 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDspy-based Neural-Symbolic Pipeline to Enhance Spatial Reasoning in LLMs
Dec 12, 2024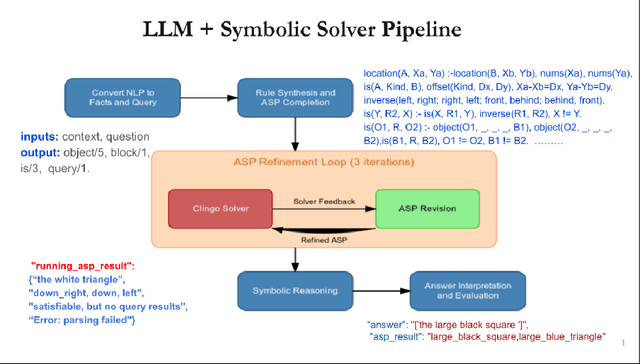
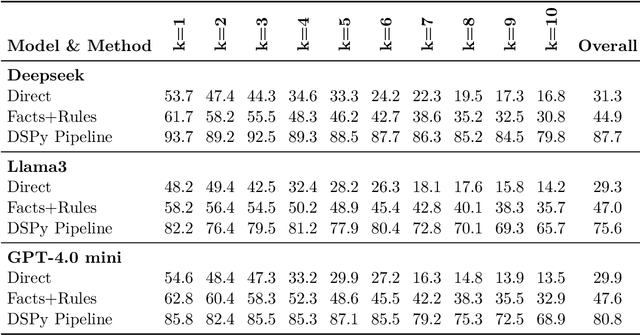
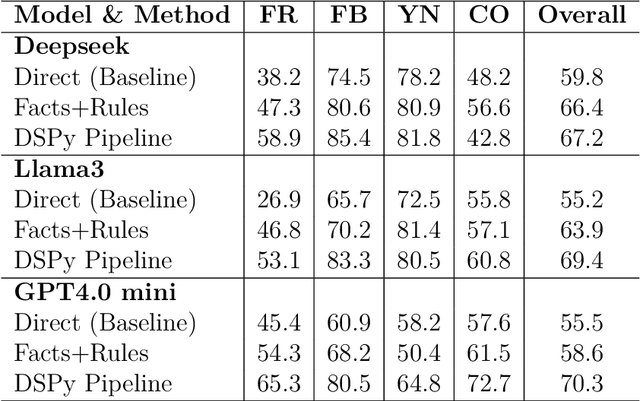
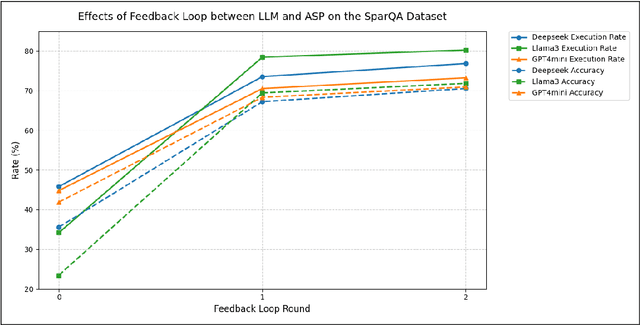
Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they often struggle with spatial reasoning. This paper presents a novel neural-symbolic framework that enhances LLMs' spatial reasoning abilities through iterative feedback between LLMs and Answer Set Programming (ASP). We evaluate our approach on two benchmark datasets: StepGame and SparQA, implementing three distinct strategies: (1) direct prompting baseline, (2) Facts+Rules prompting, and (3) DSPy-based LLM+ASP pipeline with iterative refinement. Our experimental results demonstrate that the LLM+ASP pipeline significantly outperforms baseline methods, achieving an average 82% accuracy on StepGame and 69% on SparQA, marking improvements of 40-50% and 8-15% respectively over direct prompting. The success stems from three key innovations: (1) effective separation of semantic parsing and logical reasoning through a modular pipeline, (2) iterative feedback mechanism between LLMs and ASP solvers that improves program rate, and (3) robust error handling that addresses parsing, grounding, and solving failures. Additionally, we propose Facts+Rules as a lightweight alternative that achieves comparable performance on complex SparQA dataset, while reducing computational overhead.Our analysis across different LLM architectures (Deepseek, Llama3-70B, GPT-4.0 mini) demonstrates the framework's generalizability and provides insights into the trade-offs between implementation complexity and reasoning capability, contributing to the development of more interpretable and reliable AI systems.
