 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Tracking by Detection with Visual and Motion Cues
Jan 19, 2021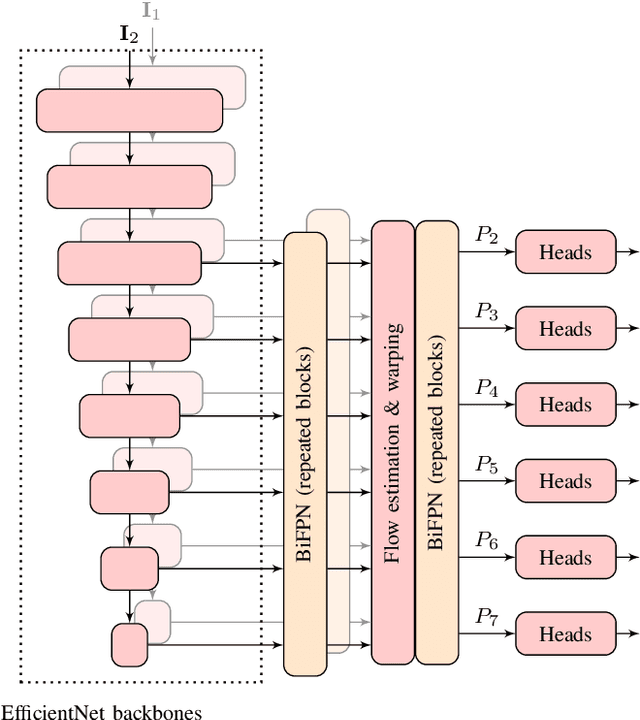
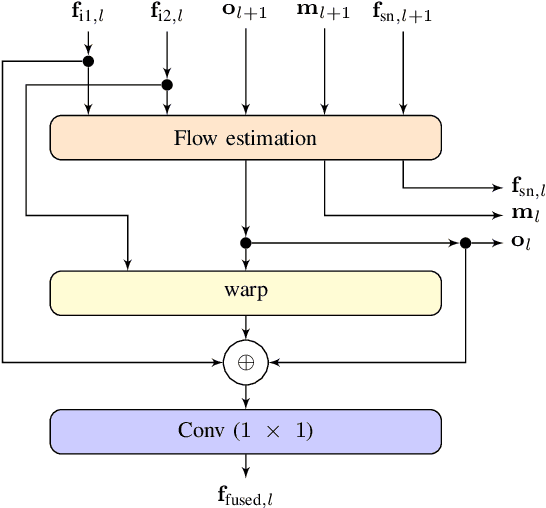

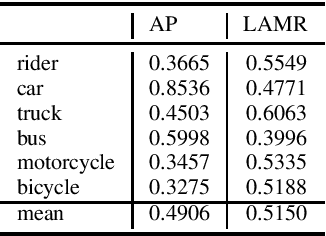
Self-driving cars and other autonomous vehicles need to detect and track objects in camera images. We present a simple online tracking algorithm that is based on a constant velocity motion model with a Kalman filter, and an assignment heuristic. The assignment heuristic relies on four metrics: An embedding vector that describes the appearance of objects and can be used to re-identify them, a displacement vector that describes the object movement between two consecutive video frames, the Mahalanobis distance between the Kalman filter states and the new detections, and a class distance. These metrics are combined with a linear SVM, and then the assignment problem is solved by the Hungarian algorithm. We also propose an efficient CNN architecture that estimates these metrics. Our multi-frame model accepts two consecutive video frames which are processed individually in the backbone, and then optical flow is estimated on the resulting feature maps. This allows the network heads to estimate the displacement vectors. We evaluate our approach on the challenging BDD100K tracking dataset. Our multi-frame model achieves a good MOTA value of 39.1% with low localization error of 0.206 in MOTP. Our fast single-frame model achieves an even lower localization error of 0.202 in MOTP, and a MOTA value of 36.8%.
