 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarting Conversations with Search Engines -- Interfaces that Elicit Natural Language Queries
Feb 13, 2023


Search systems on the Web rely on user input to generate relevant results. Since early information retrieval systems, users are trained to issue keyword searches and adapt to the language of the system. Recent research has shown that users often withhold detailed information about their initial information need, although they are able to express it in natural language. We therefore conduct a user study (N = 139) to investigate how four different design variants of search interfaces can encourage the user to reveal more information. Our results show that a chatbot-inspired search interface can increase the number of mentioned product attributes by 84% and promote natural language formulations by 139% in comparison to a standard search bar interface.
Dataset of Natural Language Queries for E-Commerce
Feb 13, 2023Shopping online is more and more frequent in our everyday life. For e-commerce search systems, understanding natural language coming through voice assistants, chatbots or from conversational search is an essential ability to understand what the user really wants. However, evaluation datasets with natural and detailed information needs of product-seekers which could be used for research do not exist. Due to privacy issues and competitive consequences, only few datasets with real user search queries from logs are openly available. In this paper, we present a dataset of 3,540 natural language queries in two domains that describe what users want when searching for a laptop or a jacket of their choice. The dataset contains annotations of vague terms and key facts of 1,754 laptop queries. This dataset opens up a range of research opportunities in the fields of natural language processing and (interactive) information retrieval for product search.
UNDR: User-Needs-Driven Ranking of Products in E-Commerce
Feb 13, 2023Online retailers often offer a vast choice of products to their customers to filter and browse through. The order in which the products are listed depends on the ranking algorithm employed in the online shop. State-of-the-art ranking methods are complex and draw on many different information, e.g., user query and intent, product attributes, popularity, recency, reviews, or purchases. However, approaches that incorporate user-generated data such as click-through data, user ratings, or reviews disadvantage new products that have not yet been rated by customers. We therefore propose the User-Needs-Driven Ranking (UNDR) method that accounts for explicit customer needs by using facet popularity and facet value popularity. As a user-centered approach that does not rely on post-purchase ratings or reviews, our method bypasses the cold-start problem while still reflecting the needs of an average customer. In two preliminary user studies, we compare our ranking method with a rating-based ranking baseline. Our findings show that our proposed approach generates a ranking that fits current customer needs significantly better than the baseline. However, a more fine-grained usage-specific ranking did not further improve the ranking.
How model accuracy and explanation fidelity influence user trust
Jul 26, 2019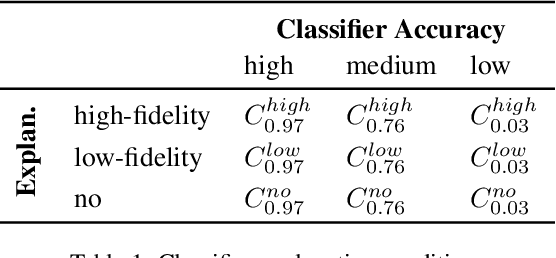
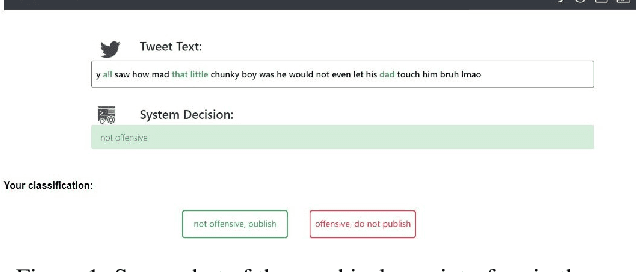
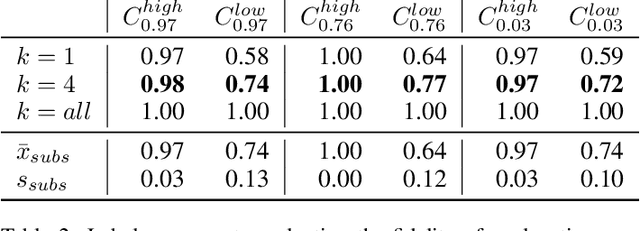
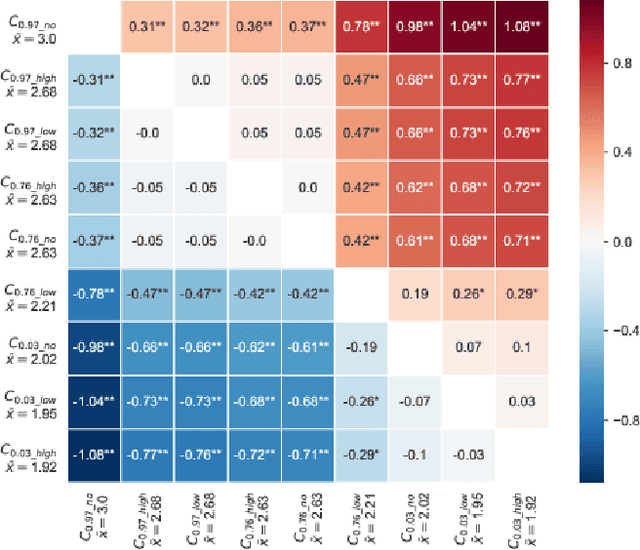
Machine learning systems have become popular in fields such as marketing, financing, or data mining. While they are highly accurate, complex machine learning systems pose challenges for engineers and users. Their inherent complexity makes it impossible to easily judge their fairness and the correctness of statistically learned relations between variables and classes. Explainable AI aims to solve this challenge by modelling explanations alongside with the classifiers, potentially improving user trust and acceptance. However, users should not be fooled by persuasive, yet untruthful explanations. We therefore conduct a user study in which we investigate the effects of model accuracy and explanation fidelity, i.e. how truthfully the explanation represents the underlying model, on user trust. Our findings show that accuracy is more important for user trust than explainability. Adding an explanation for a classification result can potentially harm trust, e.g. when adding nonsensical explanations. We also found that users cannot be tricked by high-fidelity explanations into having trust for a bad classifier. Furthermore, we found a mismatch between observed (implicit) and self-reported (explicit) trust.