A Pipeline of Neural-Symbolic Integration to Enhance Spatial Reasoning in Large Language Models
Nov 27, 2024Large Language Models (LLMs) have demonstrated impressive capabilities across various tasks. However, LLMs often struggle with spatial reasoning which is one essential part of reasoning and inference and requires understanding complex relationships between objects in space. This paper proposes a novel neural-symbolic framework that enhances LLMs' spatial reasoning abilities. We evaluate our approach on two benchmark datasets: StepGame and SparQA, implementing three distinct strategies: (1) ASP (Answer Set Programming)-based symbolic reasoning, (2) LLM + ASP pipeline using DSPy, and (3) Fact + Logical rules. Our experiments demonstrate significant improvements over the baseline prompting methods, with accuracy increases of 40-50% on StepGame} dataset and 3-13% on the more complex SparQA dataset. The "LLM + ASP" pipeline achieves particularly strong results on the tasks of Finding Relations (FR) and Finding Block (FB) questions, though performance varies across different question types. The impressive results suggest that while neural-symbolic approaches offer promising directions for enhancing spatial reasoning in LLMs, their effectiveness depends heavily on the specific task characteristics and implementation strategies. We propose an integrated, simple yet effective set of strategies using a neural-symbolic pipeline to boost spatial reasoning abilities in LLMs. This pipeline and its strategies demonstrate strong and broader applicability to other reasoning domains in LLMs, such as temporal reasoning, deductive inference etc.
The DURel Annotation Tool: Human and Computational Measurement of Semantic Proximity, Sense Clusters and Semantic Change
Nov 21, 2023
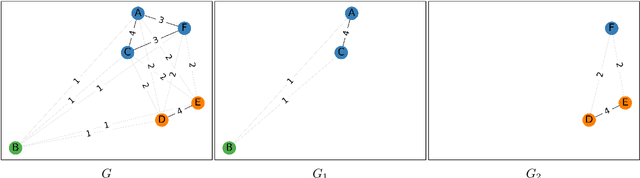


We present the DURel tool that implements the annotation of semantic proximity between uses of words into an online, open source interface. The tool supports standardized human annotation as well as computational annotation, building on recent advances with Word-in-Context models. Annotator judgments are clustered with automatic graph clustering techniques and visualized for analysis. This allows to measure word senses with simple and intuitive micro-task judgments between use pairs, requiring minimal preparation efforts. The tool offers additional functionalities to compare the agreement between annotators to guarantee the inter-subjectivity of the obtained judgments and to calculate summary statistics giving insights into sense frequency distributions, semantic variation or changes of senses over time.
