 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Pokémon and Mario Streamers' Twitch Chat with LLM-based User Embeddings
Nov 17, 2024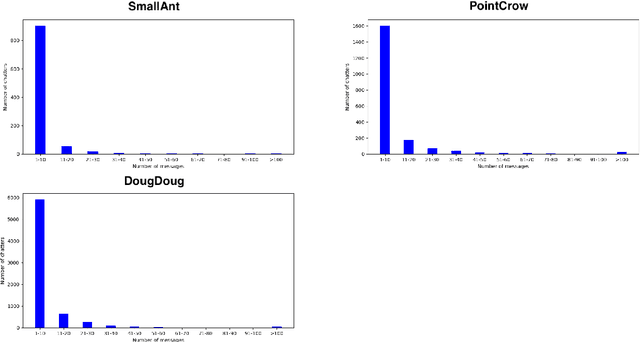
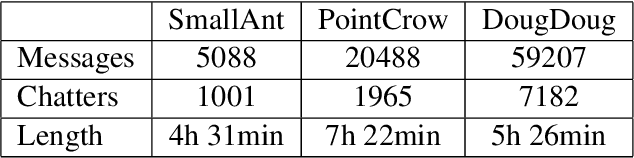
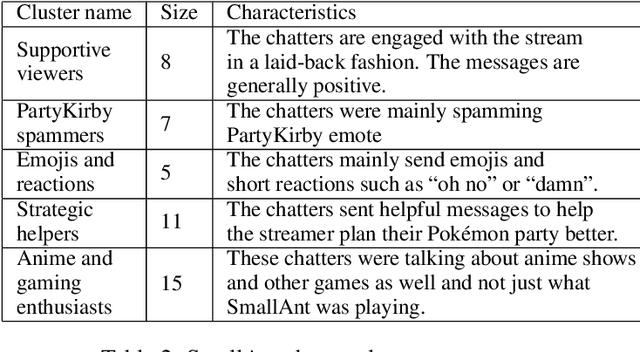
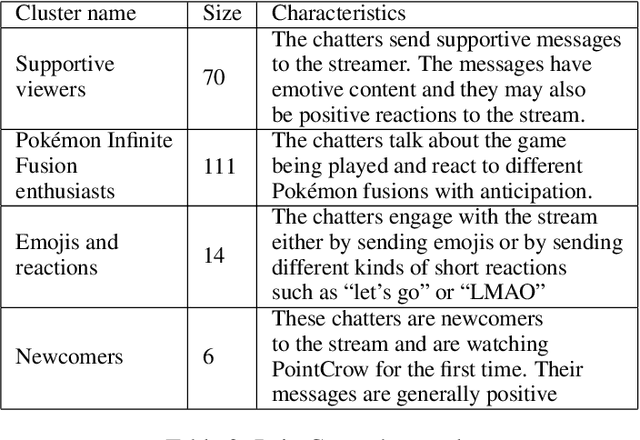
We present a novel digital humanities method for representing our Twitch chatters as user embeddings created by a large language model (LLM). We cluster these embeddings automatically using affinity propagation and further narrow this clustering down through manual analysis. We analyze the chat of one stream by each Twitch streamer: SmallAnt, DougDoug and PointCrow. Our findings suggest that each streamer has their own type of chatters, however two categories emerge for all of the streamers: supportive viewers and emoji and reaction senders. Repetitive message spammers is a shared chatter category for two of the streamers.
