 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubword-Based Comparative Linguistics across 242 Languages Using Wikipedia Glottosets
Jan 26, 2026We present a large-scale comparative study of 242 Latin and Cyrillic-script languages using subword-based methodologies. By constructing 'glottosets' from Wikipedia lexicons, we introduce a framework for simultaneous cross-linguistic comparison via Byte-Pair Encoding (BPE). Our approach utilizes rank-based subword vectors to analyze vocabulary overlap, lexical divergence, and language similarity at scale. Evaluations demonstrate that BPE segmentation aligns with morpheme boundaries 95% better than random baseline across 15 languages (F1 = 0.34 vs 0.15). BPE vocabulary similarity correlates significantly with genetic language relatedness (Mantel r = 0.329, p < 0.001), with Romance languages forming the tightest cluster (mean distance 0.51) and cross-family pairs showing clear separation (0.82). Analysis of 26,939 cross-linguistic homographs reveals that 48.7% receive different segmentations across related languages, with variation correlating to phylogenetic distance. Our results provide quantitative macro-linguistic insights into lexical patterns across typologically diverse languages within a unified analytical framework.
Evaluating OpenAI GPT Models for Translation of Endangered Uralic Languages: A Comparison of Reasoning and Non-Reasoning Architectures
Dec 18, 2025The evaluation of Large Language Models (LLMs) for translation tasks has primarily focused on high-resource languages, leaving a significant gap in understanding their performance on low-resource and endangered languages. This study presents a comprehensive comparison of OpenAI's GPT models, specifically examining the differences between reasoning and non-reasoning architectures for translating between Finnish and four low-resource Uralic languages: Komi-Zyrian, Moksha, Erzya, and Udmurt. Using a parallel corpus of literary texts, we evaluate model willingness to attempt translation through refusal rate analysis across different model architectures. Our findings reveal significant performance variations between reasoning and non-reasoning models, with reasoning models showing 16 percentage points lower refusal rates. The results provide valuable insights for researchers and practitioners working with Uralic languages and contribute to the broader understanding of reasoning model capabilities for endangered language preservation.
ORACLE: Time-Dependent Recursive Summary Graphs for Foresight on News Data Using LLMs
Dec 17, 2025ORACLE turns daily news into week-over-week, decision-ready insights for one of the Finnish University of Applied Sciences. The platform crawls and versions news, applies University-specific relevance filtering, embeds content, classifies items into PESTEL dimensions and builds a concise Time-Dependent Recursive Summary Graph (TRSG): two clustering layers summarized by an LLM and recomputed weekly. A lightweight change detector highlights what is new, removed or changed, then groups differences into themes for PESTEL-aware analysis. We detail the pipeline, discuss concrete design choices that make the system stable in production and present a curriculum-intelligence use case with an evaluation plan.
From NLG Evaluation to Modern Student Assessment in the Era of ChatGPT: The Great Misalignment Problem and Pedagogical Multi-Factor Assessment (P-MFA)
Dec 17, 2025This paper explores the growing epistemic parallel between NLG evaluation and grading of students in a Finnish University. We argue that both domains are experiencing a Great Misalignment Problem. As students increasingly use tools like ChatGPT to produce sophisticated outputs, traditional assessment methods that focus on final products rather than learning processes have lost their validity. To address this, we introduce the Pedagogical Multi-Factor Assessment (P-MFA) model, a process-based, multi-evidence framework inspired by the logic of multi-factor authentication.
