 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Speech Representations for the MOS Prediction System
Jun 28, 2022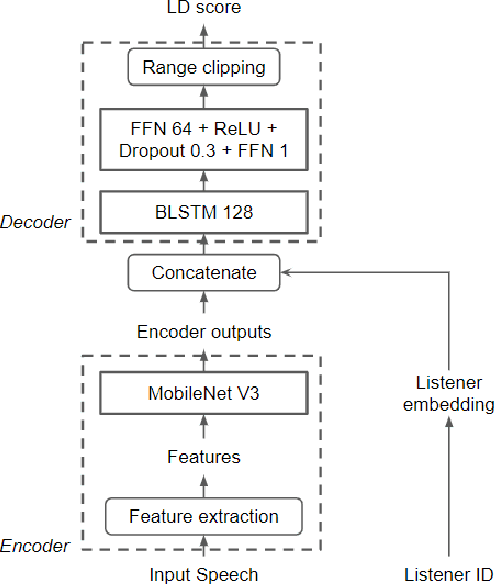
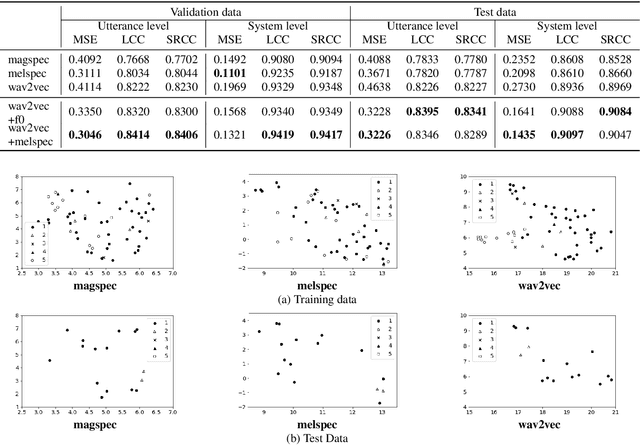
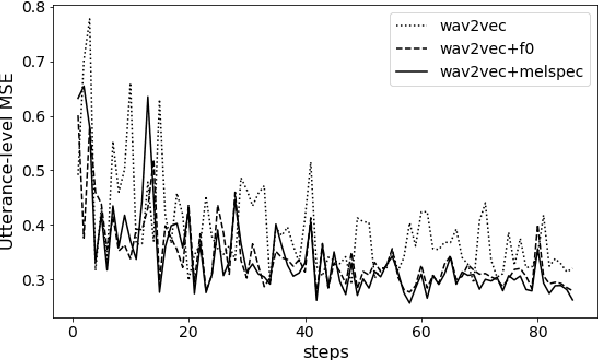
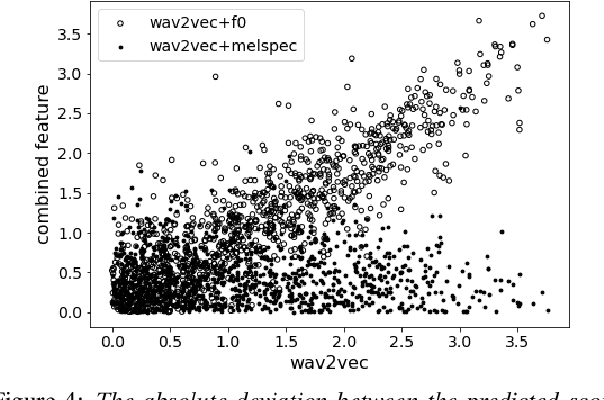
Automatic methods to predict Mean Opinion Score (MOS) of listeners have been researched to assure the quality of Text-to-Speech systems. Many previous studies focus on architectural advances (e.g. MBNet, LDNet, etc.) to capture relations between spectral features and MOS in a more effective way and achieved high accuracy. However, the optimal representation in terms of generalization capability still largely remains unknown. To this end, we compare the performance of Self-Supervised Learning (SSL) features obtained by the wav2vec framework to that of spectral features such as magnitude of spectrogram and melspectrogram. Moreover, we propose to combine the SSL features and features which we believe to retain essential information to the automatic MOS to compensate each other for their drawbacks. We conduct comprehensive experiments on a large-scale listening test corpus collected from past Blizzard and Voice Conversion Challenges. We found that the wav2vec feature set showed the best generalization even though the given ground-truth was not always reliable. Furthermore, we found that the combinations performed the best and analyzed how they bridged the gap between spectral and the wav2vec feature sets.
