 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Processing for the OpenGPT-X Model Family
Oct 11, 2024



This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final datasets for model training. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.
Supporting verification of news articles with automated search for semantically similar articles
Mar 29, 2021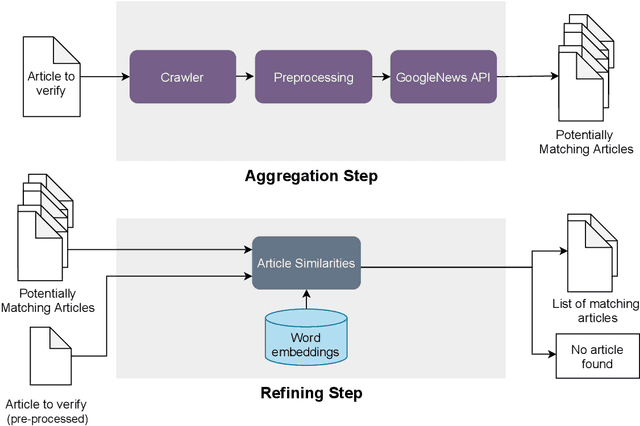

Fake information poses one of the major threats for society in the 21st century. Identifying misinformation has become a key challenge due to the amount of fake news that is published daily. Yet, no approach is established that addresses the dynamics and versatility of fake news editorials. Instead of classifying content, we propose an evidence retrieval approach to handle fake news. The learning task is formulated as an unsupervised machine learning problem. For validation purpose, we provide the user with a set of news articles from reliable news sources supporting the hypothesis of the news article in query and the final decision is left to the user. Technically we propose a two-step process: (i) Aggregation-step: With information extracted from the given text we query for similar content from reliable news sources. (ii) Refining-step: We narrow the supporting evidence down by measuring the semantic distance of the text with the collection from step (i). The distance is calculated based on Word2Vec and the Word Mover's Distance. In our experiments, only content that is below a certain distance threshold is considered as supporting evidence. We find that our approach is agnostic to concept drifts, i.e. the machine learning task is independent of the hypotheses in a text. This makes it highly adaptable in times where fake news is as diverse as classical news is. Our pipeline offers the possibility for further analysis in the future, such as investigating bias and differences in news reporting.
Exploring semantically-related concepts from Wikipedia: the case of SeRE
Apr 27, 2015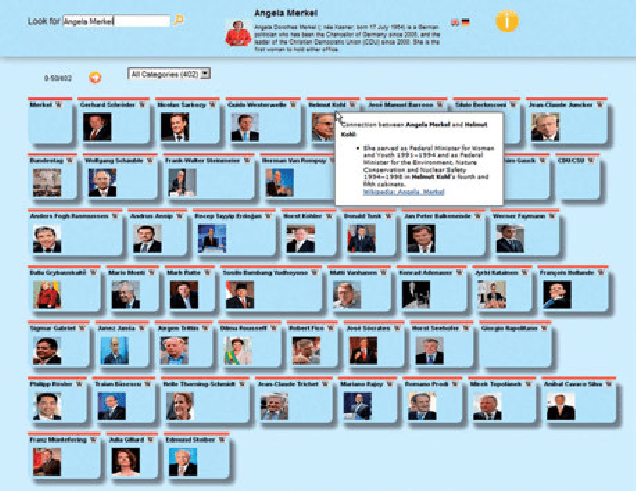
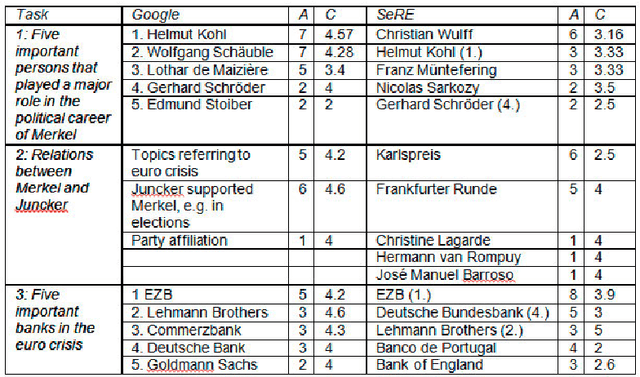
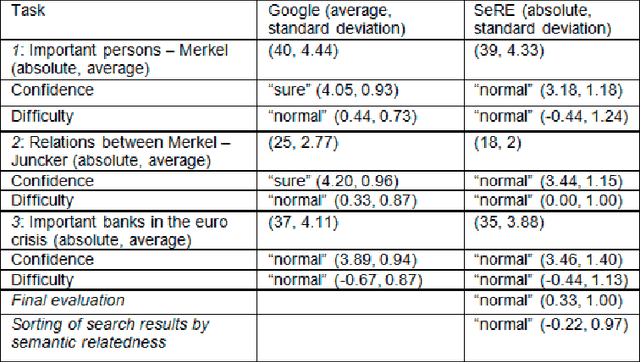
In this paper we present our web application SeRE designed to explore semantically related concepts. Wikipedia and DBpedia are rich data sources to extract related entities for a given topic, like in- and out-links, broader and narrower terms, categorisation information etc. We use the Wikipedia full text body to compute the semantic relatedness for extracted terms, which results in a list of entities that are most relevant for a topic. For any given query, the user interface of SeRE visualizes these related concepts, ordered by semantic relatedness; with snippets from Wikipedia articles that explain the connection between those two entities. In a user study we examine how SeRE can be used to find important entities and their relationships for a given topic and to answer the question of how the classification system can be used for filtering.