 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnraveling the Impact of Visual Complexity on Search as Learning
Jan 09, 2025
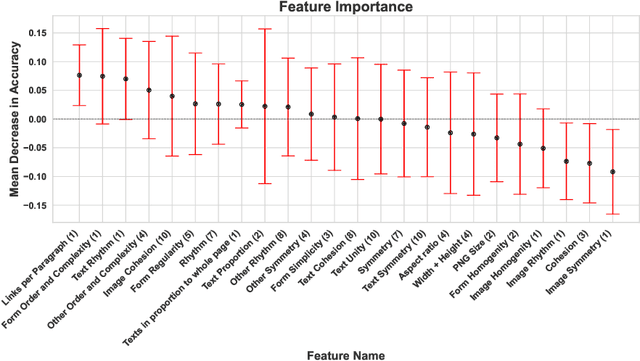
Information search has become essential for learning and knowledge acquisition, offering broad access to information and learning resources. The visual complexity of web pages is known to influence search behavior, with previous work suggesting that searchers make evaluative judgments within the first second on a page. However, there is a significant gap in our understanding of how visual complexity impacts searches specifically conducted with a learning intent. This gap is particularly relevant for the development of optimized information retrieval (IR) systems that effectively support educational objectives. To address this research need, we model visual complexity and aesthetics via a diverse set of features, investigating their relationship with search behavior during learning-oriented web sessions. Our study utilizes a publicly available dataset from a lab study where participants learned about thunderstorm formation. Our findings reveal that while content relevance is the most significant predictor for knowledge gain, sessions with less visually complex pages are associated with higher learning success. This observation applies to features associated with the layout of web pages rather than to simpler features (e.g., number of images). The reported results shed light on the impact of visual complexity on learning-oriented searches, informing the design of more effective IR systems for educational contexts. To foster reproducibility, we release our source code (https://github.com/TIBHannover/sal_visual_complexity).
On the Influence of Reading Sequences on Knowledge Gain during Web Search
Jan 10, 2024Nowadays, learning increasingly involves the usage of search engines and web resources. The related interdisciplinary research field search as learning aims to understand how people learn on the web. Previous work has investigated several feature classes to predict, for instance, the expected knowledge gain during web search. Therein, eye-tracking features have not been extensively studied so far. In this paper, we extend a previously used reading model from a line-based one to one that can detect reading sequences across multiple lines. We use publicly available study data from a web-based learning task to examine the relationship between our feature set and the participants' test scores. Our findings demonstrate that learners with higher knowledge gain spent significantly more time reading, and processing more words in total. We also find evidence that faster reading at the expense of more backward regressions may be an indicator of better web-based learning. We make our code publicly available at https://github.com/TIBHannover/reading_web_search.
SaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022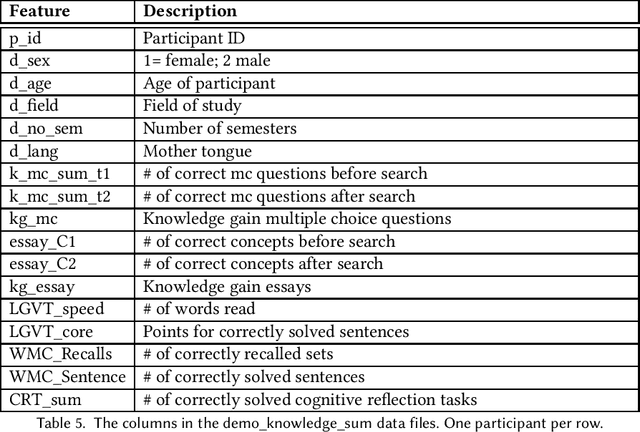
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.
Extraction of Positional Player Data from Broadcast Soccer Videos
Oct 21, 2021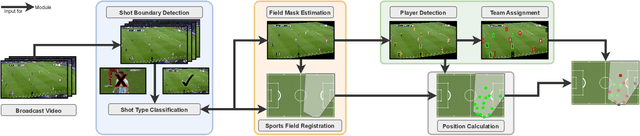

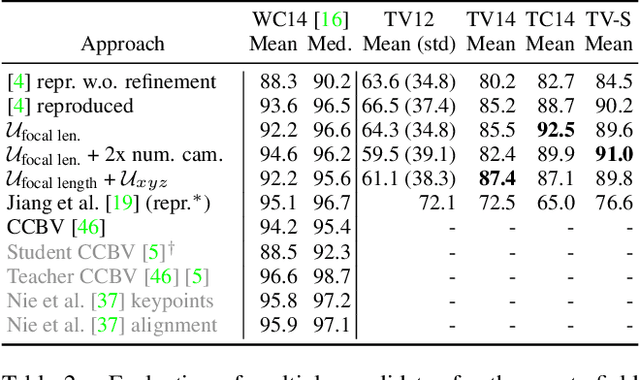
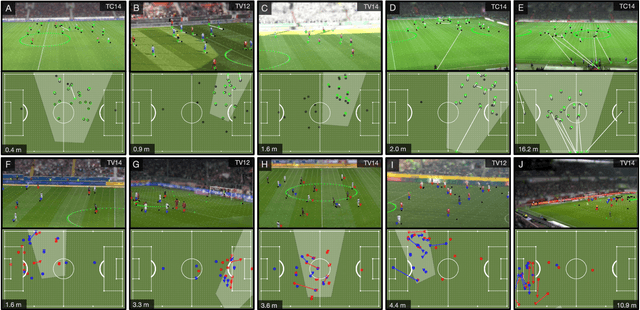
Computer-aided support and analysis are becoming increasingly important in the modern world of sports. The scouting of potential prospective players, performance as well as match analysis, and the monitoring of training programs rely more and more on data-driven technologies to ensure success. Therefore, many approaches require large amounts of data, which are, however, not easy to obtain in general. In this paper, we propose a pipeline for the fully-automated extraction of positional data from broadcast video recordings of soccer matches. In contrast to previous work, the system integrates all necessary sub-tasks like sports field registration, player detection, or team assignment that are crucial for player position estimation. The quality of the modules and the entire system is interdependent. A comprehensive experimental evaluation is presented for the individual modules as well as the entire pipeline to identify the influence of errors to subsequent modules and the overall result. In this context, we propose novel evaluation metrics to compare the output with ground-truth positional data.