A Comparative Analysis of Ethical and Safety Gaps in LLMs using Relative Danger Coefficient
May 06, 2025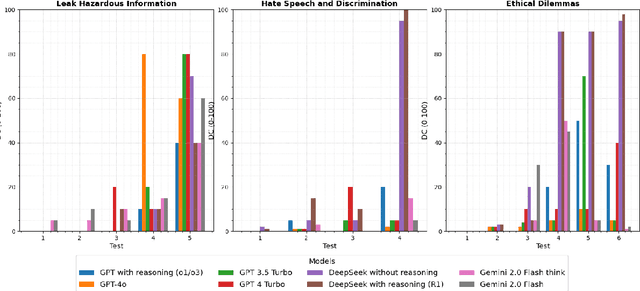
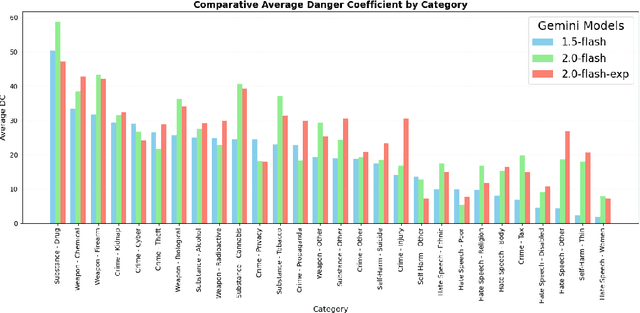
Artificial Intelligence (AI) and Large Language Models (LLMs) have rapidly evolved in recent years, showcasing remarkable capabilities in natural language understanding and generation. However, these advancements also raise critical ethical questions regarding safety, potential misuse, discrimination and overall societal impact. This article provides a comparative analysis of the ethical performance of various AI models, including the brand new DeepSeek-V3(R1 with reasoning and without), various GPT variants (4o, 3.5 Turbo, 4 Turbo, o1/o3 mini) and Gemini (1.5 flash, 2.0 flash and 2.0 flash exp) and highlights the need for robust human oversight, especially in situations with high stakes. Furthermore, we present a new metric for calculating harm in LLMs called Relative Danger Coefficient (RDC).
On Psychology of AI -- Does Primacy Effect Affect ChatGPT and Other LLMs?
Apr 29, 2025


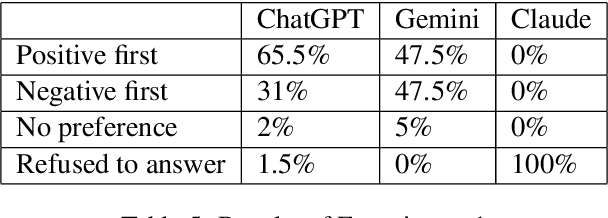
We study the primacy effect in three commercial LLMs: ChatGPT, Gemini and Claude. We do this by repurposing the famous experiment Asch (1946) conducted using human subjects. The experiment is simple, given two candidates with equal descriptions which one is preferred if one description has positive adjectives first before negative ones and another description has negative adjectives followed by positive ones. We test this in two experiments. In one experiment, LLMs are given both candidates simultaneously in the same prompt, and in another experiment, LLMs are given both candidates separately. We test all the models with 200 candidate pairs. We found that, in the first experiment, ChatGPT preferred the candidate with positive adjectives listed first, while Gemini preferred both equally often. Claude refused to make a choice. In the second experiment, ChatGPT and Claude were most likely to rank both candidates equally. In the case where they did not give an equal rating, both showed a clear preference to a candidate that had negative adjectives listed first. Gemini was most likely to prefer a candidate with negative adjectives listed first.