PoeticTTS -- Controllable Poetry Reading for Literary Studies
Jul 11, 2022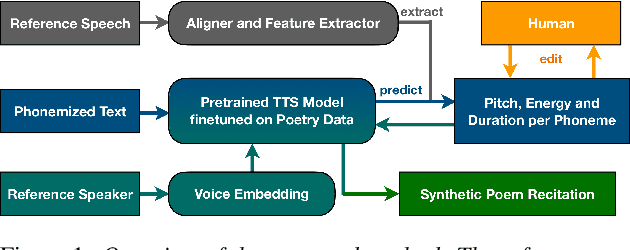
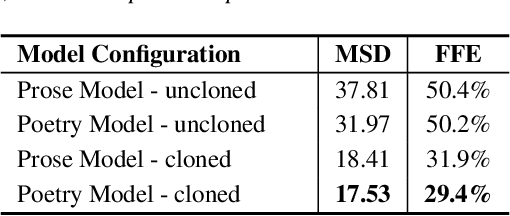
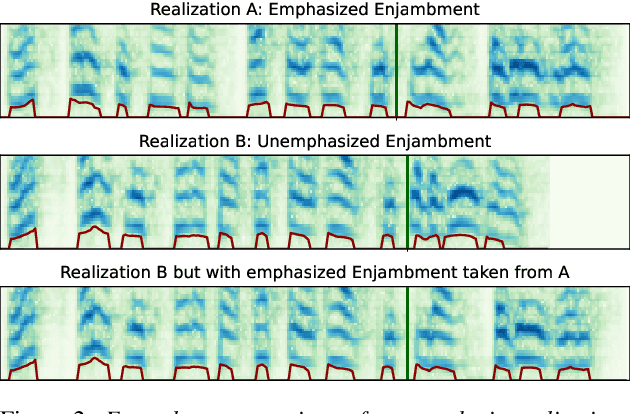
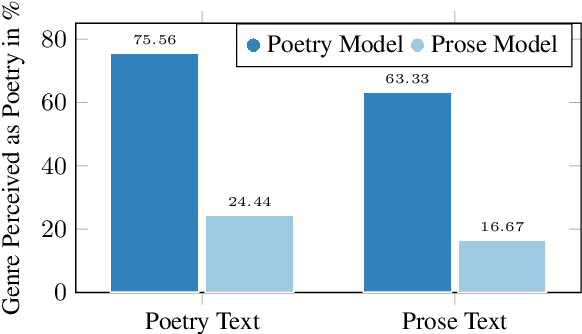
Speech synthesis for poetry is challenging due to specific intonation patterns inherent to poetic speech. In this work, we propose an approach to synthesise poems with almost human like naturalness in order to enable literary scholars to systematically examine hypotheses on the interplay between text, spoken realisation, and the listener's perception of poems. To meet these special requirements for literary studies, we resynthesise poems by cloning prosodic values from a human reference recitation, and afterwards make use of fine-grained prosody control to manipulate the synthetic speech in a human-in-the-loop setting to alter the recitation w.r.t. specific phenomena. We find that finetuning our TTS model on poetry captures poetic intonation patterns to a large extent which is beneficial for prosody cloning and manipulation and verify the success of our approach both in an objective evaluation as well as in human studies.
Between welcome culture and border fence. A dataset on the European refugee crisis in German newspaper reports
Nov 19, 2021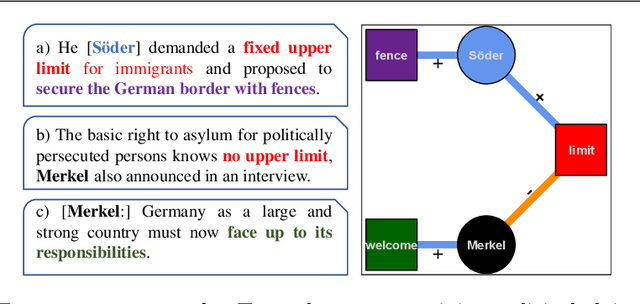
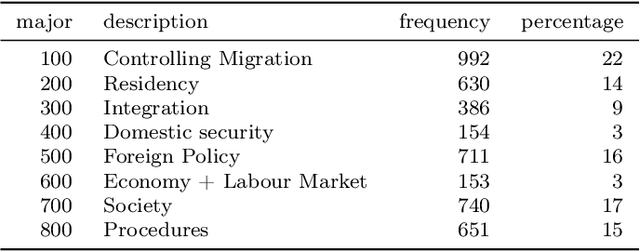
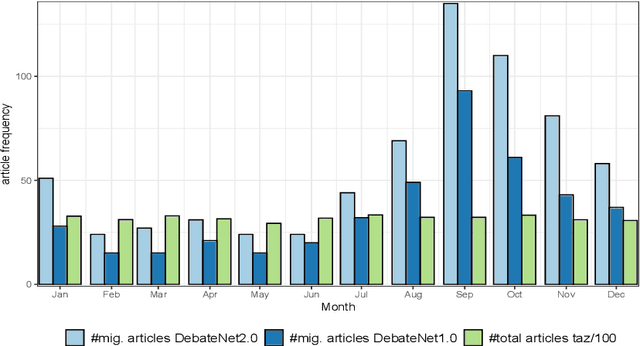
Newspaper reports provide a rich source of information on the unfolding of public debate on specific policy fields that can serve as basis for inquiry in political science. Such debates are often triggered by critical events, which attract public attention and incite the reactions of political actors: crisis sparks the debate. However, due to the challenges of reliable annotation and modeling, few large-scale datasets with high-quality annotation are available. This paper introduces DebateNet2.0, which traces the political discourse on the European refugee crisis in the German quality newspaper taz during the year 2015. The core units of our annotation are political claims (requests for specific actions to be taken within the