 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-augmented cross-lingual synthesis in a teacher-student framework
Paper and Code
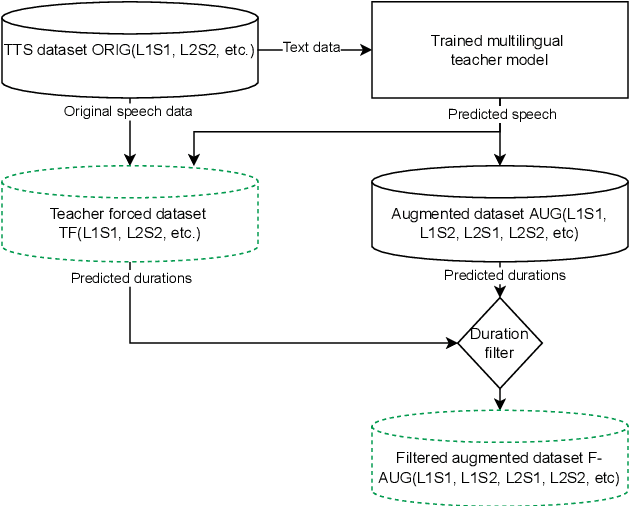
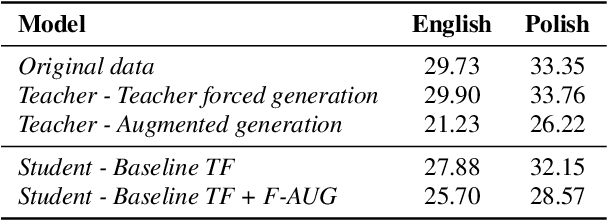
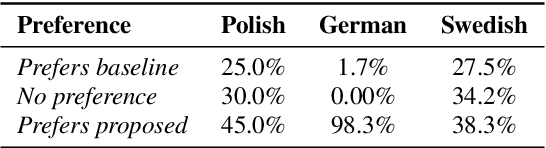
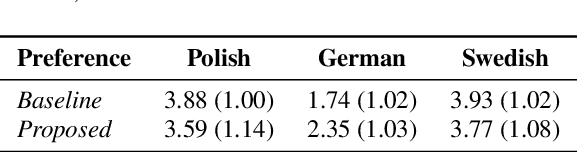
Cross-lingual synthesis can be defined as the task of letting a speaker generate fluent synthetic speech in another language. This is a challenging task, and resulting speech can suffer from reduced naturalness, accented speech, and/or loss of essential voice characteristics. Previous research shows that many models appear to have insufficient generalization capabilities to perform well on every of these cross-lingual aspects. To overcome these generalization problems, we propose to apply the teacher-student paradigm to cross-lingual synthesis. While a teacher model is commonly used to produce teacher forced data, we propose to also use it to produce augmented data of unseen speaker-language pairs, where the aim is to retain essential speaker characteristics. Both sets of data are then used for student model training, which is trained to retain the naturalness and prosodic variation present in the teacher forced data, while learning the speaker identity from the augmented data. Some modifications to the student model are proposed to make the separation of teacher forced and augmented data more straightforward. Results show that the proposed approach improves the retention of speaker characteristics in the speech, while managing to retain high levels of naturalness and prosodic variation.