 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset of Natural Language Queries for E-Commerce
Feb 13, 2023Shopping online is more and more frequent in our everyday life. For e-commerce search systems, understanding natural language coming through voice assistants, chatbots or from conversational search is an essential ability to understand what the user really wants. However, evaluation datasets with natural and detailed information needs of product-seekers which could be used for research do not exist. Due to privacy issues and competitive consequences, only few datasets with real user search queries from logs are openly available. In this paper, we present a dataset of 3,540 natural language queries in two domains that describe what users want when searching for a laptop or a jacket of their choice. The dataset contains annotations of vague terms and key facts of 1,754 laptop queries. This dataset opens up a range of research opportunities in the fields of natural language processing and (interactive) information retrieval for product search.
Evaluation of a Search Interface for Preference-Based Ranking -- Measuring User Satisfaction and System Performance
Feb 13, 2023
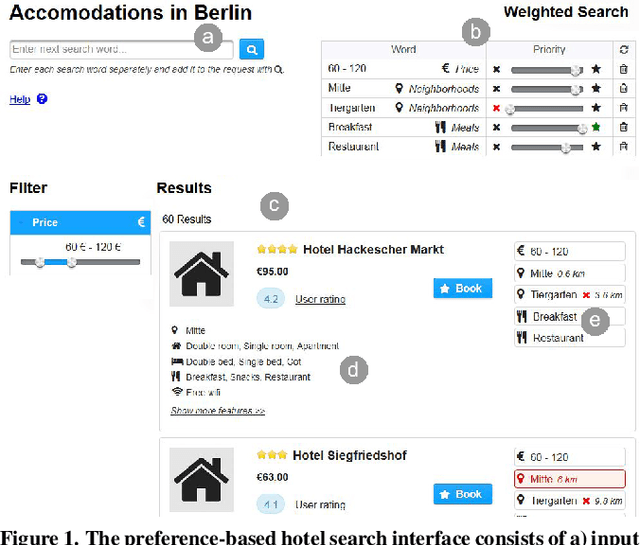
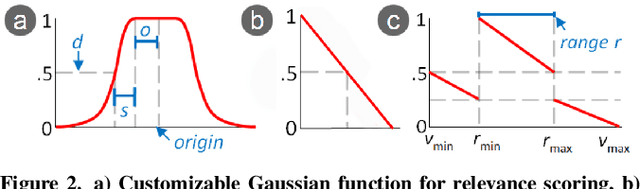
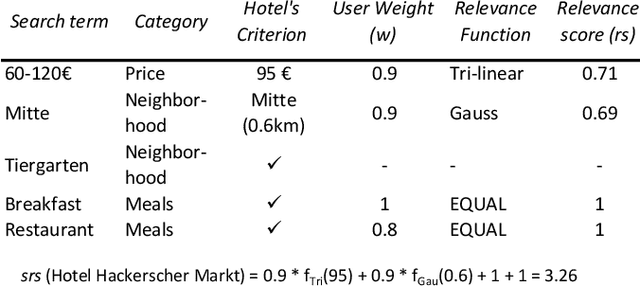
Finding a product online can be a challenging task for users. Faceted search interfaces, often in combination with recommenders, can support users in finding a product that fits their preferences. However, those preferences are not always equally weighted: some might be more important to a user than others (e.g. red is the favorite color, but blue is also fine) and sometimes preferences are even contradictory (e.g. the lowest price vs. the highest performance). Often, there is even no product that meets all preferences. In those cases, faceted search interfaces reach their limits. In our research, we investigate the potential of a search interface, which allows a preference-based ranking based on weighted search and facet terms. We performed a user study with 24 participants and measured user satisfaction and system performance. The results show that with the preference-based search interface the users were given more alternatives that best meet their preferences and that they are more satisfied with the selected product than with a search interface using standard facets. Furthermore, in this work we study the relationship between user satisfaction and search precision within the whole search session and found first indications that there might be a relation between them.
Evaluation of Word Embeddings for the Social Sciences
Feb 13, 2023



Word embeddings are an essential instrument in many NLP tasks. Most available resources are trained on general language from Web corpora or Wikipedia dumps. However, word embeddings for domain-specific language are rare, in particular for the social science domain. Therefore, in this work, we describe the creation and evaluation of word embedding models based on 37,604 open-access social science research papers. In the evaluation, we compare domain-specific and general language models for (i) language coverage, (ii) diversity, and (iii) semantic relationships. We found that the created domain-specific model, even with a relatively small vocabulary size, covers a large part of social science concepts, their neighborhoods are diverse in comparison to more general models. Across all relation types, we found a more extensive coverage of semantic relationships.
UNDR: User-Needs-Driven Ranking of Products in E-Commerce
Feb 13, 2023Online retailers often offer a vast choice of products to their customers to filter and browse through. The order in which the products are listed depends on the ranking algorithm employed in the online shop. State-of-the-art ranking methods are complex and draw on many different information, e.g., user query and intent, product attributes, popularity, recency, reviews, or purchases. However, approaches that incorporate user-generated data such as click-through data, user ratings, or reviews disadvantage new products that have not yet been rated by customers. We therefore propose the User-Needs-Driven Ranking (UNDR) method that accounts for explicit customer needs by using facet popularity and facet value popularity. As a user-centered approach that does not rely on post-purchase ratings or reviews, our method bypasses the cold-start problem while still reflecting the needs of an average customer. In two preliminary user studies, we compare our ranking method with a rating-based ranking baseline. Our findings show that our proposed approach generates a ranking that fits current customer needs significantly better than the baseline. However, a more fine-grained usage-specific ranking did not further improve the ranking.