Data-augmented cross-lingual synthesis in a teacher-student framework
Mar 31, 2022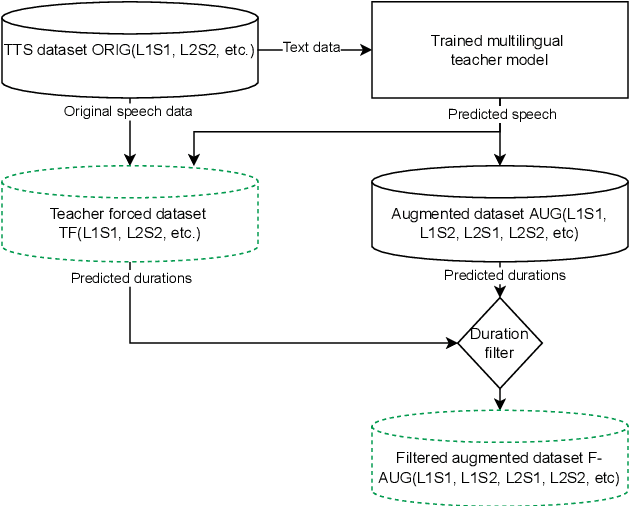
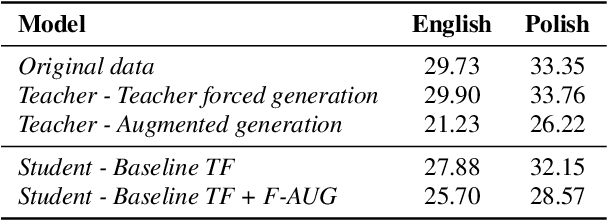
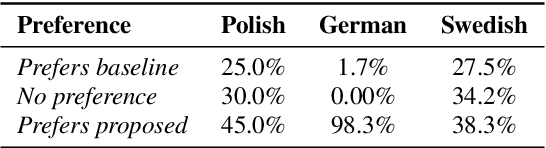
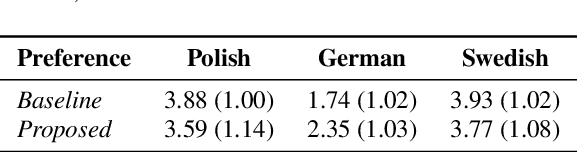
Cross-lingual synthesis can be defined as the task of letting a speaker generate fluent synthetic speech in another language. This is a challenging task, and resulting speech can suffer from reduced naturalness, accented speech, and/or loss of essential voice characteristics. Previous research shows that many models appear to have insufficient generalization capabilities to perform well on every of these cross-lingual aspects. To overcome these generalization problems, we propose to apply the teacher-student paradigm to cross-lingual synthesis. While a teacher model is commonly used to produce teacher forced data, we propose to also use it to produce augmented data of unseen speaker-language pairs, where the aim is to retain essential speaker characteristics. Both sets of data are then used for student model training, which is trained to retain the naturalness and prosodic variation present in the teacher forced data, while learning the speaker identity from the augmented data. Some modifications to the student model are proposed to make the separation of teacher forced and augmented data more straightforward. Results show that the proposed approach improves the retention of speaker characteristics in the speech, while managing to retain high levels of naturalness and prosodic variation.