Refined Plane Segmentation for Cuboid-Shaped Objects by Leveraging Edge Detection
Mar 28, 2020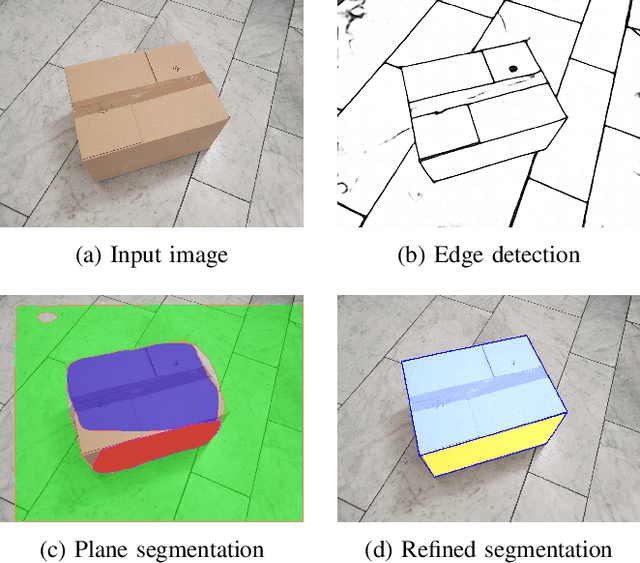


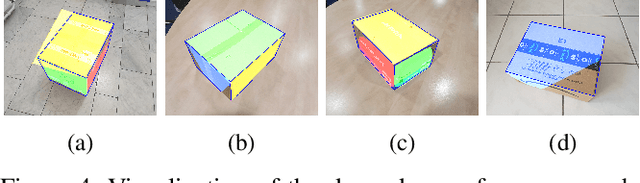
Recent advances in the area of plane segmentation from single RGB images show strong accuracy improvements and now allow a reliable segmentation of indoor scenes into planes. Nonetheless, fine-grained details of these segmentation masks are still lacking accuracy, thus restricting the usability of such techniques on a larger scale in numerous applications, such as inpainting for Augmented Reality use cases. We propose a post-processing algorithm to align the segmented plane masks with edges detected in the image. This allows us to increase the accuracy of state-of-the-art approaches, while limiting ourselves to cuboid-shaped objects. Our approach is motivated by logistics, where this assumption is valid and refined planes can be used to perform robust object detection without the need for supervised learning. Results for two baselines and our approach are reported on our own dataset, which we made publicly available. The results show a consistent improvement over the state-of-the-art. The influence of the prior segmentation and the edge detection is investigated and finally, areas for future research are proposed.
FeatureNMS: Non-Maximum Suppression by Learning Feature Embeddings
Feb 18, 2020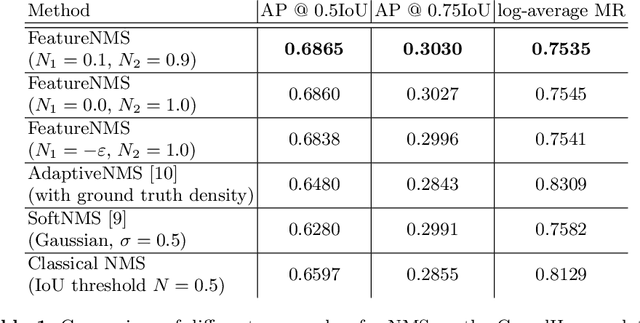
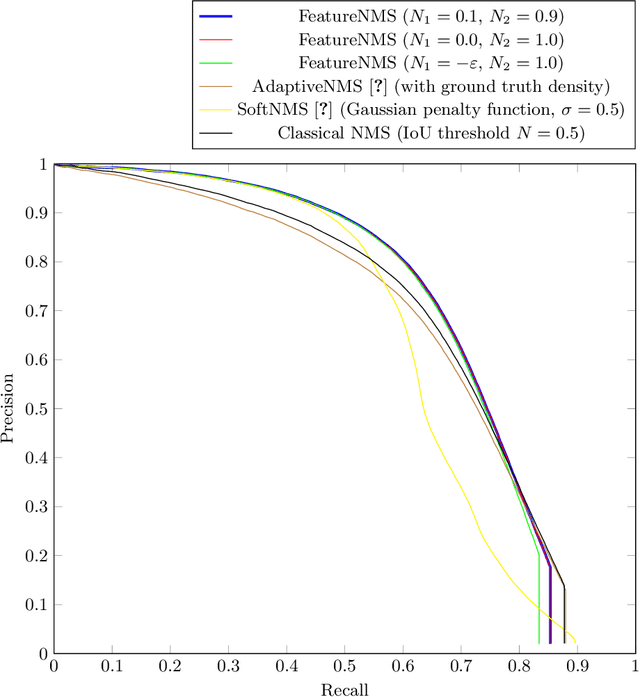

Most state of the art object detectors output multiple detections per object. The duplicates are removed in a post-processing step called Non-Maximum Suppression. Classical Non-Maximum Suppression has shortcomings in scenes that contain objects with high overlap: The idea of this heuristic is that a high bounding box overlap corresponds to a high probability of having a duplicate. We propose FeatureNMS to solve this problem. FeatureNMS recognizes duplicates not only based on the intersection over union between bounding boxes, but also based on the difference of feature vectors. These feature vectors can encode more information like visual appearance. Our approach outperforms classical NMS and derived approaches and achieves state of the art performance.
