Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Non-recorded Word Senses in English and Swedish
Paper and Code
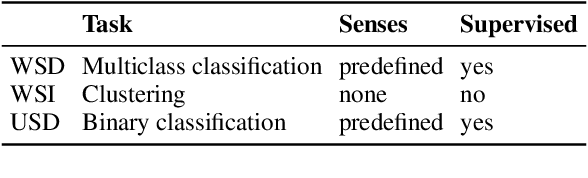
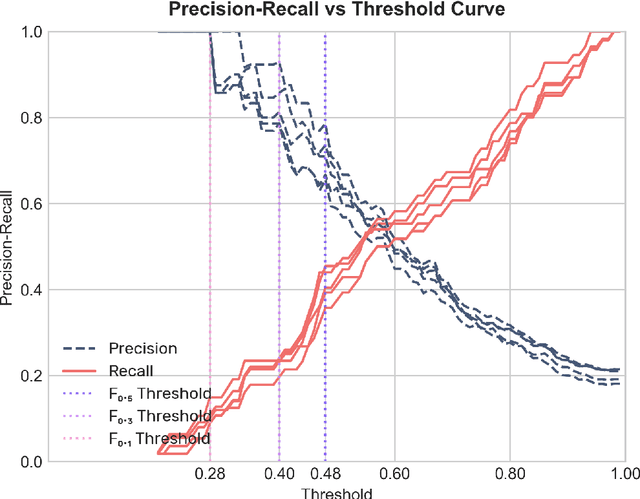

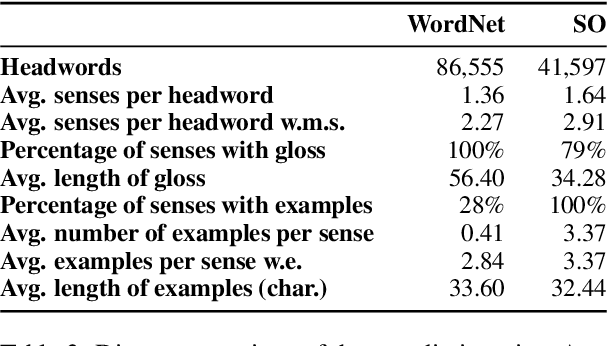
This study addresses the task of Unknown Sense Detection in English and Swedish. The primary objective of this task is to determine whether the meaning of a particular word usage is documented in a dictionary or not. For this purpose, sense entries are compared with word usages from modern and historical corpora using a pre-trained Word-in-Context embedder that allows us to model this task in a few-shot scenario. Additionally, we use human annotations to adapt and evaluate our models. Compared to a random sample from a corpus, our model is able to considerably increase the detected number of word usages with non-recorded senses.
* 9 pages
View paper on