effort is involved in recognizing or verifying packet identity or packaging structure, for instance to check the delivery for completeness. We propose a method for complete automation of packaging structure recognition: Based on a single image, one or multiple transport units are localized and, for each of these transport units, the characteristics, the total number and the arrangement of its packaging units is recognized. Our algorithm is based on deep learning models, more precisely convolutional neural networks for instance segmentation in images, as well as computer vision methods and heuristic components. We use a custom data set of realistic logistics images for training and evaluation of our method. We show that the solution is capable of correctly recognizing the packaging structure in approximately 85% of our test cases, and even more (91%) when focusing on most common package types.
Refined Plane Segmentation for Cuboid-Shaped Objects by Leveraging Edge Detection
Mar 28, 2020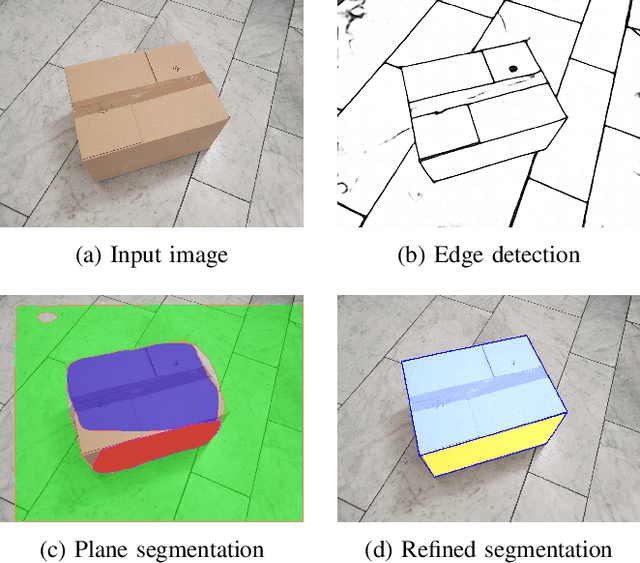


Recent advances in the area of plane segmentation from single RGB images show strong accuracy improvements and now allow a reliable segmentation of indoor scenes into planes. Nonetheless, fine-grained details of these segmentation masks are still lacking accuracy, thus restricting the usability of such techniques on a larger scale in numerous applications, such as inpainting for Augmented Reality use cases. We propose a post-processing algorithm to align the segmented plane masks with edges detected in the image. This allows us to increase the accuracy of state-of-the-art approaches, while limiting ourselves to cuboid-shaped objects. Our approach is motivated by logistics, where this assumption is valid and refined planes can be used to perform robust object detection without the need for supervised learning. Results for two baselines and our approach are reported on our own dataset, which we made publicly available. The results show a consistent improvement over the state-of-the-art. The influence of the prior segmentation and the edge detection is investigated and finally, areas for future research are proposed.