Starting Conversations with Search Engines -- Interfaces that Elicit Natural Language Queries
Feb 13, 2023


Search systems on the Web rely on user input to generate relevant results. Since early information retrieval systems, users are trained to issue keyword searches and adapt to the language of the system. Recent research has shown that users often withhold detailed information about their initial information need, although they are able to express it in natural language. We therefore conduct a user study (N = 139) to investigate how four different design variants of search interfaces can encourage the user to reveal more information. Our results show that a chatbot-inspired search interface can increase the number of mentioned product attributes by 84% and promote natural language formulations by 139% in comparison to a standard search bar interface.
Online Information Retrieval Evaluation using the STELLA Framework
Oct 24, 2022
Involving users in early phases of software development has become a common strategy as it enables developers to consider user needs from the beginning. Once a system is in production, new opportunities to observe, evaluate and learn from users emerge as more information becomes available. Gathering information from users to continuously evaluate their behavior is a common practice for commercial software, while the Cranfield paradigm remains the preferred option for Information Retrieval (IR) and recommendation systems in the academic world. Here we introduce the Infrastructures for Living Labs STELLA project which aims to create an evaluation infrastructure allowing experimental systems to run along production web-based academic search systems with real users. STELLA combines user interactions and log files analyses to enable large-scale A/B experiments for academic search.
* arXiv admin note: text overlap with arXiv:2203.05430
SaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022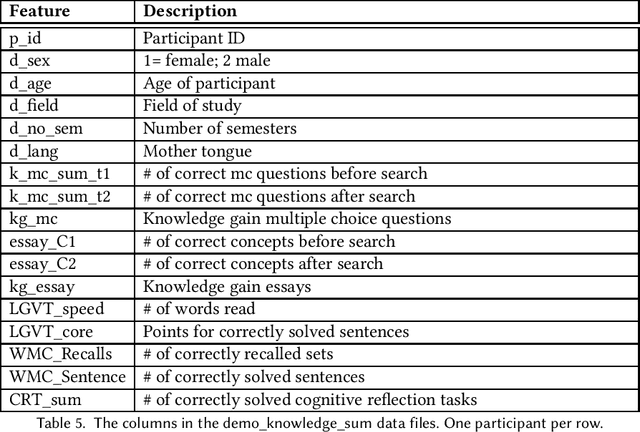
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.
Exploring semantically-related concepts from Wikipedia: the case of SeRE
Apr 27, 2015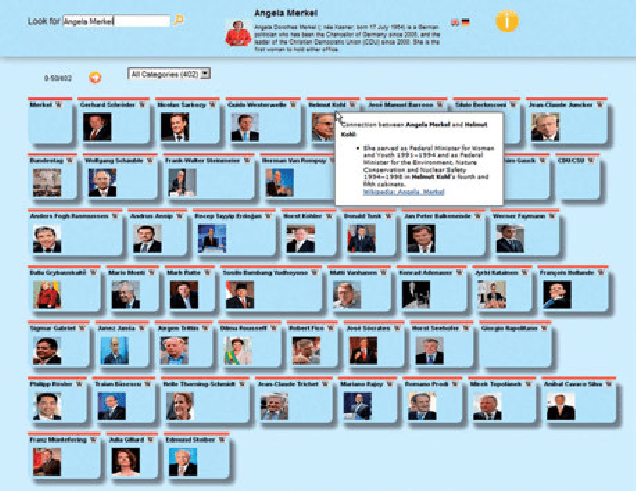
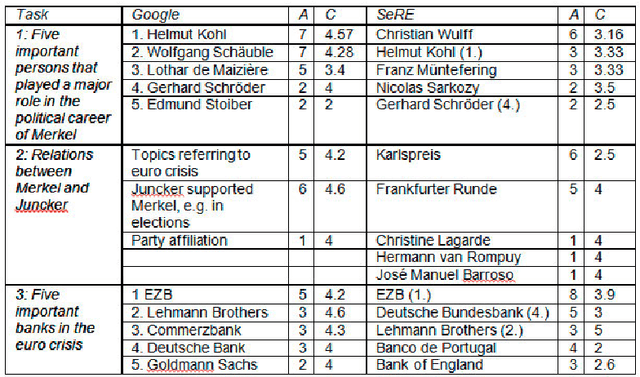
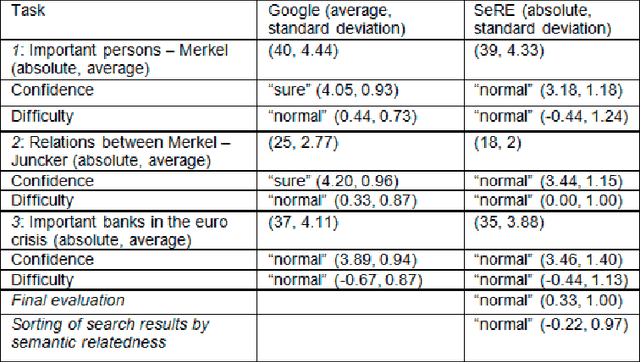
In this paper we present our web application SeRE designed to explore semantically related concepts. Wikipedia and DBpedia are rich data sources to extract related entities for a given topic, like in- and out-links, broader and narrower terms, categorisation information etc. We use the Wikipedia full text body to compute the semantic relatedness for extracted terms, which results in a list of entities that are most relevant for a topic. For any given query, the user interface of SeRE visualizes these related concepts, ordered by semantic relatedness; with snippets from Wikipedia articles that explain the connection between those two entities. In a user study we examine how SeRE can be used to find important entities and their relationships for a given topic and to answer the question of how the classification system can be used for filtering.