policy field) and the actors who make them (politicians, parties, etc.). The contribution of this paper is twofold. First, we document and release DebateNet2.0 along with its companion R package, mardyR, guiding the reader through the practical and conceptual issues related to the annotation of policy debates in newspapers. Second, we outline and apply a Discourse Network Analysis (DNA) to DebateNet2.0, comparing two crucial moments of the policy debate on the 'refugee crisis': the migration flux through the Mediterranean in April/May and the one along the Balkan route in September/October. Besides the released resources and the case-study, our contribution is also methodological: we talk the reader through the steps from a newspaper article to a discourse network, demonstrating that there is not just one discourse network for the German migration debate, but multiple ones, depending on the topic of interest (political actors, policy fields, time spans).
Negation-Instance Based Evaluation of End-to-End Negation Resolution
Sep 21, 2021
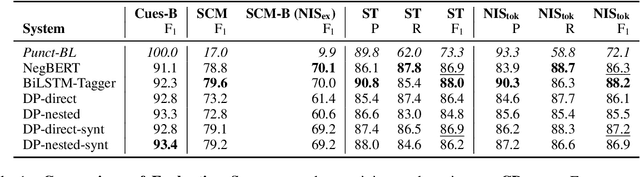
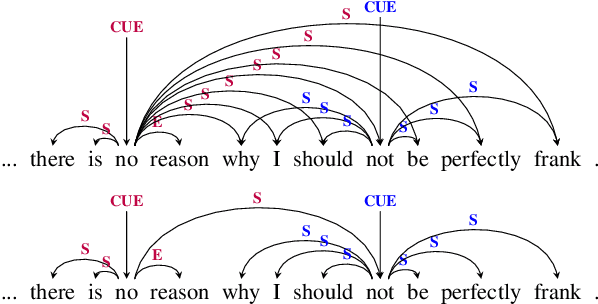
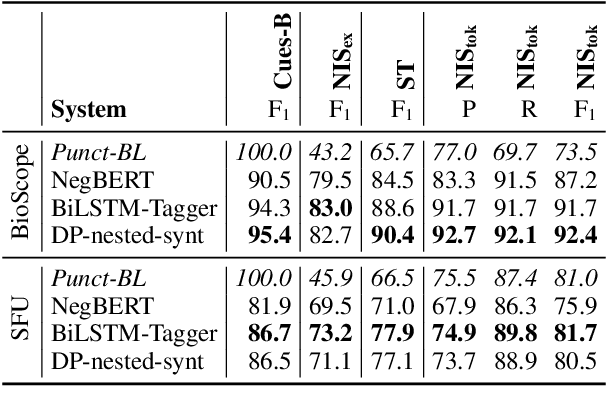
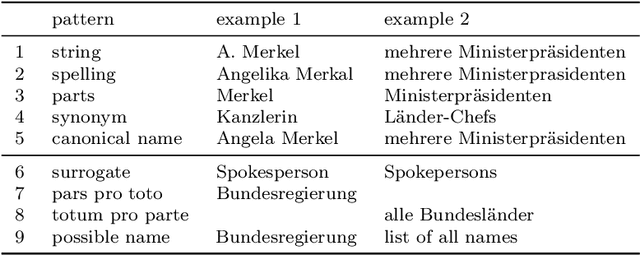
In this paper, we revisit the task of negation resolution, which includes the subtasks of cue detection (e.g. "not", "never") and scope resolution. In the context of previous shared tasks, a variety of evaluation metrics have been proposed. Subsequent works usually use different subsets of these, including variations and custom implementations, rendering meaningful comparisons between systems difficult. Examining the problem both from a linguistic perspective and from a downstream viewpoint, we here argue for a negation-instance based approach to evaluating negation resolution. Our proposed metrics correspond to expectations over per-instance scores and hence are intuitively interpretable. To render research comparable and to foster future work, we provide results for a set of current state-of-the-art systems for negation resolution on three English corpora, and make our implementation of the evaluation scripts publicly available.
