 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusing More Objects for Semi-Supervised Domain Adaptation with Less Labeling
Dec 19, 2023For object detection, it is possible to view the prediction of bounding boxes as a reverse diffusion process. Using a diffusion model, the random bounding boxes are iteratively refined in a denoising step, conditioned on the image. We propose a stochastic accumulator function that starts each run with random bounding boxes and combines the slightly different predictions. We empirically verify that this improves detection performance. The improved detections are leveraged on unlabelled images as weighted pseudo-labels for semi-supervised learning. We evaluate the method on a challenging out-of-domain test set. Our method brings significant improvements and is on par with human-selected pseudo-labels, while not requiring any human involvement.
Feature Attribution Explanations for Spiking Neural Networks
Nov 02, 2023Third-generation artificial neural networks, Spiking Neural Networks (SNNs), can be efficiently implemented on hardware. Their implementation on neuromorphic chips opens a broad range of applications, such as machine learning-based autonomous control and intelligent biomedical devices. In critical applications, however, insight into the reasoning of SNNs is important, thus SNNs need to be equipped with the ability to explain how decisions are reached. We present \textit{Temporal Spike Attribution} (TSA), a local explanation method for SNNs. To compute the explanation, we aggregate all information available in model-internal variables: spike times and model weights. We evaluate TSA on artificial and real-world time series data and measure explanation quality w.r.t. multiple quantitative criteria. We find that TSA correctly identifies a small subset of input features relevant to the decision (i.e., is output-complete and compact) and generates similar explanations for similar inputs (i.e., is continuous). Further, our experiments show that incorporating the notion of \emph{absent} spikes improves explanation quality. Our work can serve as a starting point for explainable SNNs, with future implementations on hardware yielding not only predictions but also explanations in a broad range of application scenarios. Source code is available at https://github.com/ElisaNguyen/tsa-explanations.
How model accuracy and explanation fidelity influence user trust
Jul 26, 2019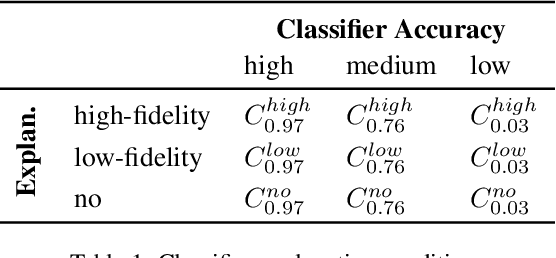
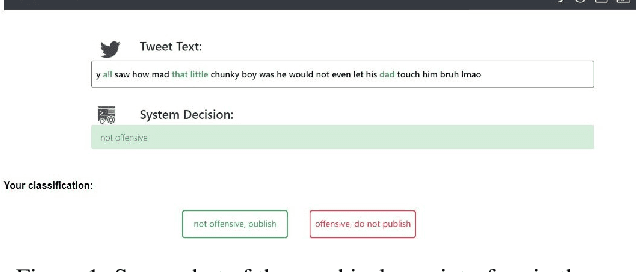
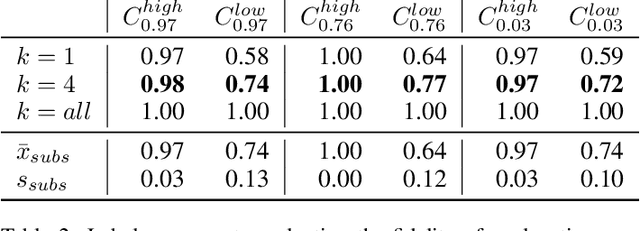
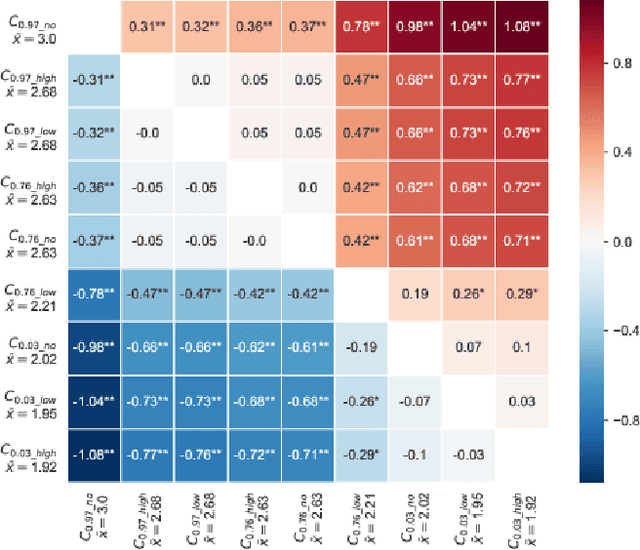
Machine learning systems have become popular in fields such as marketing, financing, or data mining. While they are highly accurate, complex machine learning systems pose challenges for engineers and users. Their inherent complexity makes it impossible to easily judge their fairness and the correctness of statistically learned relations between variables and classes. Explainable AI aims to solve this challenge by modelling explanations alongside with the classifiers, potentially improving user trust and acceptance. However, users should not be fooled by persuasive, yet untruthful explanations. We therefore conduct a user study in which we investigate the effects of model accuracy and explanation fidelity, i.e. how truthfully the explanation represents the underlying model, on user trust. Our findings show that accuracy is more important for user trust than explainability. Adding an explanation for a classification result can potentially harm trust, e.g. when adding nonsensical explanations. We also found that users cannot be tricked by high-fidelity explanations into having trust for a bad classifier. Furthermore, we found a mismatch between observed (implicit) and self-reported (explicit) trust.