Leveraging Transformer-Based Models for Predicting Inflection Classes of Words in an Endangered Sami Language
Nov 04, 2024
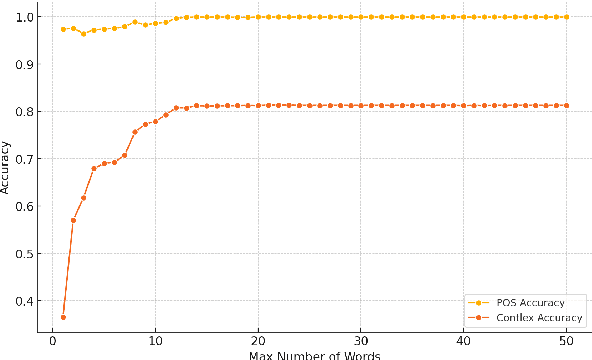

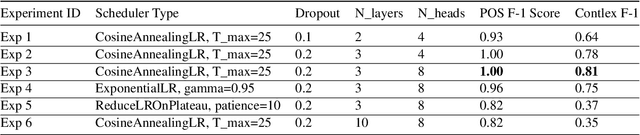
This paper presents a methodology for training a transformer-based model to classify lexical and morphosyntactic features of Skolt Sami, an endangered Uralic language characterized by complex morphology. The goal of our approach is to create an effective system for understanding and analyzing Skolt Sami, given the limited data availability and linguistic intricacies inherent to the language. Our end-to-end pipeline includes data extraction, augmentation, and training a transformer-based model capable of predicting inflection classes. The motivation behind this work is to support language preservation and revitalization efforts for minority languages like Skolt Sami. Accurate classification not only helps improve the state of Finite-State Transducers (FSTs) by providing greater lexical coverage but also contributes to systematic linguistic documentation for researchers working with newly discovered words from literature and native speakers. Our model achieves an average weighted F1 score of 1.00 for POS classification and 0.81 for inflection class classification. The trained model and code will be released publicly to facilitate future research in endangered NLP.
Sentiment Analysis Using Aligned Word Embeddings for Uralic Languages
May 24, 2023
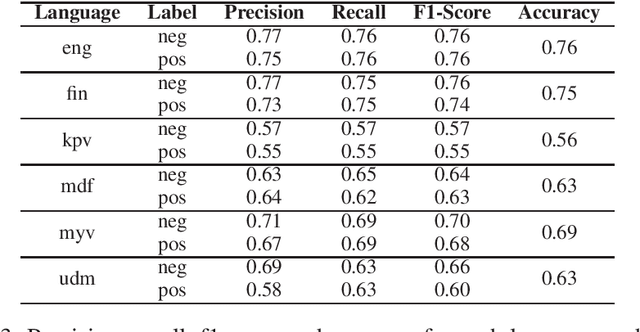
In this paper, we present an approach for translating word embeddings from a majority language into 4 minority languages: Erzya, Moksha, Udmurt and Komi-Zyrian. Furthermore, we align these word embeddings and present a novel neural network model that is trained on English data to conduct sentiment analysis and then applied on endangered language data through the aligned word embeddings. To test our model, we annotated a small sentiment analysis corpus for the 4 endangered languages and Finnish. Our method reached at least 56\% accuracy for each endangered language. The models and the sentiment corpus will be released together with this paper. Our research shows that state-of-the-art neural models can be used with endangered languages with the only requirement being a dictionary between the endangered language and a majority language.
Processing M.A. Castrén's Materials: Multilingual Typed and Handwritten Manuscripts
Dec 28, 2021
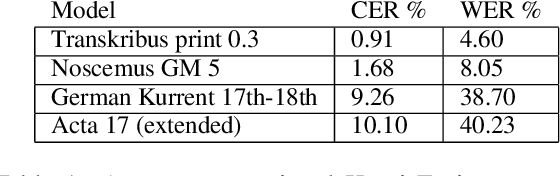
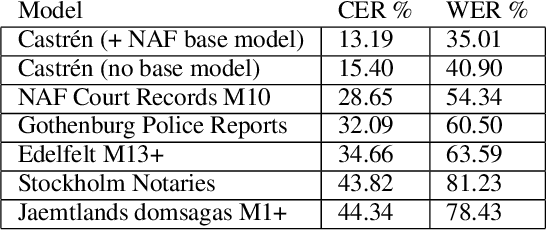
The study forms a technical report of various tasks that have been performed on the materials collected and published by Finnish ethnographer and linguist, Matthias Alexander Castr\'en (1813-1852). The Finno-Ugrian Society is publishing Castr\'en's manuscripts as new critical and digital editions, and at the same time different research groups have also paid attention to these materials. We discuss the workflows and technical infrastructure used, and consider how datasets that benefit different computational tasks could be created to further improve the usability of these materials, and also to aid the further processing of similar archived collections. We specifically focus on the parts of the collections that are processed in a way that improves their usability in more technical applications, complementing the earlier work on the cultural and linguistic aspects of these materials. Most of these datasets are openly available in Zenodo. The study points to specific areas where further research is needed, and provides benchmarks for text recognition tasks.