Simultaneous Object Detection and Semantic Segmentation
May 06, 2019



Both object detection in and semantic segmentation of camera images are important tasks for automated vehicles. Object detection is necessary so that the planning and behavior modules can reason about other road users. Semantic segmentation provides for example free space information and information about static and dynamic parts of the environment. There has been a lot of research to solve both tasks using Convolutional Neural Networks. These approaches give good results but are computationally demanding. In practice, a compromise has to be found between detection performance, detection quality and the number of tasks. Otherwise it is not possible to meet the real-time requirements of automated vehicles. In this work, we propose a neural network architecture to solve both tasks simultaneously. This architecture was designed to run with around 10 Hz on 1 MP images on current hardware. Our approach achieves a mean IoU of 61.2% for the semantic segmentation task on the challenging Cityscapes benchmark. It also achieves an average precision of 69.3% for cars and 67.7% on the moderate difficulty level of the KITTI benchmark.
Cooperative Motion Planning for Non-Holonomic Agents with Value Iteration Networks
Sep 15, 2017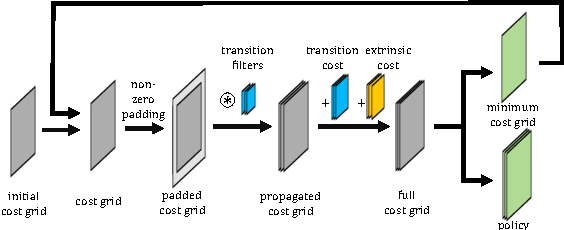
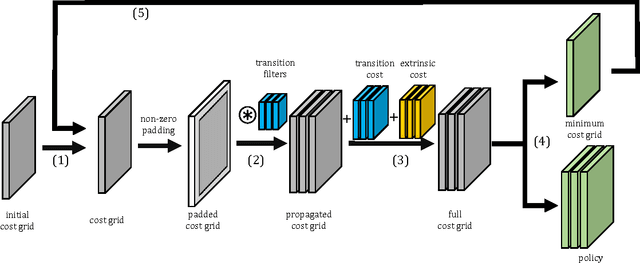
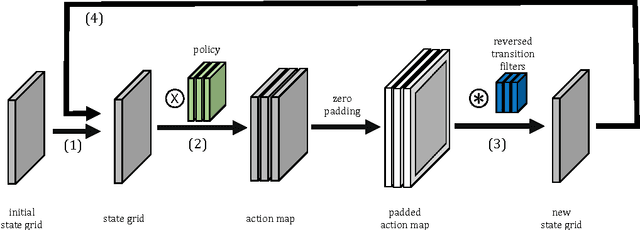
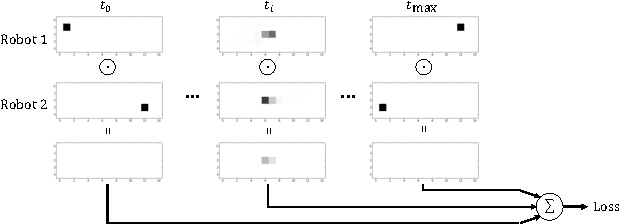
Cooperative motion planning is still a challenging task for robots. Recently, Value Iteration Networks (VINs) were proposed to model motion planning tasks as Neural Networks. In this work, we extend VINs to solve cooperative planning tasks under non-holonomic constraints. For this, we interconnect multiple VINs to pay respect to each other's outputs. Policies for cooperation are generated via iterative gradient descend. Validation in simulation shows that the resulting networks can resolve non-holonomic motion planning problems that require cooperation.