 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabizi vs LLMs: Can the Genie Understand the Language of Aladdin?
Feb 28, 2025



In this era of rapid technological advancements, communication continues to evolve as new linguistic phenomena emerge. Among these is Arabizi, a hybrid form of Arabic that incorporates Latin characters and numbers to represent the spoken dialects of Arab communities. Arabizi is widely used on social media and allows people to communicate in an informal and dynamic way, but it poses significant challenges for machine translation due to its lack of formal structure and deeply embedded cultural nuances. This case study arises from a growing need to translate Arabizi for gisting purposes. It evaluates the capacity of different LLMs to decode and translate Arabizi, focusing on multiple Arabic dialects that have rarely been studied up until now. Using a combination of human evaluators and automatic metrics, this research project investigates the model's performance in translating Arabizi into both Modern Standard Arabic and English. Key questions explored include which dialects are translated most effectively and whether translations into English surpass those into Arabic.
Detection of Non-recorded Word Senses in English and Swedish
Mar 04, 2024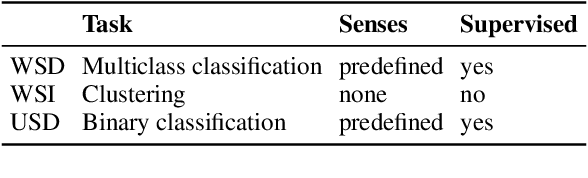
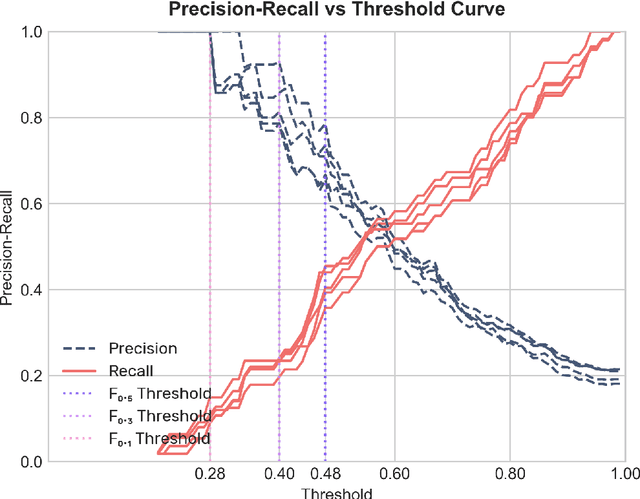

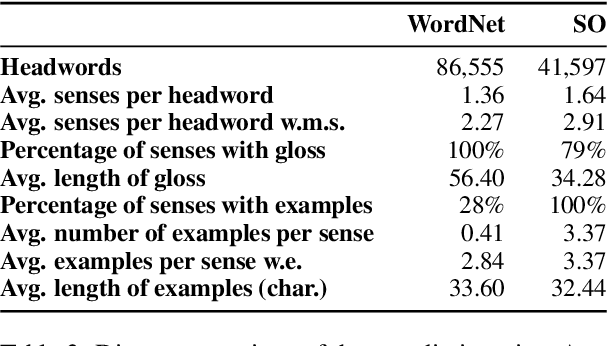
This study addresses the task of Unknown Sense Detection in English and Swedish. The primary objective of this task is to determine whether the meaning of a particular word usage is documented in a dictionary or not. For this purpose, sense entries are compared with word usages from modern and historical corpora using a pre-trained Word-in-Context embedder that allows us to model this task in a few-shot scenario. Additionally, we use human annotations to adapt and evaluate our models. Compared to a random sample from a corpus, our model is able to considerably increase the detected number of word usages with non-recorded senses.
DWUG: A large Resource of Diachronic Word Usage Graphs in Four Languages
Apr 17, 2021

