 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.
Predicting Knowledge Gain during Web Search based on Multimedia Resource Consumption
Jun 11, 2021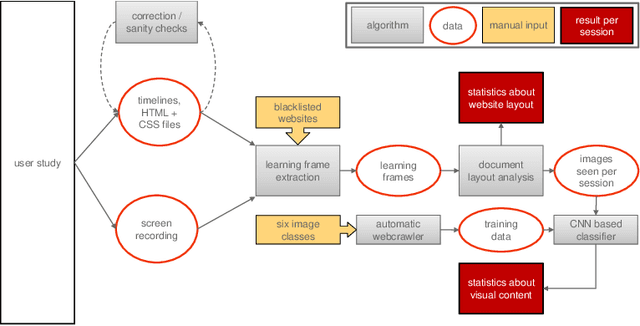
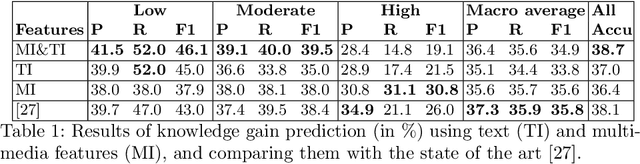
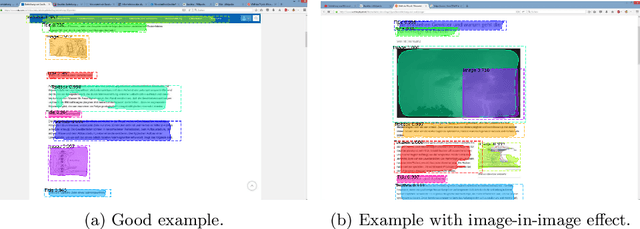
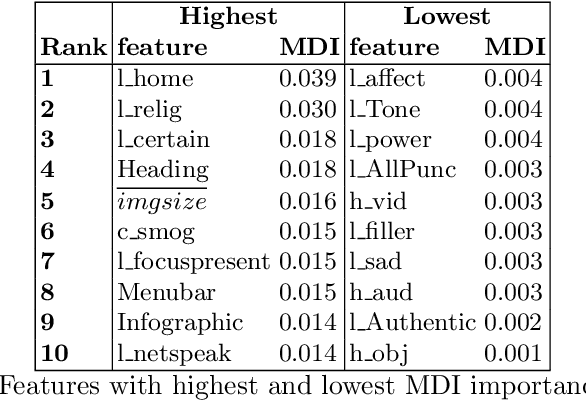
In informal learning scenarios the popularity of multimedia content, such as video tutorials or lectures, has significantly increased. Yet, the users' interactions, navigation behavior, and consequently learning outcome, have not been researched extensively. Related work in this field, also called search as learning, has focused on behavioral or text resource features to predict learning outcome and knowledge gain. In this paper, we investigate whether we can exploit features representing multimedia resource consumption to predict of knowledge gain (KG) during Web search from in-session data, that is without prior knowledge about the learner. For this purpose, we suggest a set of multimedia features related to image and video consumption. Our feature extraction is evaluated in a lab study with 113 participants where we collected data for a given search as learning task on the formation of thunderstorms and lightning. We automatically analyze the monitored log data and utilize state-of-the-art computer vision methods to extract features about the seen multimedia resources. Experimental results demonstrate that multimedia features can improve KG prediction. Finally, we provide an analysis on feature importance (text and multimedia) for KG prediction.
On the Predictability of non-CGM Diabetes Data for Personalized Recommendation
Sep 07, 2018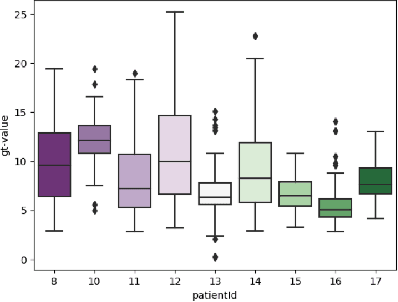
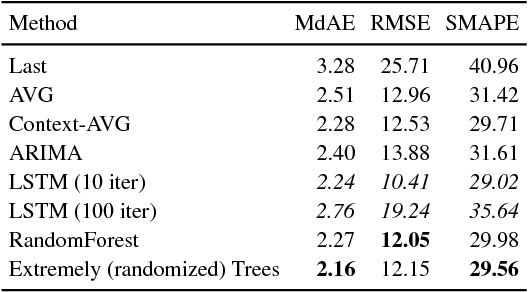
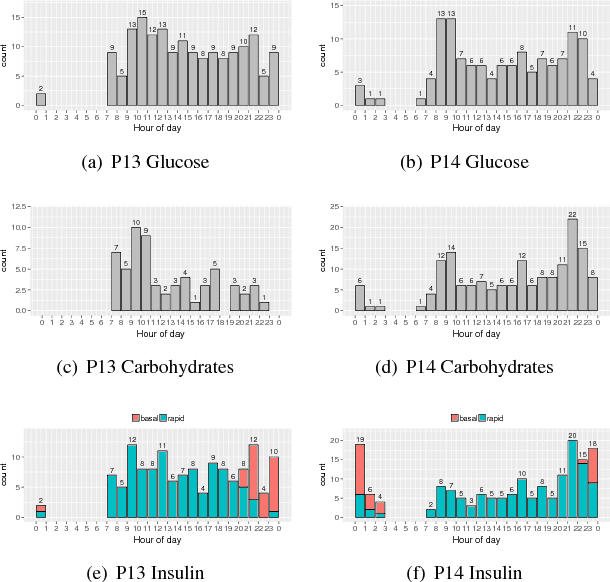
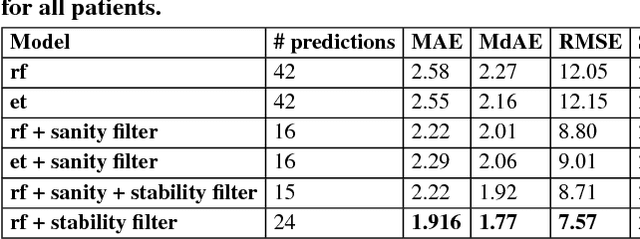
With continuous glucose monitoring (CGM), data-driven models on blood glucose prediction have been shown to be effective in related work. However, such (CGM) systems are not always available, e.g., for a patient at home. In this work, we conduct a study on 9 patients and examine the predictability of data-driven (aka. machine learning) based models on patient-level blood glucose prediction; with measurements are taken only periodically (i.e., after several hours). To this end, we propose several post-prediction methods to account for the noise nature of these data, that marginally improves the performance of the end system.