Lexical Semantic Change Discovery
Jun 06, 2021
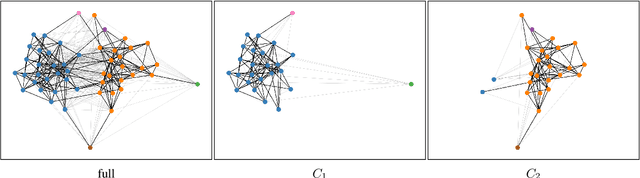

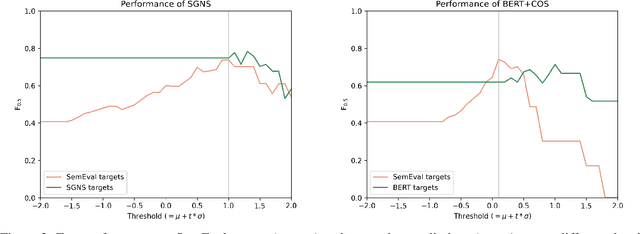
While there is a large amount of research in the field of Lexical Semantic Change Detection, only few approaches go beyond a standard benchmark evaluation of existing models. In this paper, we propose a shift of focus from change detection to change discovery, i.e., discovering novel word senses over time from the full corpus vocabulary. By heavily fine-tuning a type-based and a token-based approach on recently published German data, we demonstrate that both models can successfully be applied to discover new words undergoing meaning change. Furthermore, we provide an almost fully automated framework for both evaluation and discovery.
Explaining and Improving BERT Performance on Lexical Semantic Change Detection
Mar 12, 2021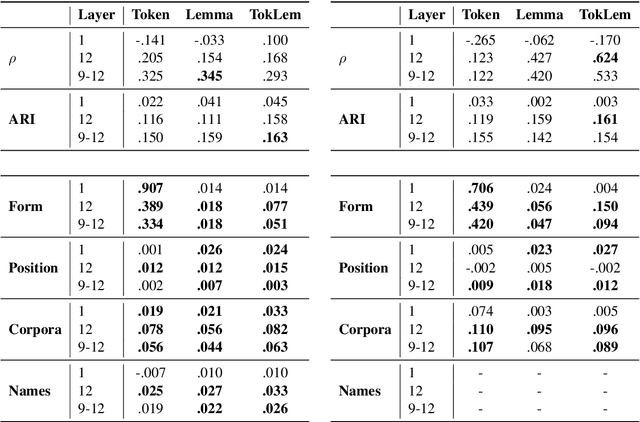
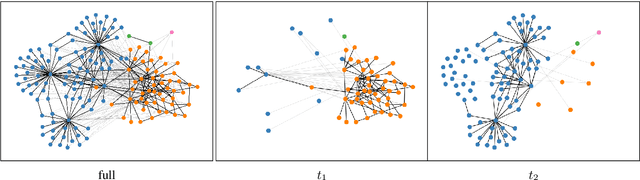
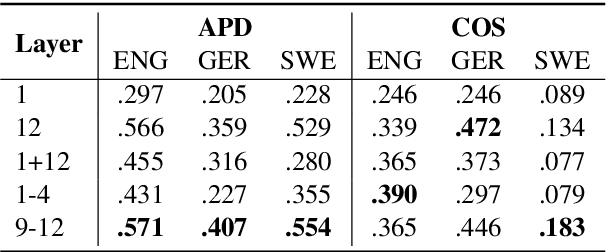
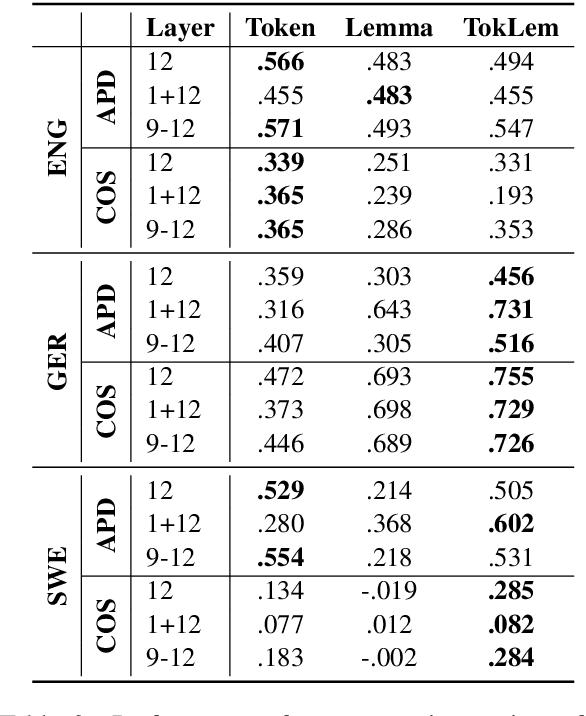
Type- and token-based embedding architectures are still competing in lexical semantic change detection. The recent success of type-based models in SemEval-2020 Task 1 has raised the question why the success of token-based models on a variety of other NLP tasks does not translate to our field. We investigate the influence of a range of variables on clusterings of BERT vectors and show