Learning spectro-temporal features with 3D CNNs for speech emotion recognition
Aug 14, 2017



In this paper, we propose to use deep 3-dimensional convolutional networks (3D CNNs) in order to address the challenge of modelling spectro-temporal dynamics for speech emotion recognition (SER). Compared to a hybrid of Convolutional Neural Network and Long-Short-Term-Memory (CNN-LSTM), our proposed 3D CNNs simultaneously extract short-term and long-term spectral features with a moderate number of parameters. We evaluated our proposed and other state-of-the-art methods in a speaker-independent manner using aggregated corpora that give a large and diverse set of speakers. We found that 1) shallow temporal and moderately deep spectral kernels of a homogeneous architecture are optimal for the task; and 2) our 3D CNNs are more effective for spectro-temporal feature learning compared to other methods. Finally, we visualised the feature space obtained with our proposed method using t-distributed stochastic neighbour embedding (T-SNE) and could observe distinct clusters of emotions.
Towards Speech Emotion Recognition "in the wild" using Aggregated Corpora and Deep Multi-Task Learning
Aug 13, 2017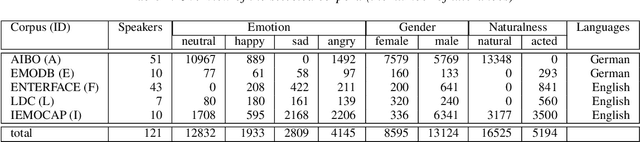
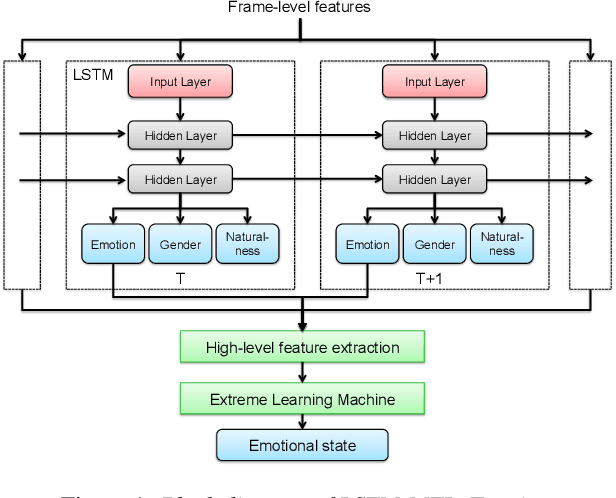
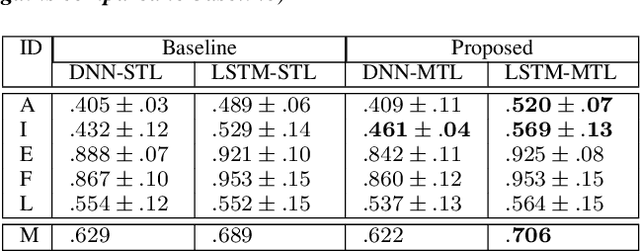
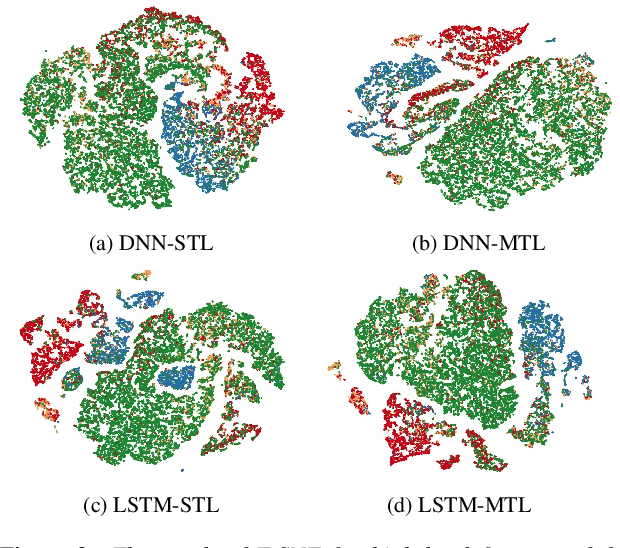
One of the challenges in Speech Emotion Recognition (SER) "in the wild" is the large mismatch between training and test data (e.g. speakers and tasks). In order to improve the generalisation capabilities of the emotion models, we propose to use Multi-Task Learning (MTL) and use gender and naturalness as auxiliary tasks in deep neural networks. This method was evaluated in within-corpus and various cross-corpus classification experiments that simulate conditions "in the wild". In comparison to Single-Task Learning (STL) based state of the art methods, we found that our MTL method proposed improved performance significantly. Particularly, models using both gender and naturalness achieved more gains than those using either gender or naturalness separately. This benefit was also found in the high-level representations of the feature space, obtained from our method proposed, where discriminative emotional clusters could be observed.
