 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe IMS Toucan System for the Blizzard Challenge 2023
Oct 26, 2023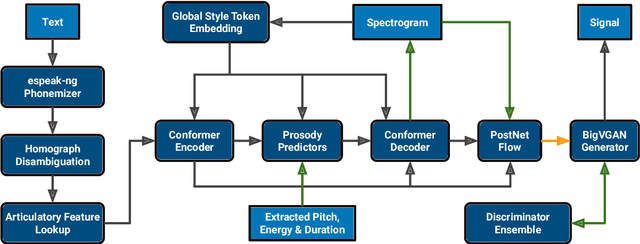
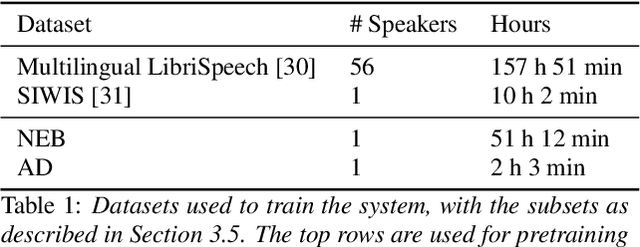
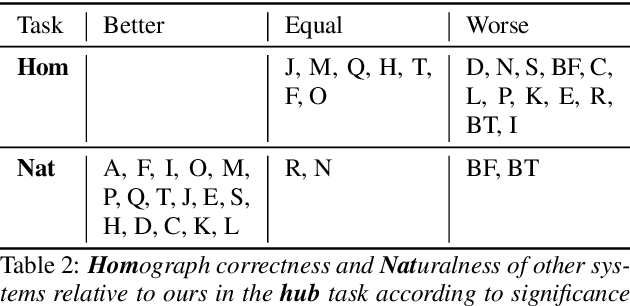
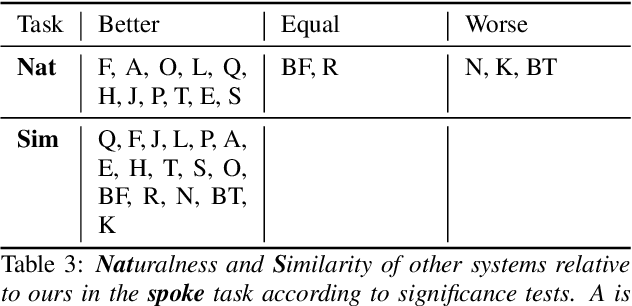
For our contribution to the Blizzard Challenge 2023, we improved on the system we submitted to the Blizzard Challenge 2021. Our approach entails a rule-based text-to-phoneme processing system that includes rule-based disambiguation of homographs in the French language. It then transforms the phonemes to spectrograms as intermediate representations using a fast and efficient non-autoregressive synthesis architecture based on Conformer and Glow. A GAN based neural vocoder that combines recent state-of-the-art approaches converts the spectrogram to the final wave. We carefully designed the data processing, training, and inference procedures for the challenge data. Our system identifier is G. Open source code and demo are available.
Anonymizing Speech with Generative Adversarial Networks to Preserve Speaker Privacy
Oct 20, 2022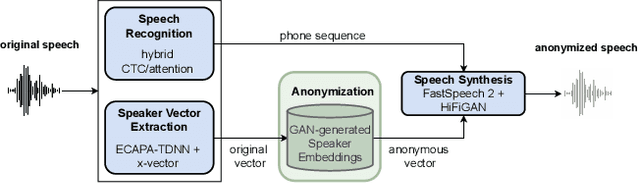
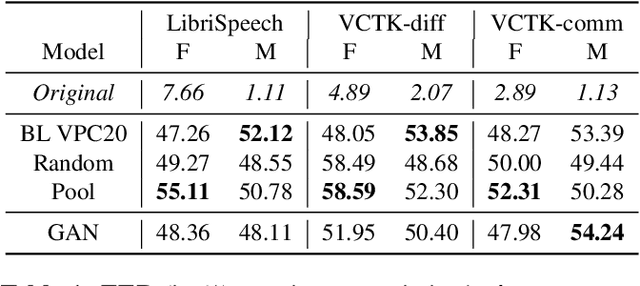
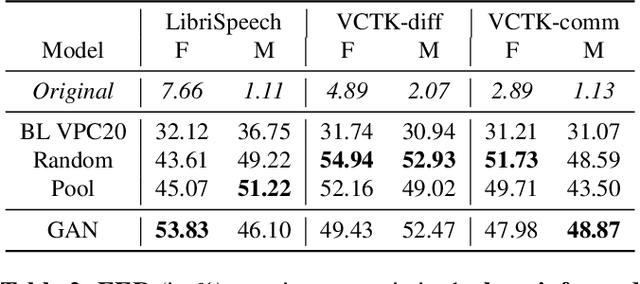
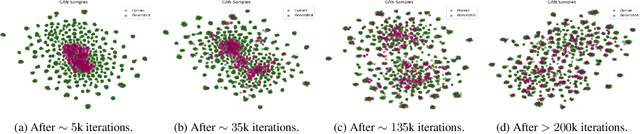
In order to protect the privacy of speech data, speaker anonymization aims for hiding the identity of a speaker by changing the voice in speech recordings. This typically comes with a privacy-utility trade-off between protection of individuals and usability of the data for downstream applications. One of the challenges in this context is to create non-existent voices that sound as natural as possible. In this work, we propose to tackle this issue by generating speaker embeddings using a generative adversarial network with Wasserstein distance as cost function. By incorporating these artificial embeddings into a speech-to-text-to-speech pipeline, we outperform previous approaches in terms of privacy and utility. According to standard objective metrics and human evaluation, our approach generates intelligible and content-preserving yet privacy-protecting versions of the original recordings.
