 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Processing for the OpenGPT-X Model Family
Oct 11, 2024



This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final datasets for model training. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.
Advancing Topic Segmentation of Broadcasted Speech with Multilingual Semantic Embeddings
Sep 10, 2024

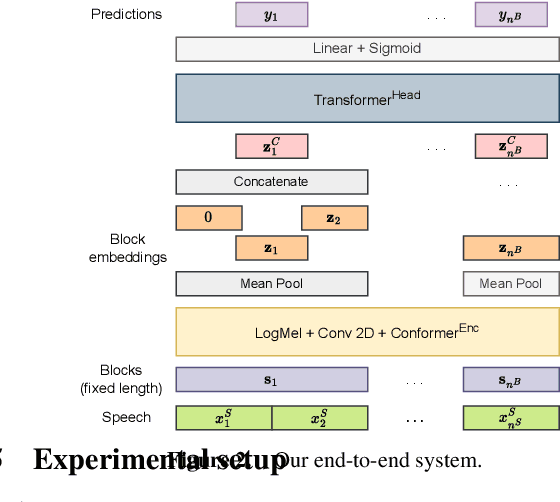

Recent advancements in speech-based topic segmentation have highlighted the potential of pretrained speech encoders to capture semantic representations directly from speech. Traditionally, topic segmentation has relied on a pipeline approach in which transcripts of the automatic speech recognition systems are generated, followed by text-based segmentation algorithms. In this paper, we introduce an end-to-end scheme that bypasses this conventional two-step process by directly employing semantic speech encoders for segmentation. Focused on the broadcasted news domain, which poses unique challenges due to the diversity of speakers and topics within single recordings, we address the challenge of accessing topic change points efficiently in an end-to-end manner. Furthermore, we propose a new benchmark for spoken news topic segmentation by utilizing a dataset featuring approximately 1000 hours of publicly available recordings across six European languages and including an evaluation set in Hindi to test the model's cross-domain performance in a cross-lingual, zero-shot scenario. This setup reflects real-world diversity and the need for models adapting to various linguistic settings. Our results demonstrate that while the traditional pipeline approach achieves a state-of-the-art $P_k$ score of 0.2431 for English, our end-to-end model delivers a competitive $P_k$ score of 0.2564. When trained multilingually, these scores further improve to 0.1988 and 0.2370, respectively. To support further research, we release our model along with data preparation scripts, facilitating open research on multilingual spoken news topic segmentation.
Teaching a Multilingual Large Language Model to Understand Multilingual Speech via Multi-Instructional Training
Apr 16, 2024Recent advancements in language modeling have led to the emergence of Large Language Models (LLMs) capable of various natural language processing tasks. Despite their success in text-based tasks, applying LLMs to the speech domain remains limited and challenging. This paper presents BLOOMZMMS, a novel model that integrates a multilingual LLM with a multilingual speech encoder, aiming to harness the capabilities of LLMs for speech recognition and beyond. Utilizing a multi-instructional training approach, we demonstrate the transferability of linguistic knowledge from the text to the speech modality. Our experiments, conducted on 1900 hours of transcribed data from 139 languages, establish that a multilingual speech representation can be effectively learned and aligned with a multilingual LLM. While this learned representation initially shows limitations in task generalization, we address this issue by generating synthetic targets in a multi-instructional style. Our zero-shot evaluation results confirm the robustness of our approach across multiple tasks, including speech translation and multilingual spoken language understanding, thereby opening new avenues for applying LLMs in the speech domain.
