 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Knowledge Gain for MOOC Video Consumption
Dec 13, 2022Informal learning on the Web using search engines as well as more structured learning on MOOC platforms have become very popular in recent years. As a result of the vast amount of available learning resources, intelligent retrieval and recommendation methods are indispensable -- this is true also for MOOC videos. However, the automatic assessment of this content with regard to predicting (potential) knowledge gain has not been addressed by previous work yet. In this paper, we investigate whether we can predict learning success after MOOC video consumption using 1) multimodal features covering slide and speech content, and 2) a wide range of text-based features describing the content of the video. In a comprehensive experimental setting, we test four different classifiers and various feature subset combinations. We conduct a detailed feature importance analysis to gain insights in which modality benefits knowledge gain prediction the most.
* 13 pages, 1 figure, 3 tables
MM-Claims: A Dataset for Multimodal Claim Detection in Social Media
May 04, 2022
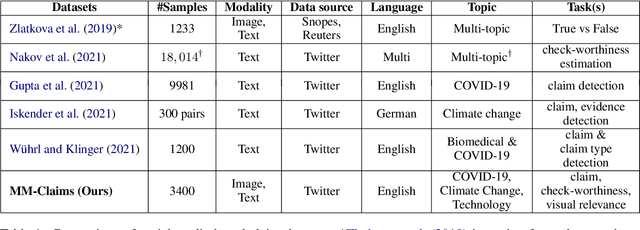
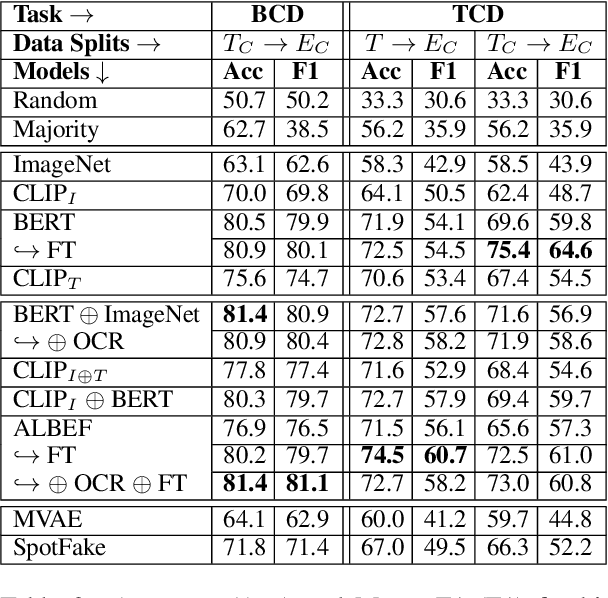
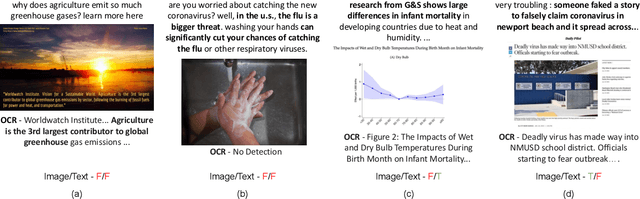
In recent years, the problem of misinformation on the web has become widespread across languages, countries, and various social media platforms. Although there has been much work on automated fake news detection, the role of images and their variety are not well explored. In this paper, we investigate the roles of image and text at an earlier stage of the fake news detection pipeline, called claim detection. For this purpose, we introduce a novel dataset, MM-Claims, which consists of tweets and corresponding images over three topics: COVID-19, Climate Change and broadly Technology. The dataset contains roughly 86000 tweets, out of which 3400 are labeled manually by multiple annotators for the training and evaluation of multimodal models. We describe the dataset in detail, evaluate strong unimodal and multimodal baselines, and analyze the potential and drawbacks of current models.
SaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.
Predicting Knowledge Gain during Web Search based on Multimedia Resource Consumption
Jun 11, 2021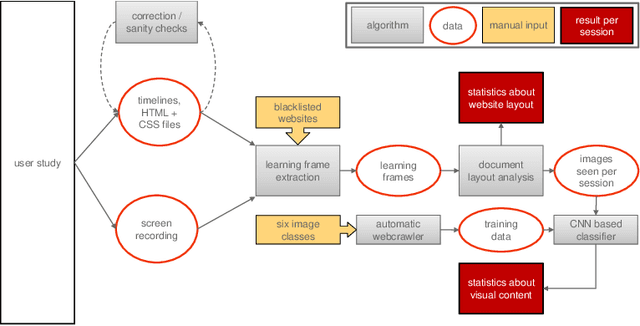
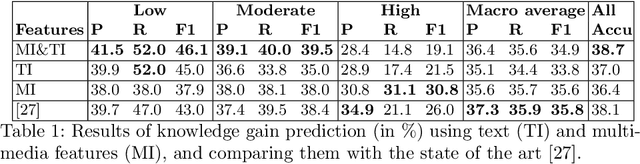
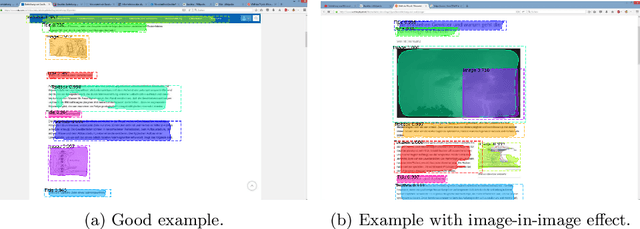
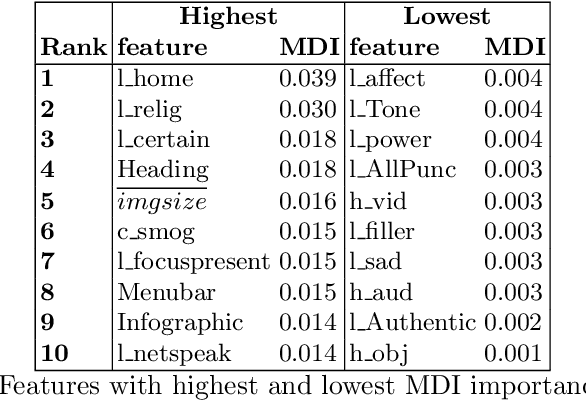
In informal learning scenarios the popularity of multimedia content, such as video tutorials or lectures, has significantly increased. Yet, the users' interactions, navigation behavior, and consequently learning outcome, have not been researched extensively. Related work in this field, also called search as learning, has focused on behavioral or text resource features to predict learning outcome and knowledge gain. In this paper, we investigate whether we can exploit features representing multimedia resource consumption to predict of knowledge gain (KG) during Web search from in-session data, that is without prior knowledge about the learner. For this purpose, we suggest a set of multimedia features related to image and video consumption. Our feature extraction is evaluated in a lab study with 113 participants where we collected data for a given search as learning task on the formation of thunderstorms and lightning. We automatically analyze the monitored log data and utilize state-of-the-art computer vision methods to extract features about the seen multimedia resources. Experimental results demonstrate that multimedia features can improve KG prediction. Finally, we provide an analysis on feature importance (text and multimedia) for KG prediction.