Efficient neural speech synthesis for low-resource languages through multilingual modeling
Aug 20, 2020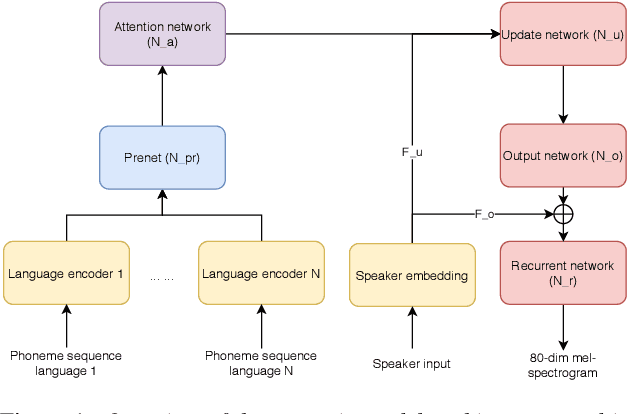
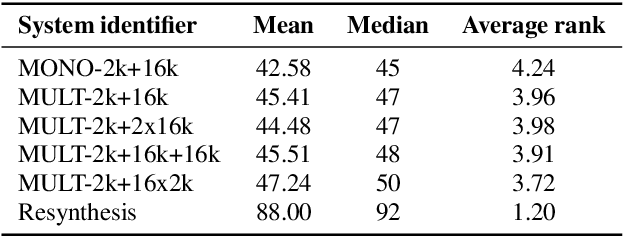

Recent advances in neural TTS have led to models that can produce high-quality synthetic speech. However, these models typically require large amounts of training data, which can make it costly to produce a new voice with the desired quality. Although multi-speaker modeling can reduce the data requirements necessary for a new voice, this approach is usually not viable for many low-resource languages for which abundant multi-speaker data is not available. In this paper, we therefore investigated to what extent multilingual multi-speaker modeling can be an alternative to monolingual multi-speaker modeling, and explored how data from foreign languages may best be combined with low-resource language data. We found that multilingual modeling can increase the naturalness of low-resource language speech, showed that multilingual models can produce speech with a naturalness comparable to monolingual multi-speaker models, and saw that the target language naturalness was affected by the strategy used to add foreign language data.
Planning Based System for Child-Robot Interaction in Dynamic Play Environments
Aug 21, 2017
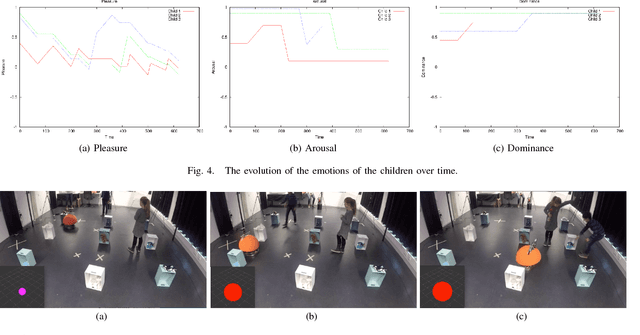
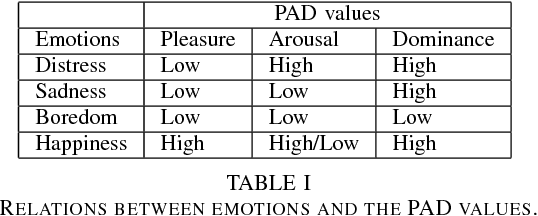
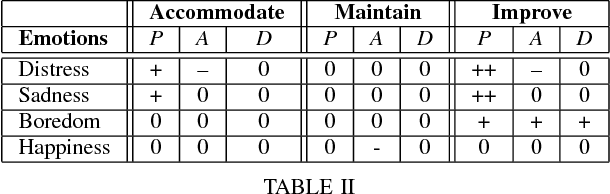
This paper describes the initial steps towards the design of a robotic system that intends to perform actions autonomously in a naturalistic play environment. At the same time it aims for social human-robot interaction~(HRI), focusing on children. We draw on existing theories of child development and on dimensional models of emotions to explore the design of a dynamic interaction framework for natural child-robot interaction. In this dynamic setting, the social HRI is defined by the ability of the system to take into consideration the socio-emotional state of the user and to plan appropriately by selecting appropriate strategies for execution. The robot needs a temporal planning system, which combines features of task-oriented actions and principles of social human robot interaction. We present initial results of an empirical study for the evaluation of the proposed framework in the context of a collaborative sorting game.
Learning spectro-temporal features with 3D CNNs for speech emotion recognition
Aug 14, 2017



In this paper, we propose to use deep 3-dimensional convolutional networks (3D CNNs) in order to address the challenge of modelling spectro-temporal dynamics for speech emotion recognition (SER). Compared to a hybrid of Convolutional Neural Network and Long-Short-Term-Memory (CNN-LSTM), our proposed 3D CNNs simultaneously extract short-term and long-term spectral features with a moderate number of parameters. We evaluated our proposed and other state-of-the-art methods in a speaker-independent manner using aggregated corpora that give a large and diverse set of speakers. We found that 1) shallow temporal and moderately deep spectral kernels of a homogeneous architecture are optimal for the task; and 2) our 3D CNNs are more effective for spectro-temporal feature learning compared to other methods. Finally, we visualised the feature space obtained with our proposed method using t-distributed stochastic neighbour embedding (T-SNE) and could observe distinct clusters of emotions.
