 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Non-recorded Word Senses in English and Swedish
Mar 04, 2024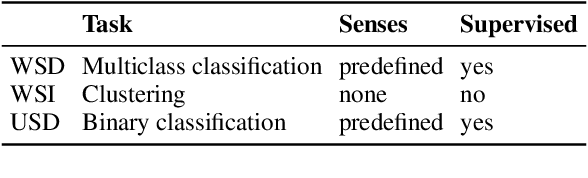
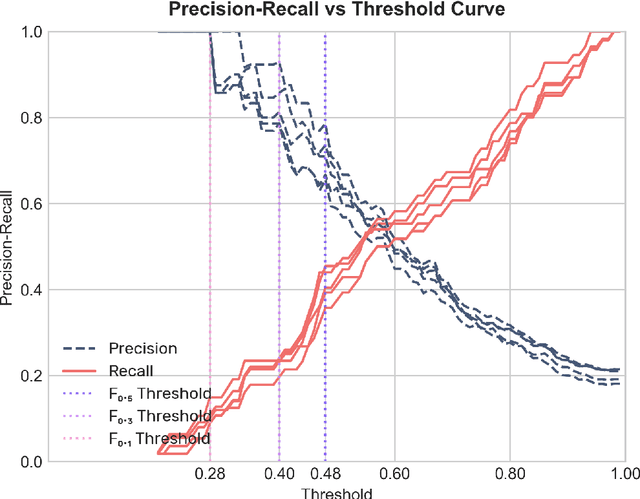

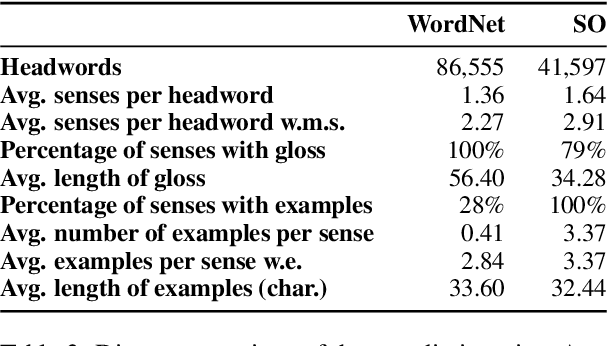
This study addresses the task of Unknown Sense Detection in English and Swedish. The primary objective of this task is to determine whether the meaning of a particular word usage is documented in a dictionary or not. For this purpose, sense entries are compared with word usages from modern and historical corpora using a pre-trained Word-in-Context embedder that allows us to model this task in a few-shot scenario. Additionally, we use human annotations to adapt and evaluate our models. Compared to a random sample from a corpus, our model is able to considerably increase the detected number of word usages with non-recorded senses.
The DURel Annotation Tool: Human and Computational Measurement of Semantic Proximity, Sense Clusters and Semantic Change
Nov 21, 2023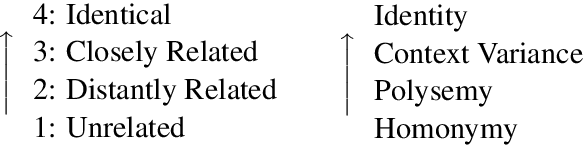
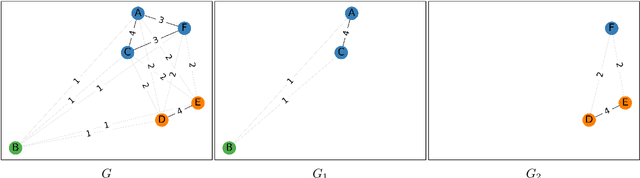


We present the DURel tool that implements the annotation of semantic proximity between uses of words into an online, open source interface. The tool supports standardized human annotation as well as computational annotation, building on recent advances with Word-in-Context models. Annotator judgments are clustered with automatic graph clustering techniques and visualized for analysis. This allows to measure word senses with simple and intuitive micro-task judgments between use pairs, requiring minimal preparation efforts. The tool offers additional functionalities to compare the agreement between annotators to guarantee the inter-subjectivity of the obtained judgments and to calculate summary statistics giving insights into sense frequency distributions, semantic variation or changes of senses over time.