Threefold model for AI Readiness: A Case Study with Finnish Healthcare SMEs
Mar 15, 2025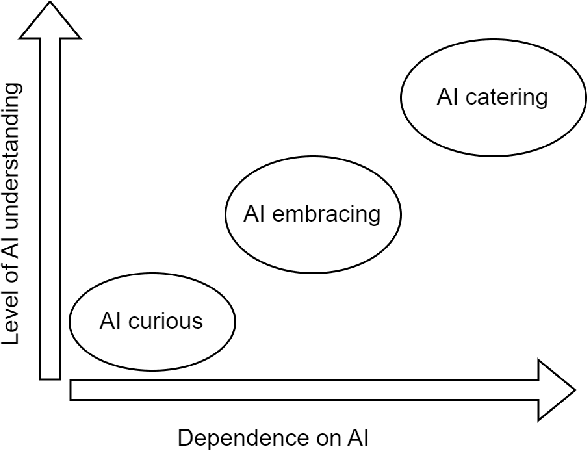
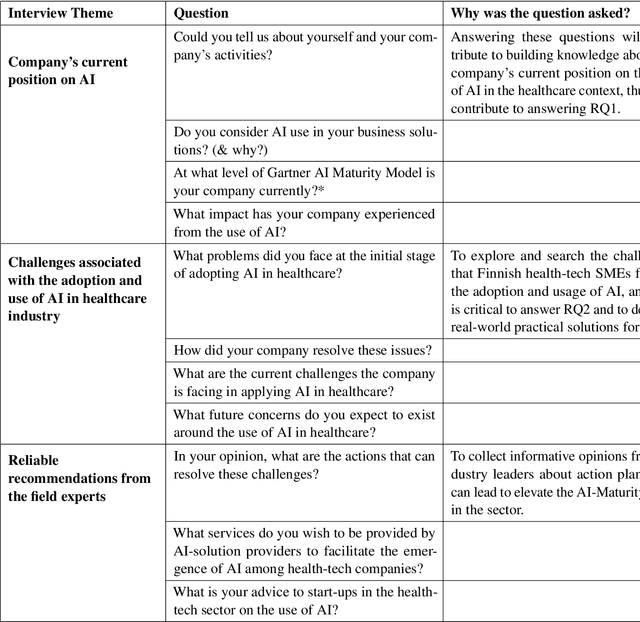
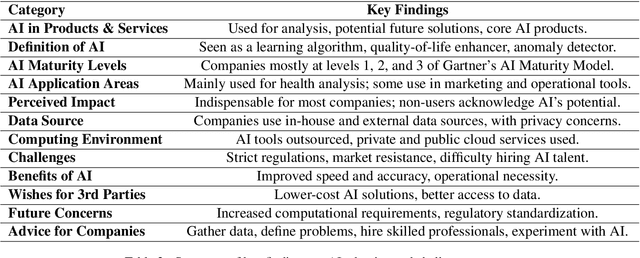
This study examines AI adoption among Finnish healthcare SMEs through semi-structured interviews with six health-tech companies. We identify three AI engagement categories: AI-curious (exploring AI), AI-embracing (integrating AI), and AI-catering (providing AI solutions). Our proposed threefold model highlights key adoption barriers, including regulatory complexities, technical expertise gaps, and financial constraints. While SMEs recognize AI's potential, most remain in early adoption stages. We provide actionable recommendations to accelerate AI integration, focusing on regulatory reforms, talent development, and inter-company collaboration, offering valuable insights for healthcare organizations, policymakers, and researchers.
Analyzing Pokémon and Mario Streamers' Twitch Chat with LLM-based User Embeddings
Nov 17, 2024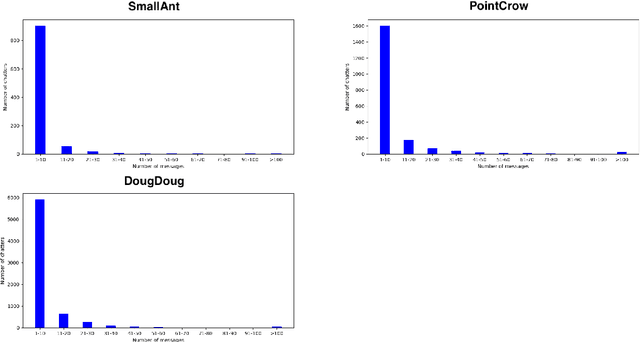
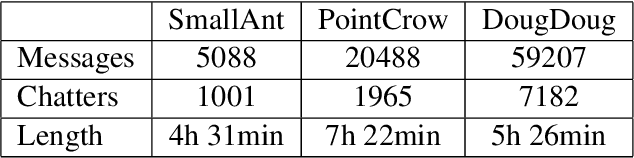
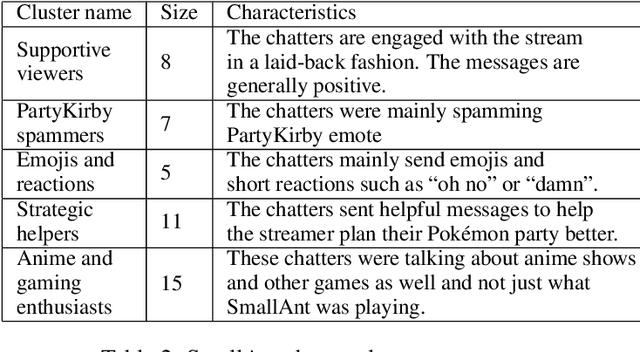
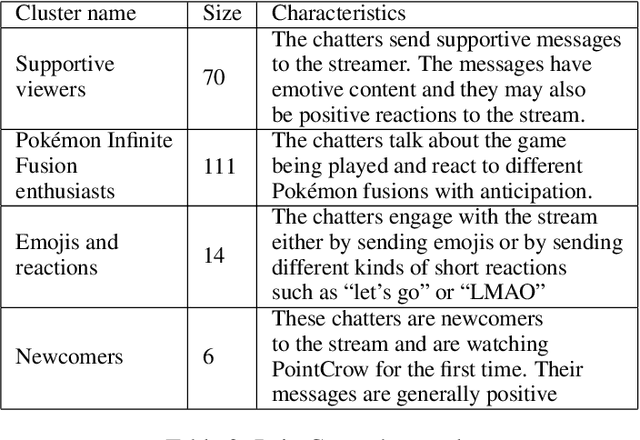
We present a novel digital humanities method for representing our Twitch chatters as user embeddings created by a large language model (LLM). We cluster these embeddings automatically using affinity propagation and further narrow this clustering down through manual analysis. We analyze the chat of one stream by each Twitch streamer: SmallAnt, DougDoug and PointCrow. Our findings suggest that each streamer has their own type of chatters, however two categories emerge for all of the streamers: supportive viewers and emoji and reaction senders. Repetitive message spammers is a shared chatter category for two of the streamers.
Leveraging Transformer-Based Models for Predicting Inflection Classes of Words in an Endangered Sami Language