Towards Speech Emotion Recognition "in the wild" using Aggregated Corpora and Deep Multi-Task Learning
Aug 13, 2017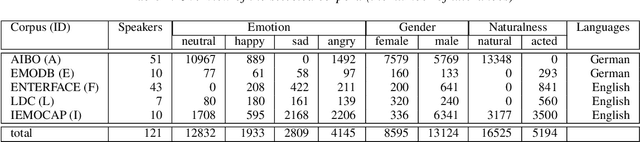
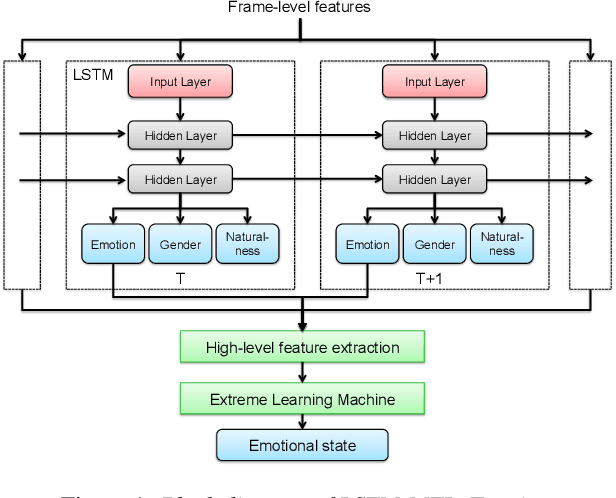
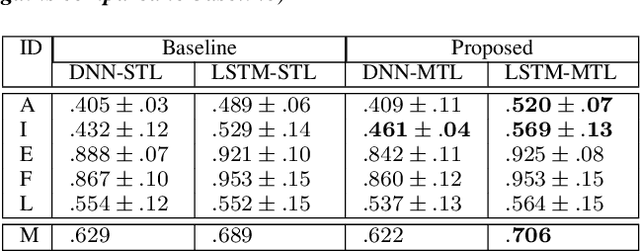
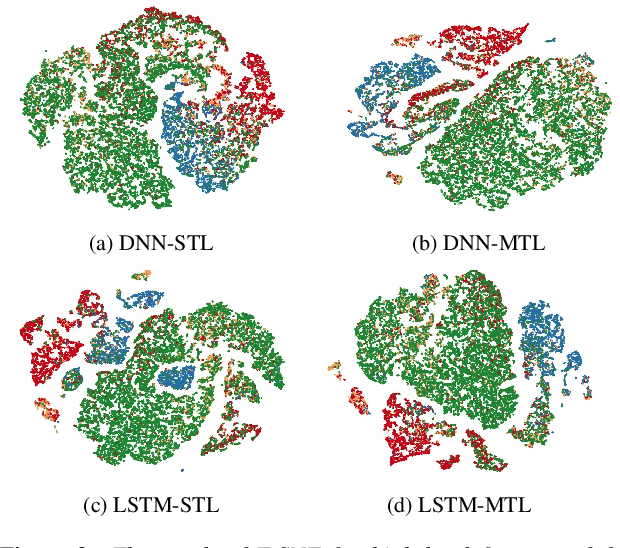
One of the challenges in Speech Emotion Recognition (SER) "in the wild" is the large mismatch between training and test data (e.g. speakers and tasks). In order to improve the generalisation capabilities of the emotion models, we propose to use Multi-Task Learning (MTL) and use gender and naturalness as auxiliary tasks in deep neural networks. This method was evaluated in within-corpus and various cross-corpus classification experiments that simulate conditions "in the wild". In comparison to Single-Task Learning (STL) based state of the art methods, we found that our MTL method proposed improved performance significantly. Particularly, models using both gender and naturalness achieved more gains than those using either gender or naturalness separately. This benefit was also found in the high-level representations of the feature space, obtained from our method proposed, where discriminative emotional clusters could be observed.