PoeticTTS -- Controllable Poetry Reading for Literary Studies
Jul 11, 2022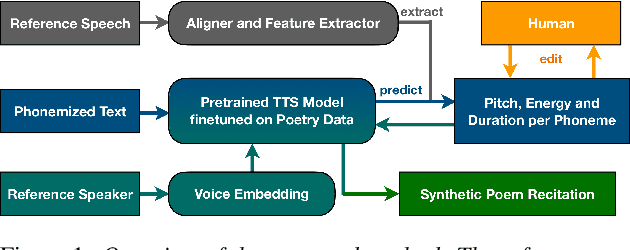
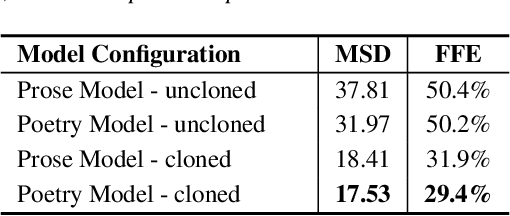
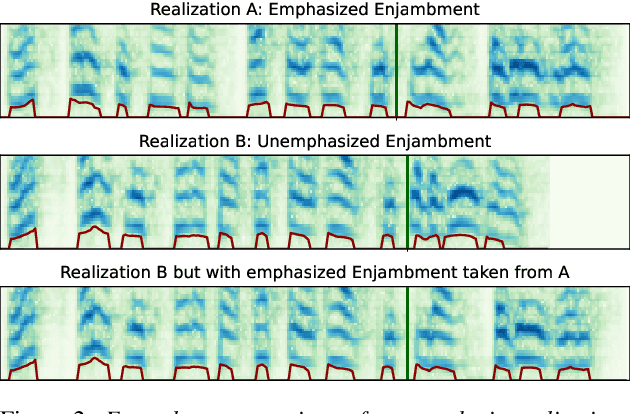
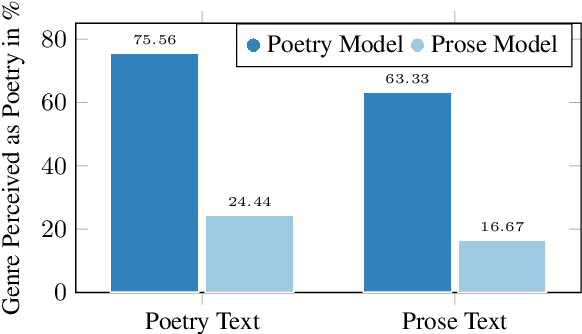
Speech synthesis for poetry is challenging due to specific intonation patterns inherent to poetic speech. In this work, we propose an approach to synthesise poems with almost human like naturalness in order to enable literary scholars to systematically examine hypotheses on the interplay between text, spoken realisation, and the listener's perception of poems. To meet these special requirements for literary studies, we resynthesise poems by cloning prosodic values from a human reference recitation, and afterwards make use of fine-grained prosody control to manipulate the synthetic speech in a human-in-the-loop setting to alter the recitation w.r.t. specific phenomena. We find that finetuning our TTS model on poetry captures poetic intonation patterns to a large extent which is beneficial for prosody cloning and manipulation and verify the success of our approach both in an objective evaluation as well as in human studies.
