 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA data-driven approach to linking design features with manufacturing process data for sustainable product development
Dec 10, 2025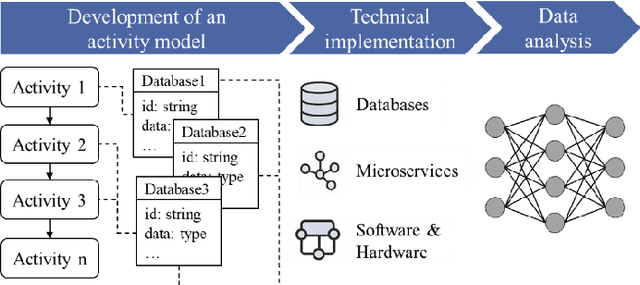
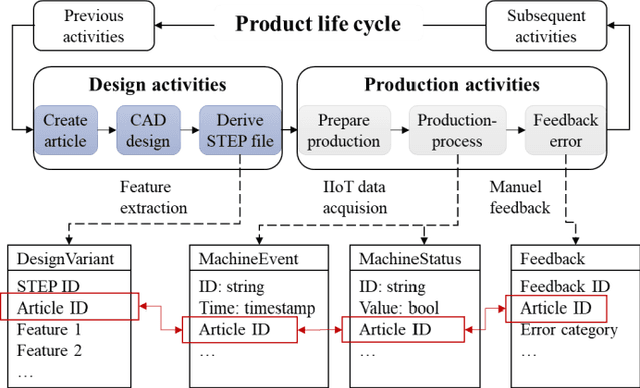
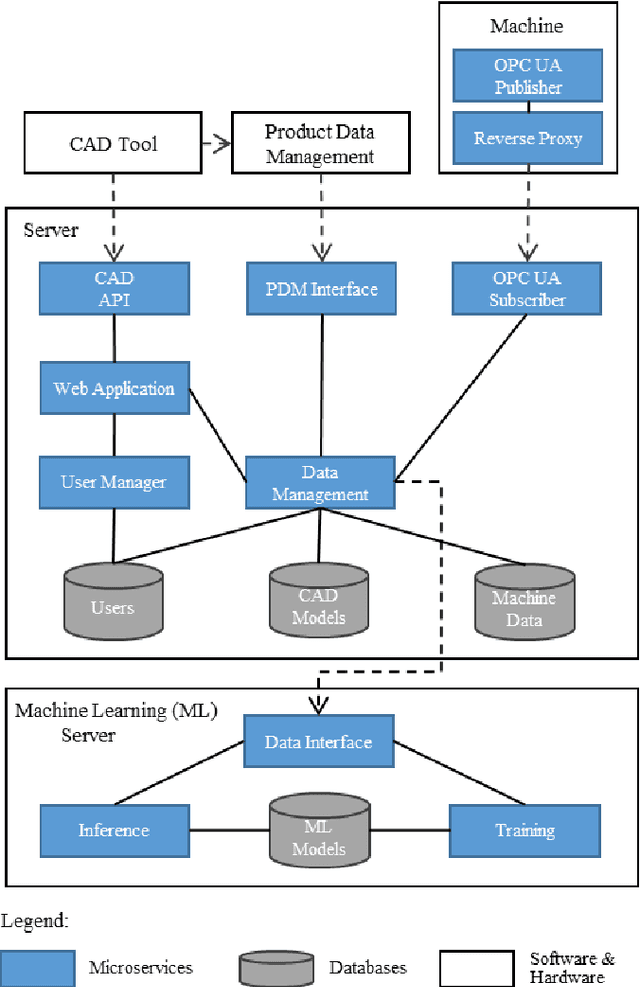
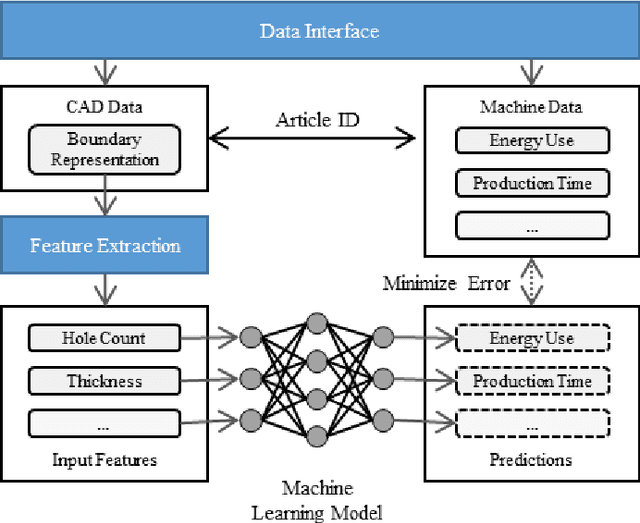
The growing adoption of Industrial Internet of Things (IIoT) technologies enables automated, real-time collection of manufacturing process data, unlocking new opportunities for data-driven product development. Current data-driven methods are generally applied within specific domains, such as design or manufacturing, with limited exploration of integrating design features and manufacturing process data. Since design decisions significantly affect manufacturing outcomes, such as error rates, energy consumption, and processing times, the lack of such integration restricts the potential for data-driven product design improvements. This paper presents a data-driven approach to mapping and analyzing the relationship between design features and manufacturing process data. A comprehensive system architecture is developed to ensure continuous data collection and integration. The linkage between design features and manufacturing process data serves as the basis for developing a machine learning model that enables automated design improvement suggestions. By integrating manufacturing process data with sustainability metrics, this approach opens new possibilities for sustainable product development.
