 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Speech Representations for the MOS Prediction System
Jun 28, 2022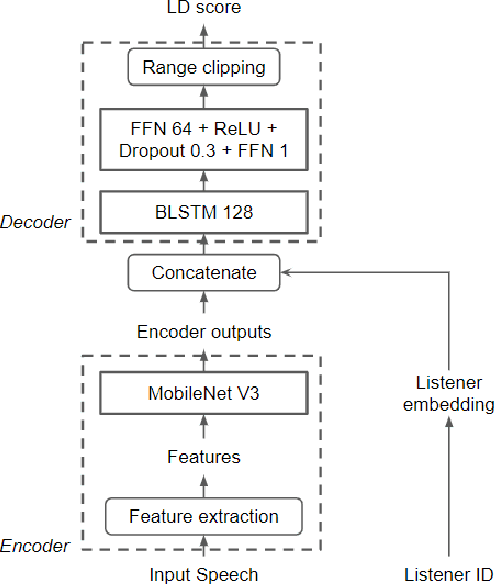
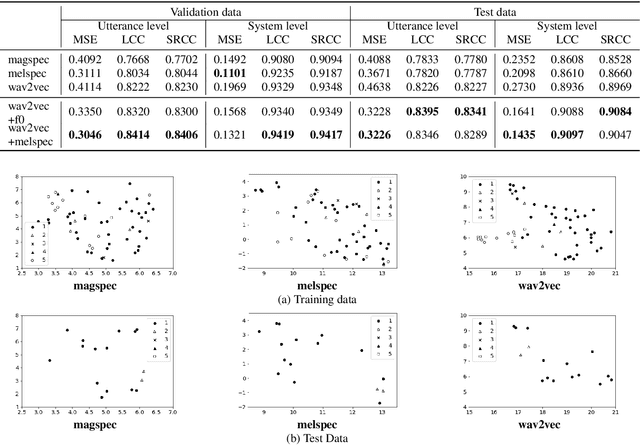
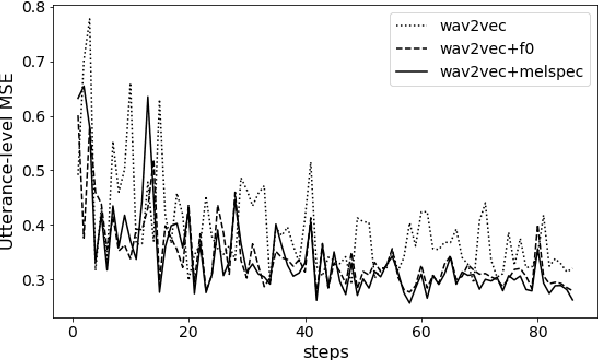
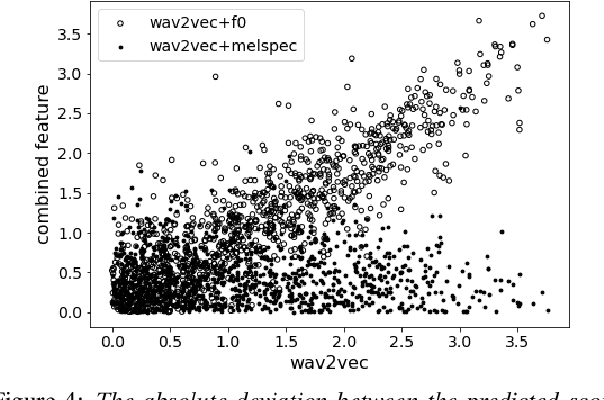
Automatic methods to predict Mean Opinion Score (MOS) of listeners have been researched to assure the quality of Text-to-Speech systems. Many previous studies focus on architectural advances (e.g. MBNet, LDNet, etc.) to capture relations between spectral features and MOS in a more effective way and achieved high accuracy. However, the optimal representation in terms of generalization capability still largely remains unknown. To this end, we compare the performance of Self-Supervised Learning (SSL) features obtained by the wav2vec framework to that of spectral features such as magnitude of spectrogram and melspectrogram. Moreover, we propose to combine the SSL features and features which we believe to retain essential information to the automatic MOS to compensate each other for their drawbacks. We conduct comprehensive experiments on a large-scale listening test corpus collected from past Blizzard and Voice Conversion Challenges. We found that the wav2vec feature set showed the best generalization even though the given ground-truth was not always reliable. Furthermore, we found that the combinations performed the best and analyzed how they bridged the gap between spectral and the wav2vec feature sets.