Speaker Anonymization with Phonetic Intermediate Representations
Jul 11, 2022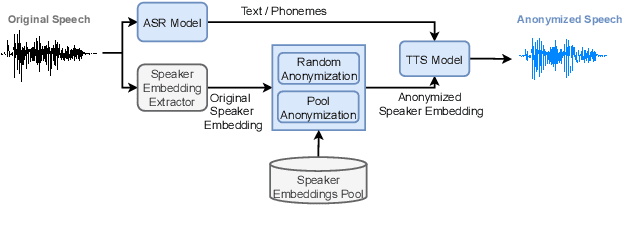
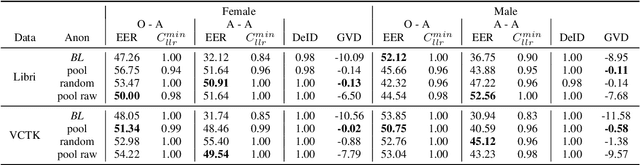
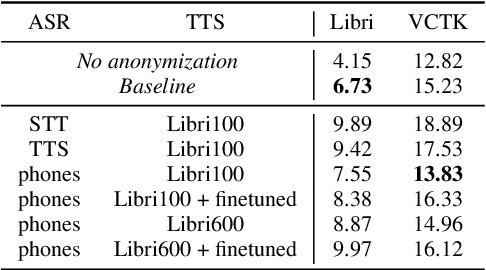

In this work, we propose a speaker anonymization pipeline that leverages high quality automatic speech recognition and synthesis systems to generate speech conditioned on phonetic transcriptions and anonymized speaker embeddings. Using phones as the intermediate representation ensures near complete elimination of speaker identity information from the input while preserving the original phonetic content as much as possible. Our experimental results on LibriSpeech and VCTK corpora reveal two key findings: 1) although automatic speech recognition produces imperfect transcriptions, our neural speech synthesis system can handle such errors, making our system feasible and robust, and 2) combining speaker embeddings from different resources is beneficial and their appropriate normalization is crucial. Overall, our final best system outperforms significantly the baselines provided in the Voice Privacy Challenge 2020 in terms of privacy robustness against a lazy-informed attacker while maintaining high intelligibility and naturalness of the anonymized speech.
Prosody Cloning in Zero-Shot Multispeaker Text-to-Speech
Jun 24, 2022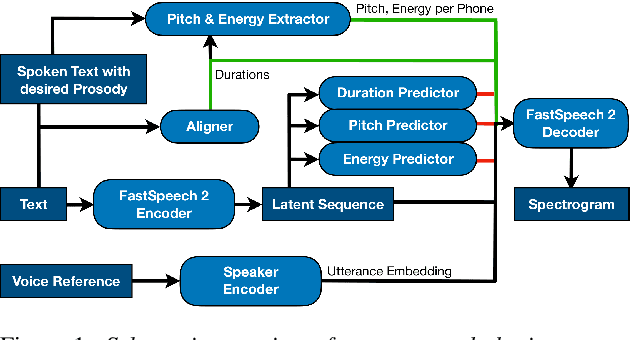
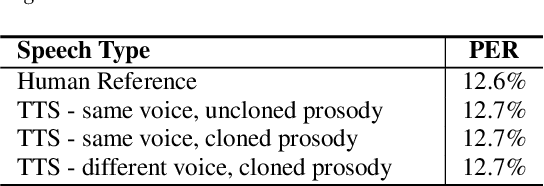

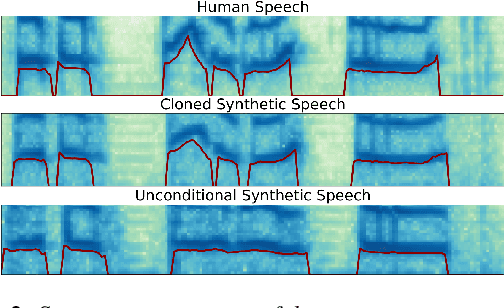
The cloning of a speaker's voice using an untranscribed reference sample is one of the great advances of modern neural text-to-speech (TTS) methods. Approaches for mimicking the prosody of a transcribed reference audio have also been proposed recently. In this work, we bring these two tasks together for the first time through utterance level normalization in conjunction with an utterance level speaker embedding. We further introduce a lightweight aligner for extracting fine-grained prosodic features, that can be finetuned on individual samples within seconds. We show that it is possible to clone the voice of a speaker as well as the prosody of a spoken reference independently without any degradation in quality and high similarity to both original voice and prosody, as our objective evaluation and human study show. All of our code and trained models are available, alongside static and interactive demos.