Latent Hierarchical Model for Activity Recognition
Mar 06, 2015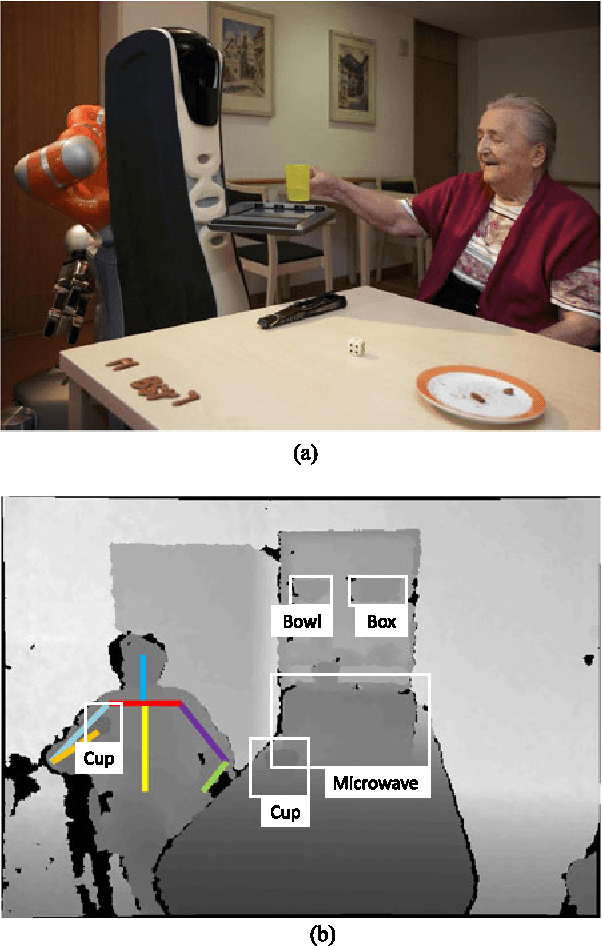
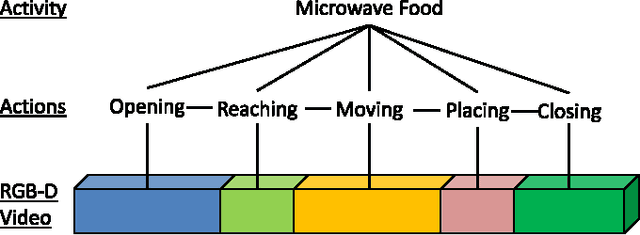
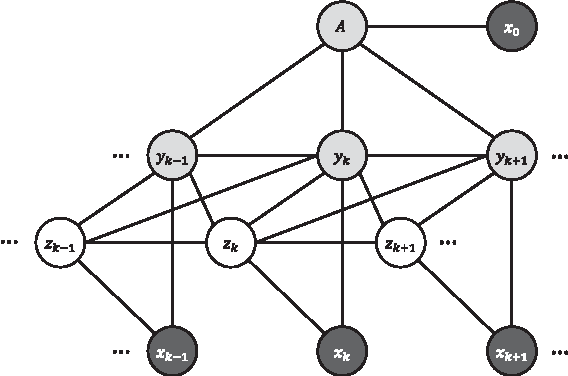

We present a novel hierarchical model for human activity recognition. In contrast to approaches that successively recognize actions and activities, our approach jointly models actions and activities in a unified framework, and their labels are simultaneously predicted. The model is embedded with a latent layer that is able to capture a richer class of contextual information in both state-state and observation-state pairs. Although loops are present in the model, the model has an overall linear-chain structure, where the exact inference is tractable. Therefore, the model is very efficient in both inference and learning. The parameters of the graphical model are learned with a Structured Support Vector Machine (Structured-SVM). A data-driven approach is used to initialize the latent variables; therefore, no manual labeling for the latent states is required. The experimental results from using two benchmark datasets show that our model outperforms the state-of-the-art approach, and our model is computationally more efficient.