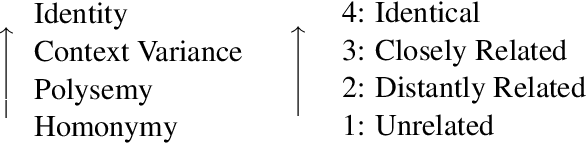

Word meaning is notoriously difficult to capture, both synchronically and diachronically. In this paper, we describe the creation of the largest resource of graded contextualized, diachronic word meaning annotation in four different languages, based on 100,000 human semantic proximity judgments. We thoroughly describe the multi-round incremental annotation process, the choice for a clustering algorithm to group usages into senses, and possible - diachronic and synchronic - uses for this dataset.
SuperSim: a test set for word similarity and relatedness in Swedish
Apr 12, 2021



Language models are notoriously difficult to evaluate. We release SuperSim, a large-scale similarity and relatedness test set for Swedish built with expert human judgments. The test set is composed of 1,360 word-pairs independently judged for both relatedness and similarity by five annotators. We evaluate three different models (Word2Vec, fastText, and GloVe) trained on two separate Swedish datasets, namely the Swedish Gigaword corpus and a Swedish Wikipedia dump, to provide a baseline for future comparison. We release the fully annotated test set, code, baseline models, and data.
Lexical semantic change for Ancient Greek and Latin
Jan 22, 2021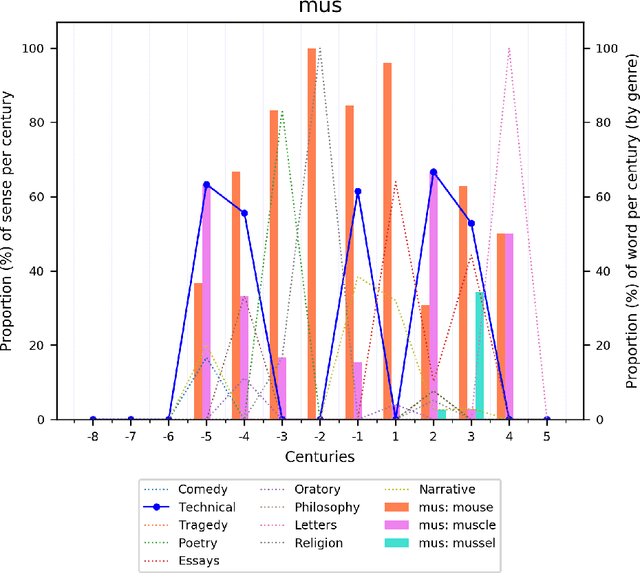
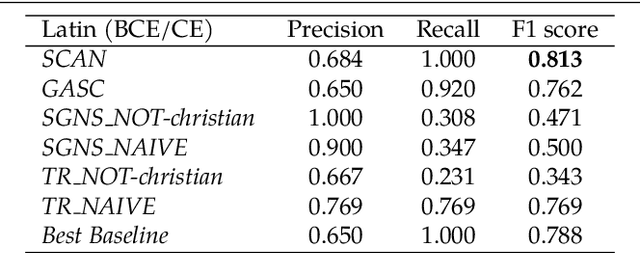
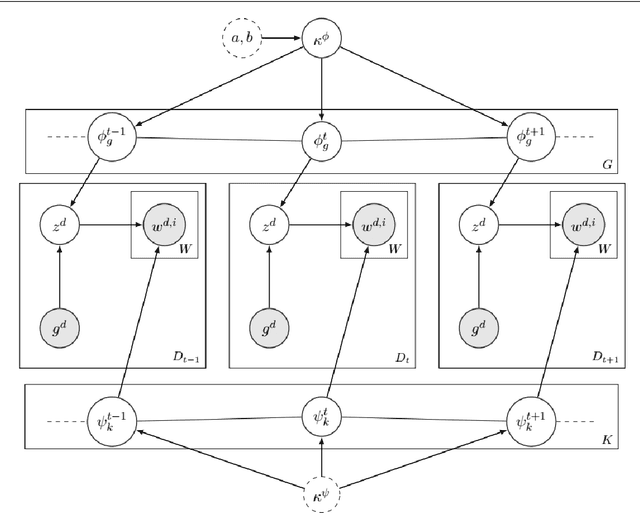
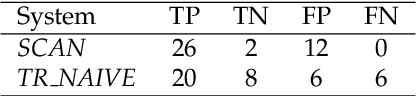
Change and its precondition, variation, are inherent in languages. Over time, new words enter the lexicon, others become obsolete, and existing words acquire new senses. Associating a word's correct meaning in its historical context is a central challenge in diachronic research. Historical corpora of classical languages, such as Ancient Greek and Latin, typically come with rich metadata, and existing models are limited by their inability to exploit contextual information beyond the document timestamp. While embedding-based methods feature among the current state of the art systems, they are lacking in the interpretative power. In contrast, Bayesian models provide explicit and interpretable representations of semantic change phenomena. In this chapter we build on GASC, a recent computational approach to semantic change based on a dynamic Bayesian mixture model. In this model, the evolution of word senses over time is based not only on distributional information of lexical nature, but also on text genres. We provide a systematic comparison of dynamic Bayesian mixture models for semantic change with state-of-the-art embedding-based models. On top of providing a full description of meaning change over time, we show that Bayesian mixture models are highly competitive approaches to detect binary semantic change in both Ancient Greek and Latin.
