 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Generation of Continuous-Space Roadmaps for Routing Mobile Robot Fleets
Nov 10, 2025



Efficient routing of mobile robot fleets is crucial in intralogistics, where delays and deadlocks can substantially reduce system throughput. Roadmap design, specifying feasible transport routes, directly affects fleet coordination and computational performance. Existing approaches are either grid-based, compromising geometric precision, or continuous-space approaches that disregard practical constraints. This paper presents an automated roadmap generation approach that bridges this gap by operating in continuous-space, integrating station-to-station transport demand and enforcing minimum distance constraints for nodes and edges. By combining free space discretization, transport demand-driven $K$-shortest-path optimization, and path smoothing, the approach produces roadmaps tailored to intralogistics applications. Evaluation across multiple intralogistics use cases demonstrates that the proposed approach consistently outperforms established baselines (4-connected grid, 8-connected grid, and random sampling), achieving lower structural complexity, higher redundancy, and near-optimal path lengths, enabling efficient and robust routing of mobile robot fleets.
FOGMACHINE -- Leveraging Discrete-Event Simulation and Scene Graphs for Modeling Hierarchical, Interconnected Environments under Partial Observations from Mobile Agents
Oct 10, 2025Dynamic Scene Graphs (DSGs) provide a structured representation of hierarchical, interconnected environments, but current approaches struggle to capture stochastic dynamics, partial observability, and multi-agent activity. These aspects are critical for embodied AI, where agents must act under uncertainty and delayed perception. We introduce FOGMACHINE , an open-source framework that fuses DSGs with discrete-event simulation to model object dynamics, agent observations, and interactions at scale. This setup enables the study of uncertainty propagation, planning under limited perception, and emergent multi-agent behavior. Experiments in urban scenarios illustrate realistic temporal and spatial patterns while revealing the challenges of belief estimation under sparse observations. By combining structured representations with efficient simulation, FOGMACHINE establishes an effective tool for benchmarking, model training, and advancing embodied AI in complex, uncertain environments.
TAMPAR: Visual Tampering Detection for Parcel Logistics in Postal Supply Chains
Nov 06, 2023



Due to the steadily rising amount of valuable goods in supply chains, tampering detection for parcels is becoming increasingly important. In this work, we focus on the use-case last-mile delivery, where only a single RGB image is taken and compared against a reference from an existing database to detect potential appearance changes that indicate tampering. We propose a tampering detection pipeline that utilizes keypoint detection to identify the eight corner points of a parcel. This permits applying a perspective transformation to create normalized fronto-parallel views for each visible parcel side surface. These viewpoint-invariant parcel side surface representations facilitate the identification of signs of tampering on parcels within the supply chain, since they reduce the problem to parcel side surface matching with pair-wise appearance change detection. Experiments with multiple classical and deep learning-based change detection approaches are performed on our newly collected TAMpering detection dataset for PARcels, called TAMPAR. We evaluate keypoint and change detection separately, as well as in a unified system for tampering detection. Our evaluation shows promising results for keypoint (Keypoint AP 75.76) and tampering detection (81% accuracy, F1-Score 0.83) on real images. Furthermore, a sensitivity analysis for tampering types, lens distortion and viewing angles is presented. Code and dataset are available at https://a-nau.github.io/tampar.
Parcel3D: Shape Reconstruction from Single RGB Images for Applications in Transportation Logistics
Apr 18, 2023



We focus on enabling damage and tampering detection in logistics and tackle the problem of 3D shape reconstruction of potentially damaged parcels. As input we utilize single RGB images, which corresponds to use-cases where only simple handheld devices are available, e.g. for postmen during delivery or clients on delivery. We present a novel synthetic dataset, named Parcel3D, that is based on the Google Scanned Objects (GSO) dataset and consists of more than 13,000 images of parcels with full 3D annotations. The dataset contains intact, i.e. cuboid-shaped, parcels and damaged parcels, which were generated in simulations. We work towards detecting mishandling of parcels by presenting a novel architecture called CubeRefine R-CNN, which combines estimating a 3D bounding box with an iterative mesh refinement. We benchmark our approach on Parcel3D and an existing dataset of cuboid-shaped parcels in real-world scenarios. Our results show, that while training on Parcel3D enables transfer to the real world, enabling reliable deployment in real-world scenarios is still challenging. CubeRefine R-CNN yields competitive performance in terms of Mesh AP and is the only model that directly enables deformation assessment by 3D mesh comparison and tampering detection by comparing viewpoint invariant parcel side surface representations. Dataset and code are available at https://a-nau.github.io/parcel3d.
Literature Review: Computer Vision Applications in Transportation Logistics and Warehousing
Apr 12, 2023
Computer vision applications in transportation logistics and warehousing have a huge potential for process automation. We present a structured literature review on research in the field to help leverage this potential. All literature is categorized w.r.t. the application, i.e. the task it tackles and w.r.t. the computer vision techniques that are used. Regarding applications, we subdivide the literature in two areas: Monitoring, i.e. observing and retrieving relevant information from the environment, and manipulation, where approaches are used to analyze and interact with the environment. In addition to that, we point out directions for future research and link to recent developments in computer vision that are suitable for application in logistics. Finally, we present an overview of existing datasets and industrial solutions. We conclude that while already many research areas have been investigated, there is still huge potential for future research. The results of our analysis are also available online at https://a-nau.github.io/cv-in-logistics.
MotorFactory: A Blender Add-on for Large Dataset Generation of Small Electric Motors
Jan 11, 2023