The IMS Toucan System for the Blizzard Challenge 2023
Oct 26, 2023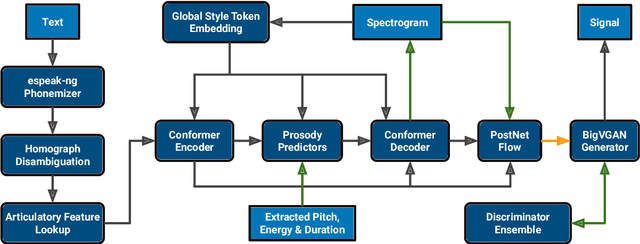
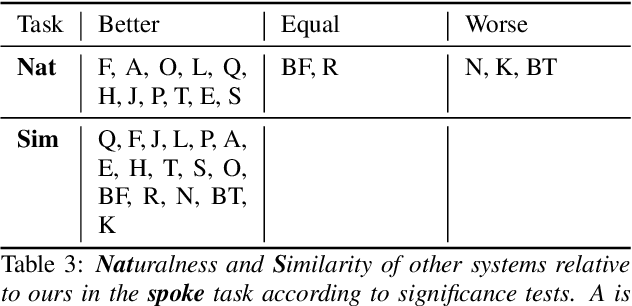
For our contribution to the Blizzard Challenge 2023, we improved on the system we submitted to the Blizzard Challenge 2021. Our approach entails a rule-based text-to-phoneme processing system that includes rule-based disambiguation of homographs in the French language. It then transforms the phonemes to spectrograms as intermediate representations using a fast and efficient non-autoregressive synthesis architecture based on Conformer and Glow. A GAN based neural vocoder that combines recent state-of-the-art approaches converts the spectrogram to the final wave. We carefully designed the data processing, training, and inference procedures for the challenge data. Our system identifier is G. Open source code and demo are available.
Leveraging Multilingual Self-Supervised Pretrained Models for Sequence-to-Sequence End-to-End Spoken Language Understanding
Oct 09, 2023A number of methods have been proposed for End-to-End Spoken Language Understanding (E2E-SLU) using pretrained models, however their evaluation often lacks multilingual setup and tasks that require prediction of lexical fillers, such as slot filling. In this work, we propose a unified method that integrates multilingual pretrained speech and text models and performs E2E-SLU on six datasets in four languages in a generative manner, including the prediction of lexical fillers. We investigate how the proposed method can be improved by pretraining on widely available speech recognition data using several training objectives. Pretraining on 7000 hours of multilingual data allows us to outperform the state-of-the-art ultimately on two SLU datasets and partly on two more SLU datasets. Finally, we examine the cross-lingual capabilities of the proposed model and improve on the best known result on the PortMEDIA-Language dataset by almost half, achieving a Concept/Value Error Rate of 23.65%.
Exploring Speech Recognition, Translation, and Understanding with Discrete Speech Units: A Comparative Study
Sep 27, 2023
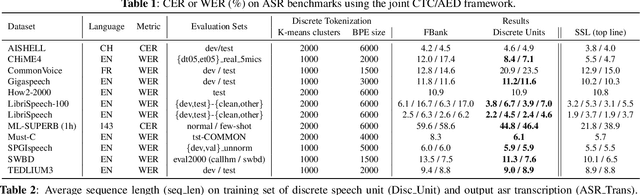
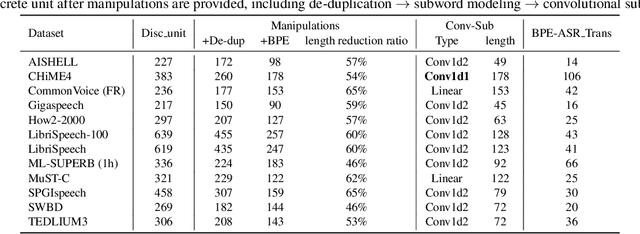
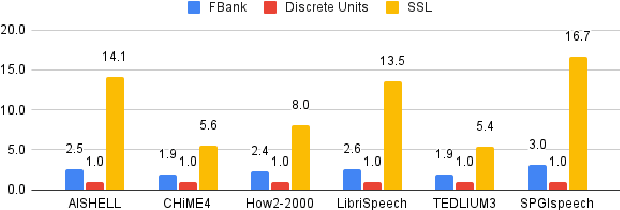
Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
Anonymizing Speech with Generative Adversarial Networks to Preserve Speaker Privacy