Challenges for Computational Lexical Semantic Change
Jan 19, 2021
The computational study of lexical semantic change (LSC) has taken off in the past few years and we are seeing increasing interest in the field, from both computational sciences and linguistics. Most of the research so far has focused on methods for modelling and detecting semantic change using large diachronic textual data, with the majority of the approaches employing neural embeddings. While methods that offer easy modelling of diachronic text are one of the main reasons for the spiking interest in LSC, neural models leave many aspects of the problem unsolved. The field has several open and complex challenges. In this chapter, we aim to describe the most important of these challenges and outline future directions.
Topic modelling discourse dynamics in historical newspapers
Nov 20, 2020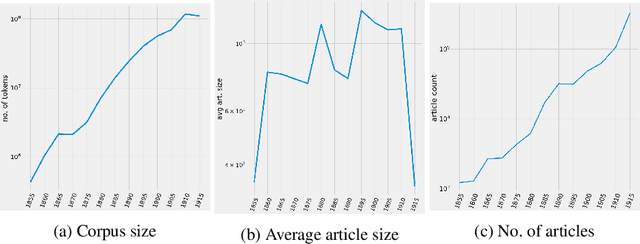
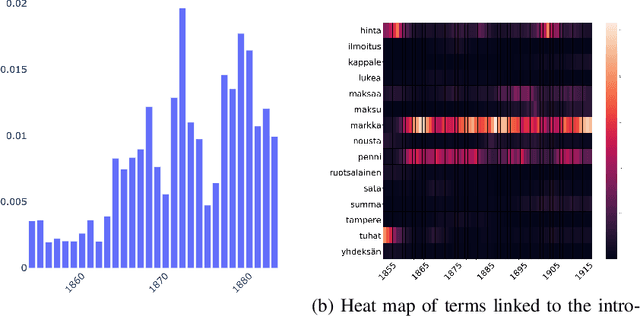
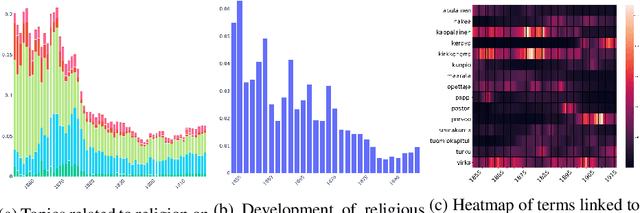
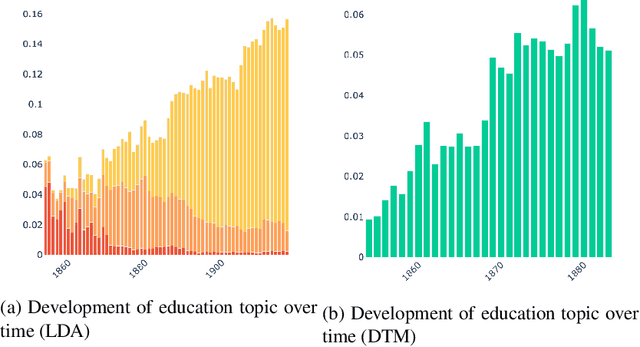
This paper addresses methodological issues in diachronic data analysis for historical research. We apply two families of topic models (LDA and DTM) on a relatively large set of historical newspapers, with the aim of capturing and understanding discourse dynamics. Our case study focuses on newspapers and periodicals published in Finland between 1854 and 1917, but our method can easily be transposed to any diachronic data. Our main contributions are a) a combined sampling, training and inference procedure for applying topic models to huge and imbalanced diachronic text collections; b) a discussion on the differences between two topic models for this type of data; c) quantifying topic prominence for a period and thus a generalization of document-wise topic assignment to a discourse level; and d) a discussion of the role of humanistic interpretation with regard to analysing discourse dynamics through topic models.
An Unsupervised method for OCR Post-Correction and Spelling Normalisation for Finnish
Nov 06, 2020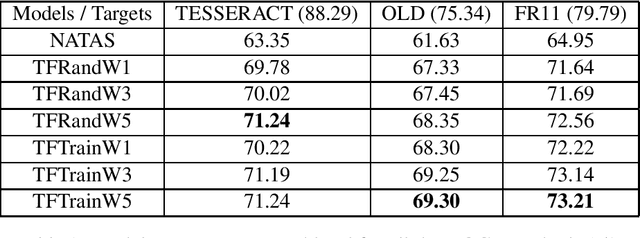
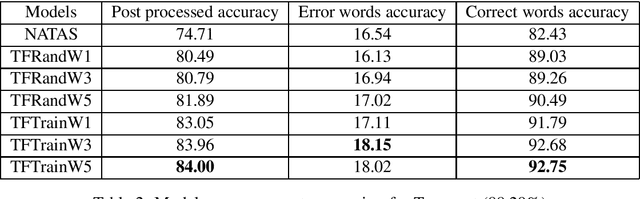