that its low performance is largely due to orthographic information on the target word, which is encoded even in the higher layers of BERT representations. By reducing the influence of orthography we considerably improve BERT's performance.
Graph-Based Universal Dependency Parsing in the Age of the Transformer: What Works, and What Doesn't
Oct 23, 2020
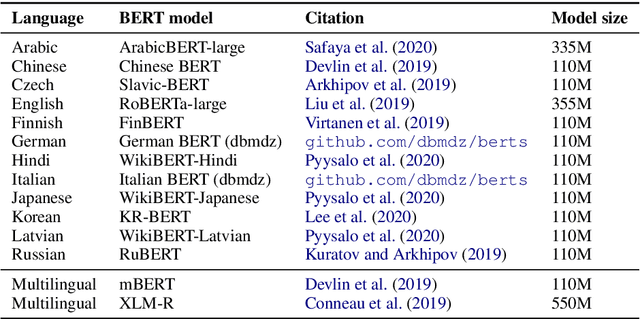
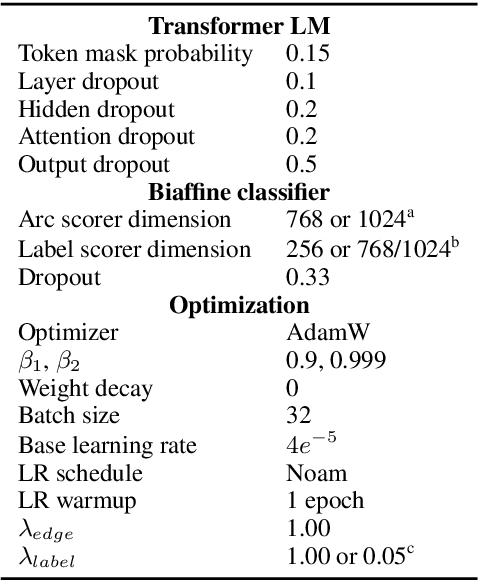
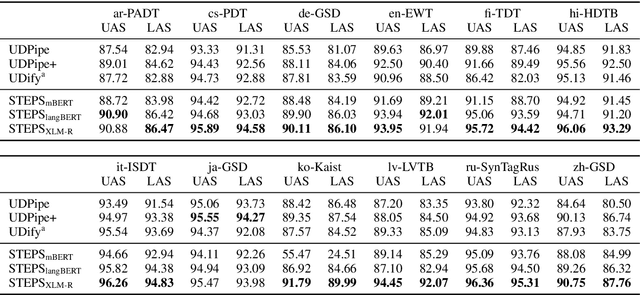
Current state-of-the-art graph-based dependency parsers differ on various dimensions. Among others, these include (a) the choice of pre-trained word embeddings or language models used for representing token, (b) training setups performing only parsing or additional tasks such as part-of-speech-tagging, and (c) their mechanism of constructing trees or graphs from edge scores. Because of this, it is difficult to estimate the impact of these architectural decisions when comparing parsers. In this paper, we perform a series of experiments on STEPS, a new modular graph-based parser for basic and enhanced Universal Dependencies, analyzing the effects of architectural configurations. We find that pre-trained embeddings have by far the greatest and most clear-cut impact on parser performance. The choice of factorized vs. unfactorized architectures and a multi-task training setup affect parsing accuracy in more subtle ways, depending