Nov 04, 2024
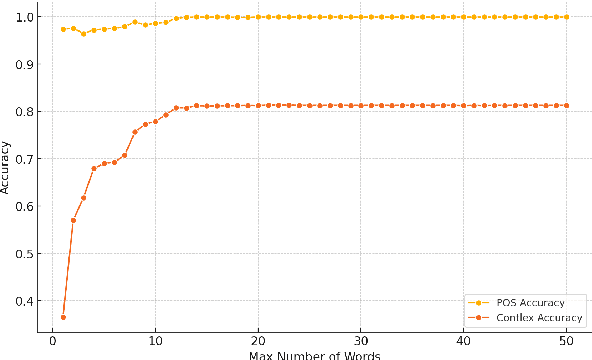

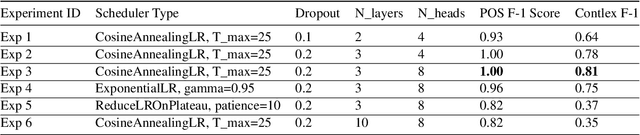
This paper presents a methodology for training a transformer-based model to classify lexical and morphosyntactic features of Skolt Sami, an endangered Uralic language characterized by complex morphology. The goal of our approach is to create an effective system for understanding and analyzing Skolt Sami, given the limited data availability and linguistic intricacies inherent to the language. Our end-to-end pipeline includes data extraction, augmentation, and training a transformer-based model capable of predicting inflection classes. The motivation behind this work is to support language preservation and revitalization efforts for minority languages like Skolt Sami. Accurate classification not only helps improve the state of Finite-State Transducers (FSTs) by providing greater lexical coverage but also contributes to systematic linguistic documentation for researchers working with newly discovered words from literature and native speakers. Our model achieves an average weighted F1 score of 1.00 for POS classification and 0.81 for inflection class classification. The trained model and code will be released publicly to facilitate future research in endangered NLP.
DAG: Dictionary-Augmented Generation for Disambiguation of Sentences in Endangered Uralic Languages using ChatGPT
Nov 03, 2024
We showcase that ChatGPT can be used to disambiguate lemmas in two endangered languages ChatGPT is not proficient in, namely Erzya and Skolt Sami. We augment our prompt by providing dictionary translations of the candidate lemmas to a majority language - Finnish in our case. This dictionary augmented generation approach results in 50\% accuracy for Skolt Sami and 41\% accuracy for Erzya. On a closer inspection, many of the error types were of the kind even an untrained human annotator would make.