CodeSCAN: ScreenCast ANalysis for Video Programming Tutorials
Sep 27, 2024Programming tutorials in the form of coding screencasts play a crucial role in programming education, serving both novices and experienced developers. However, the video format of these tutorials presents a challenge due to the difficulty of searching for and within videos. Addressing the absence of large-scale and diverse datasets for screencast analysis, we introduce the CodeSCAN dataset. It comprises 12,000 screenshots captured from the Visual Studio Code environment during development, featuring 24 programming languages, 25 fonts, and over 90 distinct themes, in addition to diverse layout changes and realistic user interactions. Moreover, we conduct detailed quantitative and qualitative evaluations to benchmark the performance of Integrated Development Environment (IDE) element detection, color-to-black-and-white conversion, and Optical Character Recognition (OCR). We hope that our contributions facilitate more research in coding screencast analysis, and we make the source code for creating the dataset and the benchmark publicly available on this website.
XTSC-Bench: Quantitative Benchmarking for Explainers on Time Series Classification
Oct 23, 2023Despite the growing body of work on explainable machine learning in time series classification (TSC), it remains unclear how to evaluate different explainability methods. Resorting to qualitative assessment and user studies to evaluate explainers for TSC is difficult since humans have difficulties understanding the underlying information contained in time series data. Therefore, a systematic review and quantitative comparison of explanation methods to confirm their correctness becomes crucial. While steps to standardized evaluations were taken for tabular, image, and textual data, benchmarking explainability methods on time series is challenging due to a) traditional metrics not being directly applicable, b) implementation and adaption of traditional metrics for time series in the literature vary, and c) varying baseline implementations. This paper proposes XTSC-Bench, a benchmarking tool providing standardized datasets, models, and metrics for evaluating explanation methods on TSC. We analyze 3 perturbation-, 6 gradient- and 2 example-based explanation methods to TSC showing that improvements in the explainers' robustness and reliability are necessary, especially for multivariate data.
TSInterpret: A unified framework for time series interpretability
Aug 15, 2022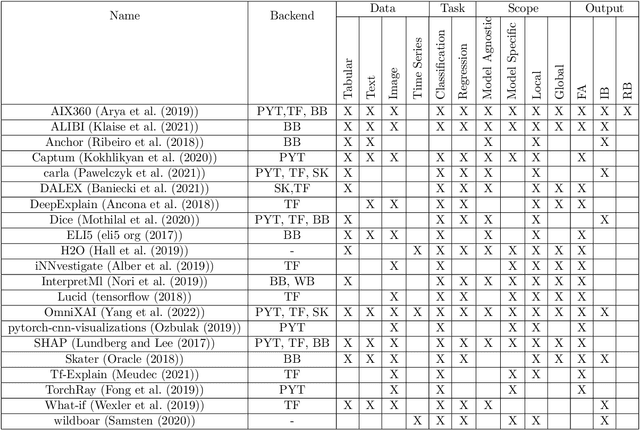
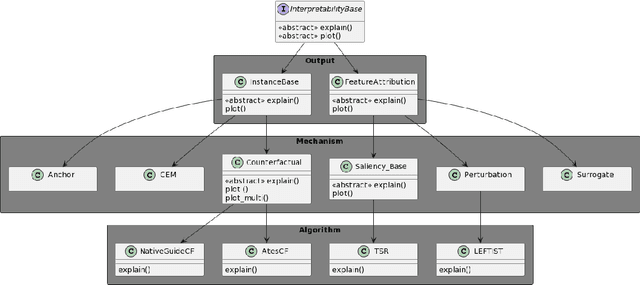

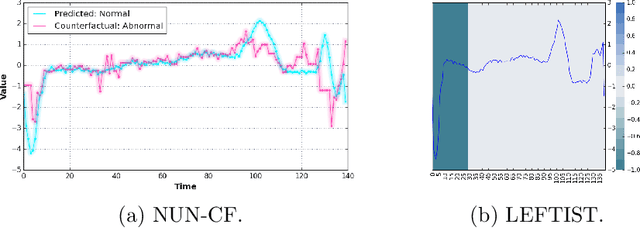
With the increasing application of deep learning algorithms to time series classification, especially in high-stake scenarios, the relevance of interpreting those algorithms becomes key. Although research in time series interpretability has grown, accessibility for practitioners is still an obstacle. Interpretability approaches and their visualizations are diverse in use without a unified API or framework. To close this gap, we introduce TSInterpret an easily extensible open-source Python library for interpreting predictions of time series classifiers that combines existing interpretation approaches into one unified framework. The library features (i) state-of-the-art interpretability algorithms, (ii) exposes a unified API enabling users to work with explanations consistently and provides (iii) suitable visualizations for each explanation.