To enable automatic disassembly of different product types with uncertain conditions and degrees of wear in remanufacturing, agile production systems that can adapt dynamically to changing requirements are needed. Machine learning algorithms can be employed due to their generalization capabilities of learning from various types and variants of products. However, in reality, datasets with a diversity of samples that can be used to train models are difficult to obtain in the initial period. This may cause bad performances when the system tries to adapt to new unseen input data in the future. In order to generate large datasets for different learning purposes, in our project, we present a Blender add-on named MotorFactory to generate customized mesh models of various motor instances. MotorFactory allows to create mesh models which, complemented with additional add-ons, can be further used to create synthetic RGB images, depth images, normal images, segmentation ground truth masks, and 3D point cloud datasets with point-wise semantic labels. The created synthetic datasets may be used for various tasks including motor type classification, object detection for decentralized material transfer tasks, part segmentation for disassembly and handling tasks, or even reinforcement learning-based robotics control or view-planning.
Scrape, Cut, Paste and Learn: Automated Dataset Generation Applied to Parcel Logistics
Oct 18, 2022


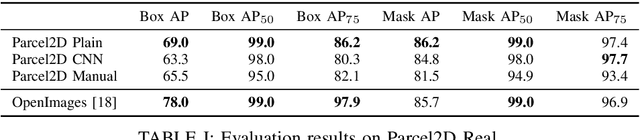
State-of-the-art approaches in computer vision heavily rely on sufficiently large training datasets. For real-world applications, obtaining such a dataset is usually a tedious task. In this paper, we present a fully automated pipeline to generate a synthetic dataset for instance segmentation in four steps. In contrast to existing work, our pipeline covers every step from data acquisition to the final dataset. We first scrape images for the objects of interest from popular image search engines and since we rely only on text-based queries the resulting data comprises a wide variety of images. Hence, image selection is necessary as a second step. This approach of image scraping and selection relaxes the need for a real-world domain-specific dataset that must be either publicly available or created for this purpose. We employ an object-agnostic background removal model and compare three different methods for image selection: Object-agnostic pre-processing, manual image selection and CNN-based image selection. In the third step, we generate random arrangements of the object of interest and distractors on arbitrary backgrounds. Finally, the composition of the images is done by pasting the objects using four different blending methods. We present a case study for our dataset generation approach by considering parcel segmentation. For the evaluation we created a dataset of parcel photos that were annotated automatically. We find that (1) our dataset generation pipeline allows a successful transfer to real test images (Mask AP 86.2), (2) a very accurate image selection process - in contrast to human intuition - is not crucial and a broader category definition can help to bridge the domain gap, (3) the usage of blending methods is beneficial compared to simple copy-and-paste. We made our full code for scraping, image composition and training publicly available at https://a-nau.github.io/parcel2d.
Refined Plane Segmentation for Cuboid-Shaped Objects by Leveraging Edge Detection
Mar 28, 2020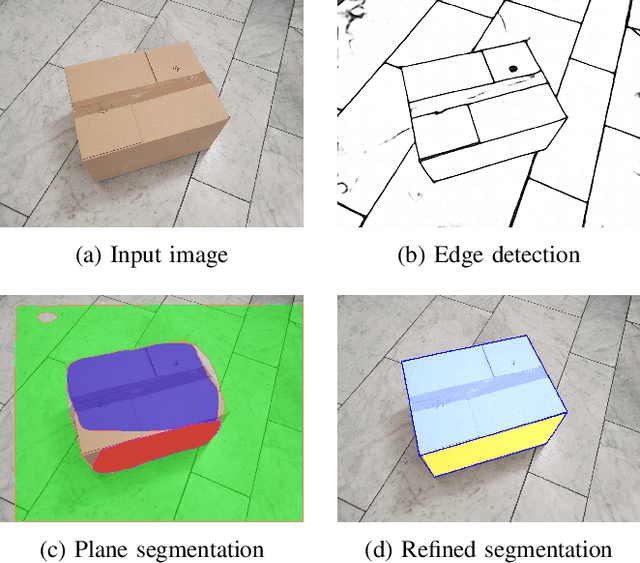


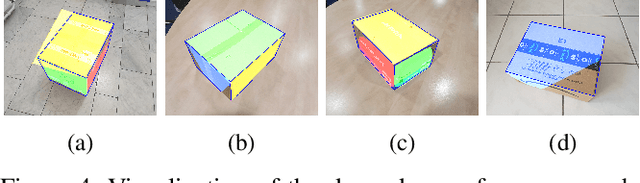
Recent advances in the area of plane segmentation from single RGB images show strong accuracy improvements and now allow a reliable segmentation of indoor scenes into planes. Nonetheless, fine-grained details of these segmentation masks are still lacking accuracy, thus restricting the usability of such techniques on a larger scale in numerous applications, such as inpainting for Augmented Reality use cases. We propose a post-processing algorithm to align the segmented plane masks with edges detected in the image. This allows us to increase the accuracy of state-of-the-art approaches, while limiting ourselves to cuboid-shaped objects. Our approach is motivated by logistics, where this assumption is valid and refined planes can be used to perform robust object detection without the need for supervised learning. Results for two baselines and our approach are reported on our own dataset, which we made publicly available. The results show a consistent improvement over the state-of-the-art. The influence of the prior segmentation and the edge detection is investigated and finally, areas for future research are proposed.