 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient neural speech synthesis for low-resource languages through multilingual modeling
Paper and Code
Aug 20, 2020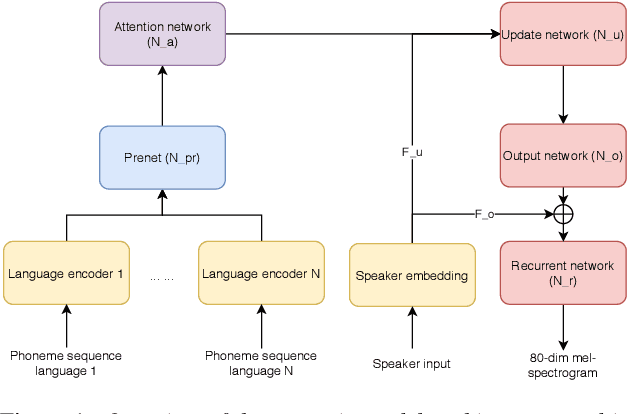
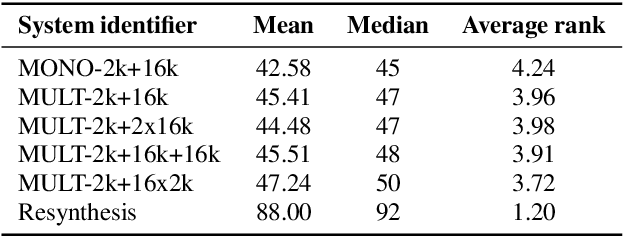

Recent advances in neural TTS have led to models that can produce high-quality synthetic speech. However, these models typically require large amounts of training data, which can make it costly to produce a new voice with the desired quality. Although multi-speaker modeling can reduce the data requirements necessary for a new voice, this approach is usually not viable for many low-resource languages for which abundant multi-speaker data is not available. In this paper, we therefore investigated to what extent multilingual multi-speaker modeling can be an alternative to monolingual multi-speaker modeling, and explored how data from foreign languages may best be combined with low-resource language data. We found that multilingual modeling can increase the naturalness of low-resource language speech, showed that multilingual models can produce speech with a naturalness comparable to monolingual multi-speaker models, and saw that the target language naturalness was affected by the strategy used to add foreign language data.