Visual Summarization of Scholarly Videos using Word Embeddings and Keyphrase Extraction
Nov 25, 2019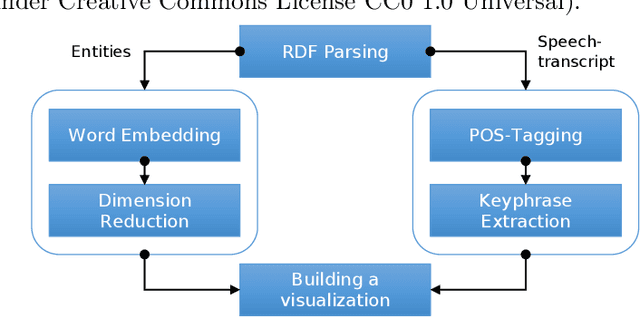


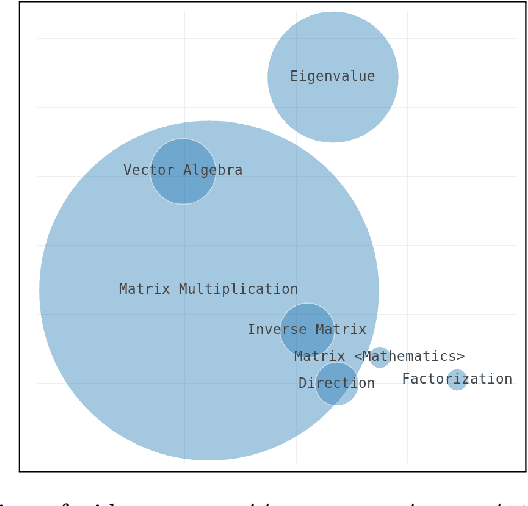
Effective learning with audiovisual content depends on many factors. Besides the quality of the learning resource's content, it is essential to discover the most relevant and suitable video in order to support the learning process most effectively. Video summarization techniques facilitate this goal by providing a quick overview over the content. It is especially useful for longer recordings such as conference presentations or lectures. In this paper, we present an approach that generates a visual summary of video content based on semantic word embeddings and keyphrase extraction. For this purpose, we exploit video annotations that are automatically generated by speech recognition and video OCR (optical character recognition).
"Is this an example image?" -- Predicting the Relative Abstractness Level of Image and Text
Jan 23, 2019
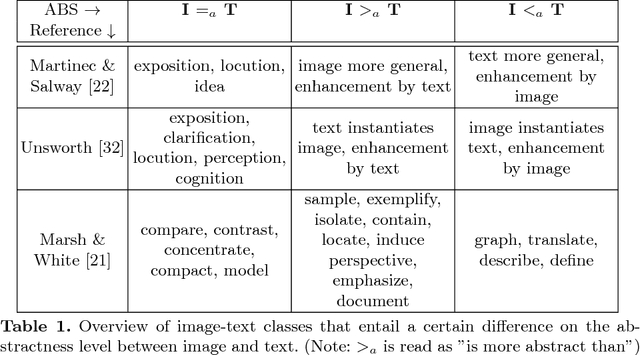

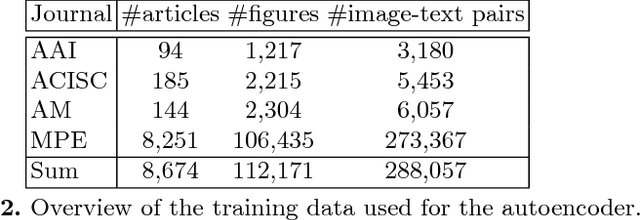
Successful multimodal search and retrieval requires the automatic understanding of semantic cross-modal relations, which, however, is still an open research problem. Previous work has suggested the metrics cross-modal mutual information and semantic correlation to model and predict cross-modal semantic relations of image and text. In this paper, we present an approach to predict the (cross-modal) relative abstractness level of a given image-text pair, that is whether the image is an abstraction of the text or vice versa. For this purpose, we introduce a new metric that captures this specific relationship between image and text at the Abstractness Level (ABS). We present a deep learning approach to predict this metric, which relies on an autoencoder architecture that allows us to significantly reduce the required amount of labeled training data. A comprehensive set of publicly available scientific documents has been gathered. Experimental results on a challenging test set demonstrate the feasibility of the approach.