Historical corpora are known to contain errors introduced by OCR (optical character recognition) methods used in the digitization process, often said to be degrading the performance of NLP systems. Correcting these errors manually is a time-consuming process and a great part of the automatic approaches have been relying on rules or supervised machine learning. We build on previous work on fully automatic unsupervised extraction of parallel data to train a character-based sequence-to-sequence NMT (neural machine translation) model to conduct OCR error correction designed for English, and adapt it to Finnish by proposing solutions that take the rich morphology of the language into account. Our new method shows increased performance while remaining fully unsupervised, with the added benefit of spelling normalisation. The source code and models are available on GitHub and Zenodo.
SemEval-2020 Task 1: Unsupervised Lexical Semantic Change Detection
Aug 28, 2020
Lexical Semantic Change detection, i.e., the task of identifying words that change meaning over time, is a very active research area, with applications in NLP, lexicography, and linguistics. Evaluation is currently the most pressing problem in Lexical Semantic Change detection, as no gold standards are available to the community, which hinders progress. We present the results of the first shared task that addresses this gap by providing researchers with an evaluation framework and manually annotated, high-quality datasets for English, German, Latin, and Swedish. 33 teams submitted 186 systems, which were evaluated on two subtasks.
From the Paft to the Fiiture: a Fully Automatic NMT and Word Embeddings Method for OCR Post-Correction
Oct 12, 2019

A great deal of historical corpora suffer from errors introduced by the OCR (optical character recognition) methods used in the digitization process. Correcting these errors manually is a time-consuming process and a great part of the automatic approaches have been relying on rules or supervised machine learning. We present a fully automatic unsupervised way of extracting parallel data for training a character-based sequence-to-sequence NMT (neural machine translation) model to conduct OCR error correction.