Oct 20, 2022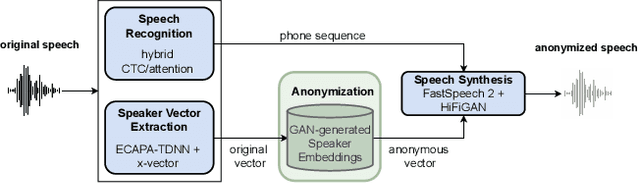
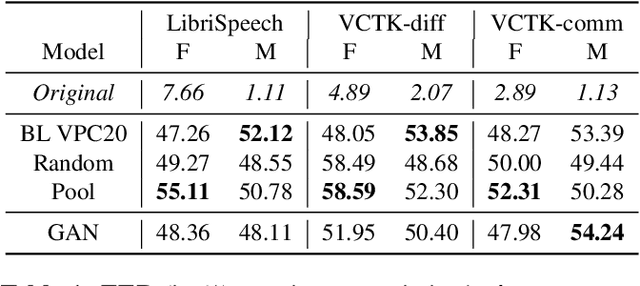
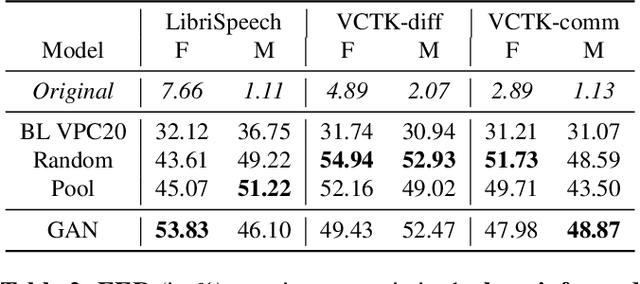
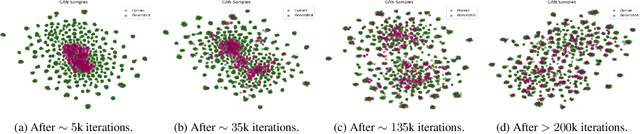
In order to protect the privacy of speech data, speaker anonymization aims for hiding the identity of a speaker by changing the voice in speech recordings. This typically comes with a privacy-utility trade-off between protection of individuals and usability of the data for downstream applications. One of the challenges in this context is to create non-existent voices that sound as natural as possible. In this work, we propose to tackle this issue by generating speaker embeddings using a generative adversarial network with Wasserstein distance as cost function. By incorporating these artificial embeddings into a speech-to-text-to-speech pipeline, we outperform previous approaches in terms of privacy and utility. According to standard objective metrics and human evaluation, our approach generates intelligible and content-preserving yet privacy-protecting versions of the original recordings.
Speaker Anonymization with Phonetic Intermediate Representations
Jul 11, 2022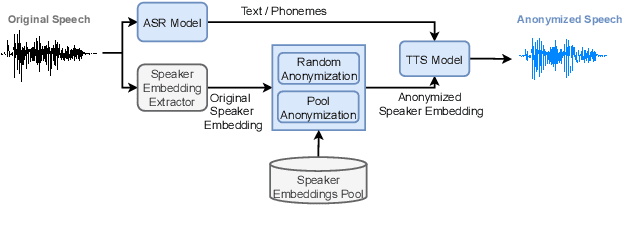
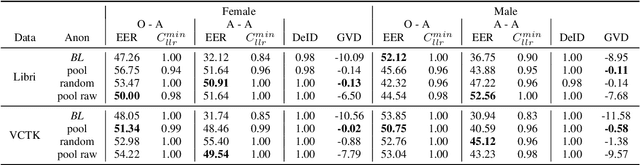
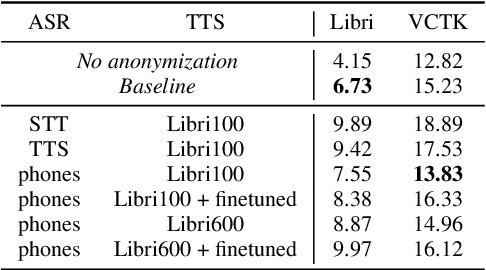

In this work, we propose a speaker anonymization pipeline that leverages high quality automatic speech recognition and synthesis systems to generate speech conditioned on phonetic transcriptions and anonymized speaker embeddings. Using phones as the intermediate representation ensures near complete elimination of speaker identity information from the input while preserving the original phonetic content as much as possible. Our experimental results on LibriSpeech and VCTK corpora reveal two key findings: 1) although automatic speech recognition produces imperfect transcriptions, our neural speech synthesis system can handle such errors, making our system feasible and robust, and 2) combining speaker embeddings from different resources is beneficial and their appropriate normalization is crucial. Overall, our final best system outperforms significantly the baselines provided in the Voice Privacy Challenge 2020 in terms of privacy robustness against a lazy-informed attacker while maintaining high intelligibility and naturalness of the anonymized speech.
