 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated speech audiometry: Can it work using open-source pre-trained Kaldi-NL automatic speech recognition?
Dec 19, 2023



A practical speech audiometry tool is the digits-in-noise (DIN) test for hearing screening of populations of varying ages and hearing status. The test is usually conducted by a human supervisor (e.g., clinician), who scores the responses spoken by the listener, or online, where a software scores the responses entered by the listener. The test has 24 digit-triplets presented in an adaptive staircase procedure, resulting in a speech reception threshold (SRT). We propose an alternative automated DIN test setup that can evaluate spoken responses whilst conducted without a human supervisor, using the open-source automatic speech recognition toolkit, Kaldi-NL. Thirty self-reported normal-hearing Dutch adults (19-64 years) completed one DIN+Kaldi-NL test. Their spoken responses were recorded, and used for evaluating the transcript of decoded responses by Kaldi-NL. Study 1 evaluated the Kaldi-NL performance through its word error rate (WER), percentage of summed decoding errors regarding only digits found in the transcript compared to the total number of digits present in the spoken responses. Average WER across participants was 5.0% (range 0 - 48%, SD = 8.8%), with average decoding errors in three triplets per participant. Study 2 analysed the effect that triplets with decoding errors from Kaldi-NL had on the DIN test output (SRT), using bootstrapping simulations. Previous research indicated 0.70 dB as the typical within-subject SRT variability for normal-hearing adults. Study 2 showed that up to four triplets with decoding errors produce SRT variations within this range, suggesting that our proposed setup could be feasible for clinical applications.
Designing Conversational Robots with Children during the Pandemic
May 23, 2022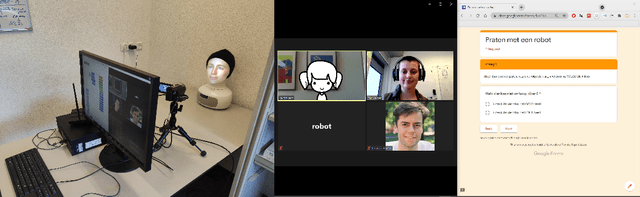
Our research project (CHATTERS) is about designing a conversational robot for children's digital information search. We want to design a robot with a suitable conversation, that fosters a responsible trust relationship between child and robot. In this paper we give: 1) a preliminary view on an empirical study around children's trust in robots that provide information, which was conducted via video call due to the COVID-19 pandemic. 2) We also give a preliminary analysis of a co-design workshop we conducted, where the pandemic may have impacted children's design choices. (3) We close by describing the upcoming research activities we are developing.
Learning spectro-temporal features with 3D CNNs for speech emotion recognition
Aug 14, 2017



In this paper, we propose to use deep 3-dimensional convolutional networks (3D CNNs) in order to address the challenge of modelling spectro-temporal dynamics for speech emotion recognition (SER). Compared to a hybrid of Convolutional Neural Network and Long-Short-Term-Memory (CNN-LSTM), our proposed 3D CNNs simultaneously extract short-term and long-term spectral features with a moderate number of parameters. We evaluated our proposed and other state-of-the-art methods in a speaker-independent manner using aggregated corpora that give a large and diverse set of speakers. We found that 1) shallow temporal and moderately deep spectral kernels of a homogeneous architecture are optimal for the task; and 2) our 3D CNNs are more effective for spectro-temporal feature learning compared to other methods. Finally, we visualised the feature space obtained with our proposed method using t-distributed stochastic neighbour embedding (T-SNE) and could observe distinct clusters of emotions.
Towards Speech Emotion Recognition "in the wild" using Aggregated Corpora and Deep Multi-Task Learning
Aug 13, 2017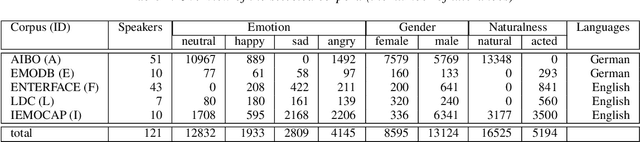
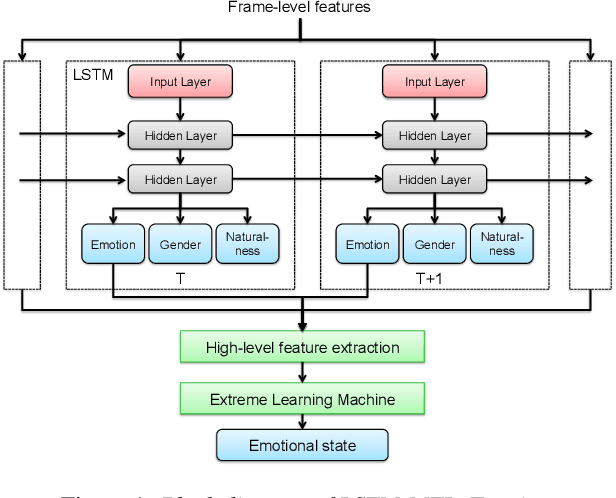
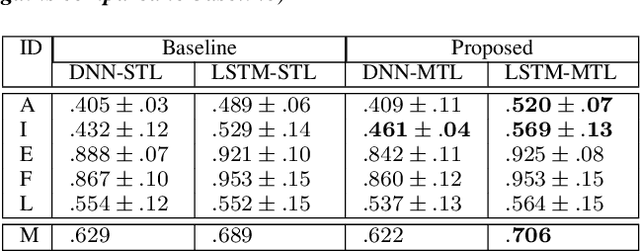
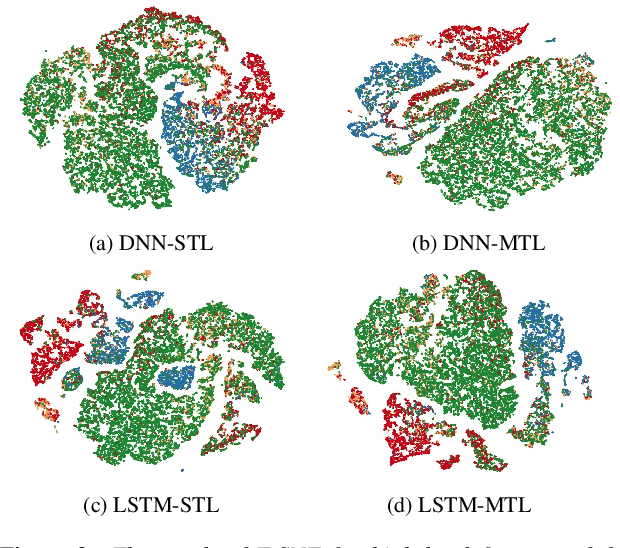
One of the challenges in Speech Emotion Recognition (SER) "in the wild" is the large mismatch between training and test data (e.g. speakers and tasks). In order to improve the generalisation capabilities of the emotion models, we propose to use Multi-Task Learning (MTL) and use gender and naturalness as auxiliary tasks in deep neural networks. This method was evaluated in within-corpus and various cross-corpus classification experiments that simulate conditions "in the wild". In comparison to Single-Task Learning (STL) based state of the art methods, we found that our MTL method proposed improved performance significantly. Particularly, models using both gender and naturalness achieved more gains than those using either gender or naturalness separately. This benefit was also found in the high-level representations of the feature space, obtained from our method proposed, where discriminative emotional clusters could be observed.