on target language and output representation (trees vs. graphs). Our parser achieves new state-of-the-art results for a wide range of languages on both basic as well as enhanced Universal Dependencies, using a unified and comparatively simple architecture for both parsing tasks.
The Utility of Structural Features in BiLSTM-based Dependency Parsers
Jun 04, 2019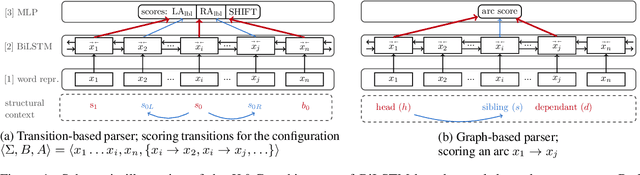

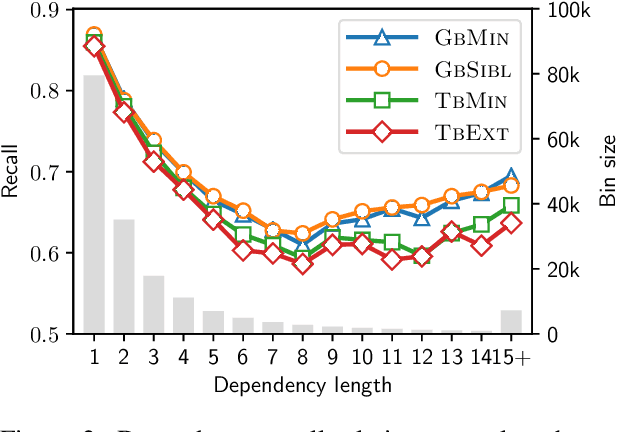

Classical non-neural dependency parsers put considerable effort on the design of feature functions. Especially, they benefit from information coming from structural features, such as features drawn from neighboring tokens in the dependency tree. In contrast, their BiLSTM-based successors achieve state-of-the-art performance without explicit information about the structural context. In this paper we aim to answer the question: How much structural context are the BiLSTM representations able to capture implicitly? We show that features drawn from partial subtrees become redundant when the BiLSTMs are used. We provide a deep insight into information flow in transition- and graph-based neural architectures to demonstrate where the implicit information comes from when the parsers make their decisions. Finally, with model ablations we demonstrate that the structural context is not only present in the models, but it significantly influences their performance.