ESPnet-SLU: Advancing Spoken Language Understanding through ESPnet
Nov 29, 2021
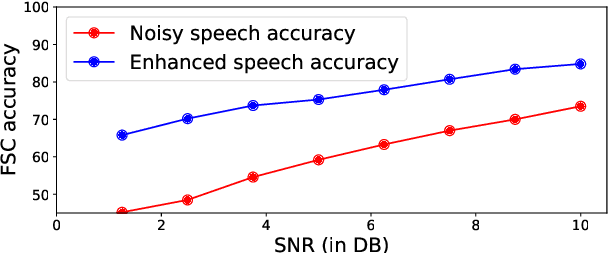
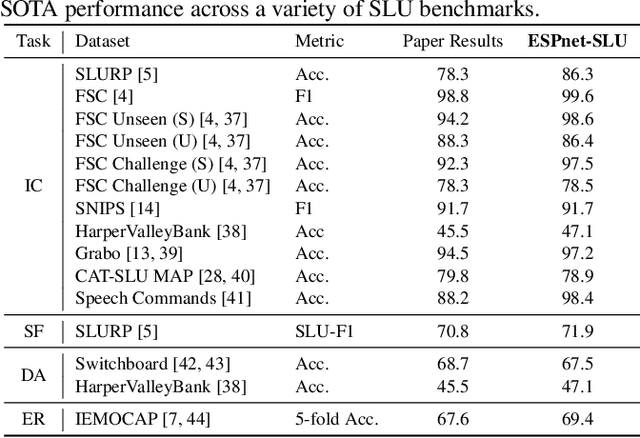

As Automatic Speech Processing (ASR) systems are getting better, there is an increasing interest of using the ASR output to do downstream Natural Language Processing (NLP) tasks. However, there are few open source toolkits that can be used to generate reproducible results on different Spoken Language Understanding (SLU) benchmarks. Hence, there is a need to build an open source standard that can be used to have a faster start into SLU research. We present ESPnet-SLU, which is designed for quick development of spoken language understanding in a single framework. ESPnet-SLU is a project inside end-to-end speech processing toolkit, ESPnet, which is a widely used open-source standard for various speech processing tasks like ASR, Text to Speech (TTS) and Speech Translation (ST). We enhance the toolkit to provide implementations for various SLU benchmarks that enable researchers to seamlessly mix-and-match different ASR and NLU models. We also provide pretrained models with intensively tuned hyper-parameters that can match or even outperform the current state-of-the-art performances. The toolkit is publicly available at https://github.com/espnet/espnet.
Investigations on Speech Recognition Systems for Low-Resource Dialectal Arabic-English Code-Switching Speech
Aug 29, 2021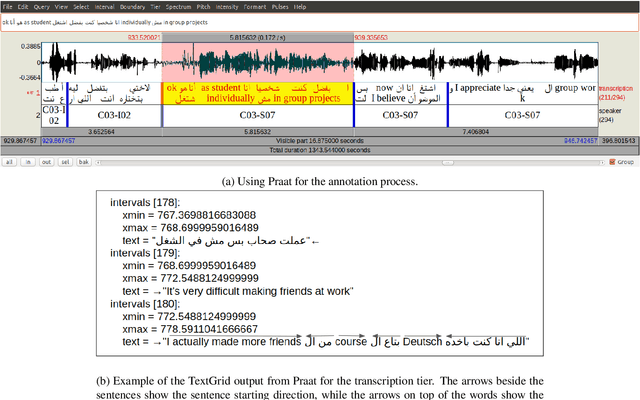
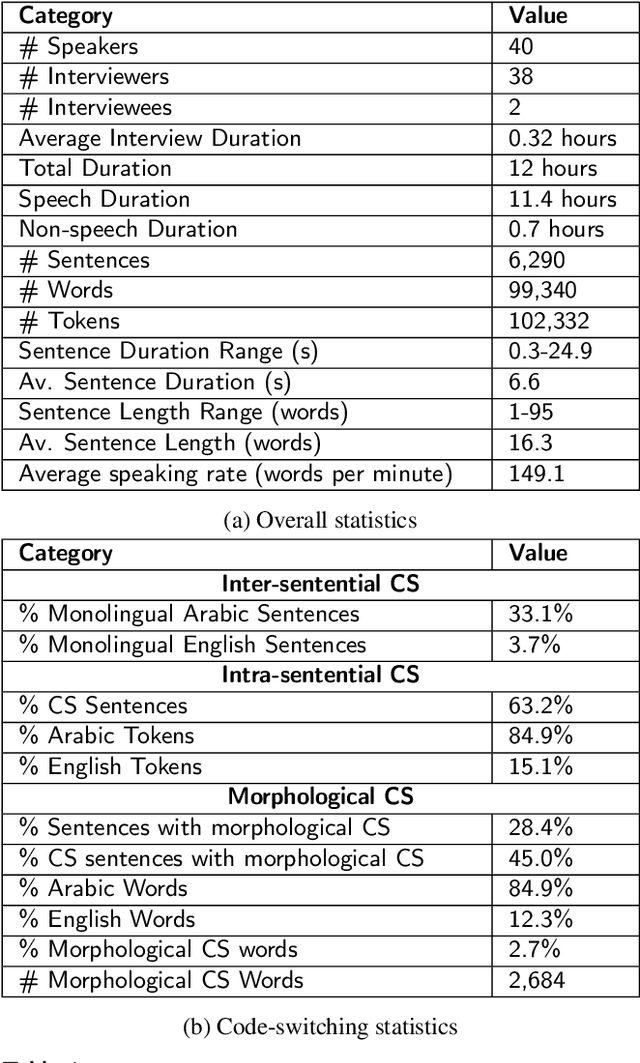
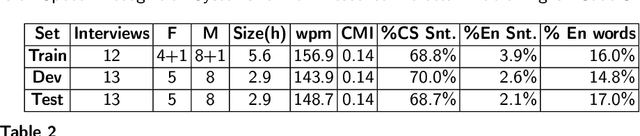
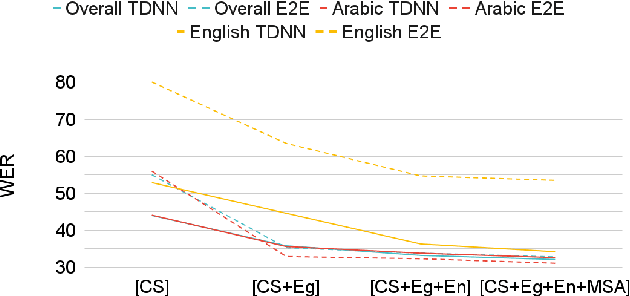
Code-switching (CS), defined as the mixing of languages in conversations, has become a worldwide phenomenon. The prevalence of CS has been recently met with a growing demand and interest to build CS ASR systems. In this paper, we present our work on code-switched Egyptian Arabic-English automatic speech recognition (ASR). We first contribute in filling the huge gap in resources by collecting, analyzing and publishing our spontaneous CS Egyptian Arabic-English speech corpus. We build our ASR systems using DNN-based hybrid and Transformer-based end-to-end models. In this paper, we present a thorough comparison between both approaches under the setting of a low-resource, orthographically unstandardized, and morphologically rich language pair. We show that while both systems give comparable overall recognition results, each system provides complementary sets of strength points. We show that recognition can be improved by combining the outputs of both systems. We propose several effective system combination approaches, where hypotheses of both systems are merged on sentence- and word-levels. Our approaches result in overall WER relative improvement of 4.7%, over a baseline performance of 32.1% WER. In the case of intra-sentential CS sentences, we achieve WER relative improvement of 4.8%. Our best performing system achieves 30.6% WER on ArzEn test set.