Detecting Depression in Thai Blog Posts: a Dataset and a Baseline
Nov 08, 2021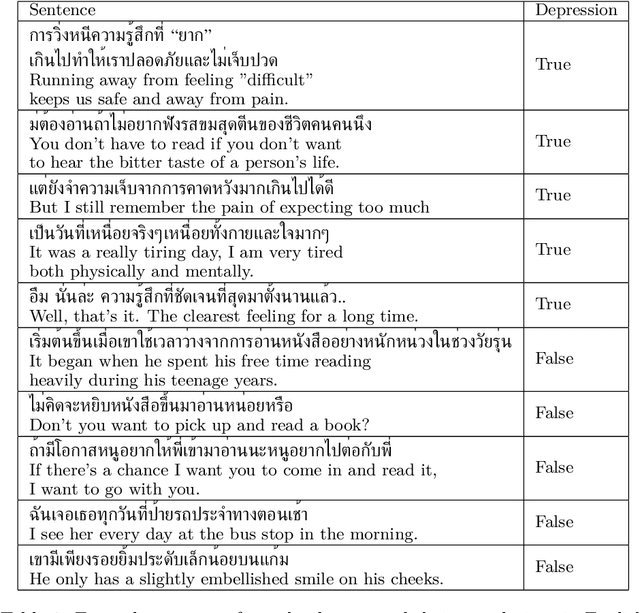
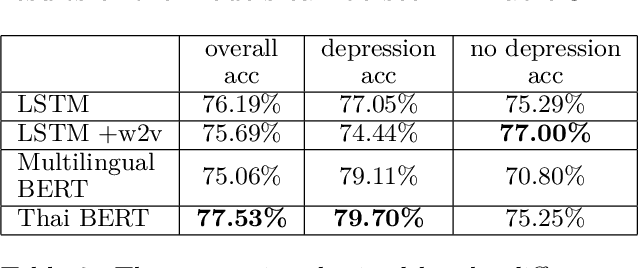
We present the first openly available corpus for detecting depression in Thai. Our corpus is compiled by expert verified cases of depression in several online blogs. We experiment with two different LSTM based models and two different BERT based models. We achieve a 77.53\% accuracy with a Thai BERT model in detecting depression. This establishes a good baseline for future researcher on the same corpus. Furthermore, we identify a need for Thai embeddings that have been trained on a more varied corpus than Wikipedia. Our corpus, code and trained models have been released openly on Zenodo.
Finnish Dialect Identification: The Effect of Audio and Text
Nov 06, 2021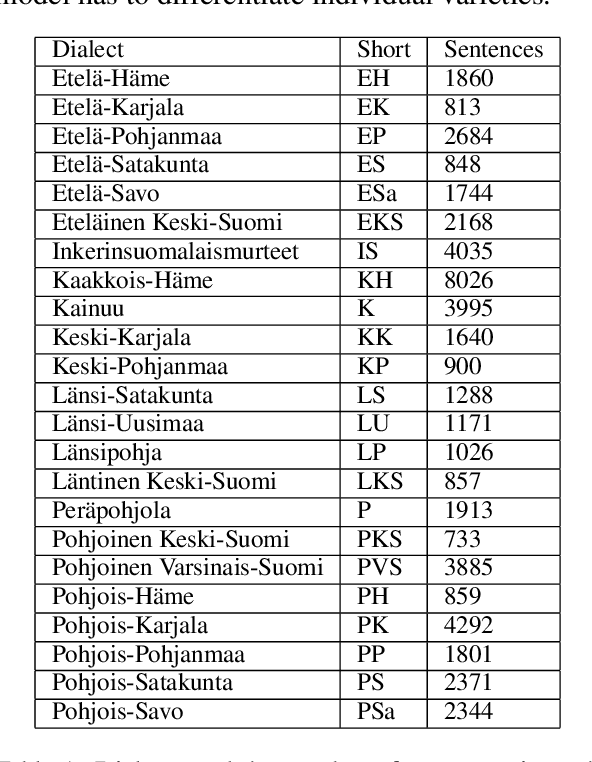
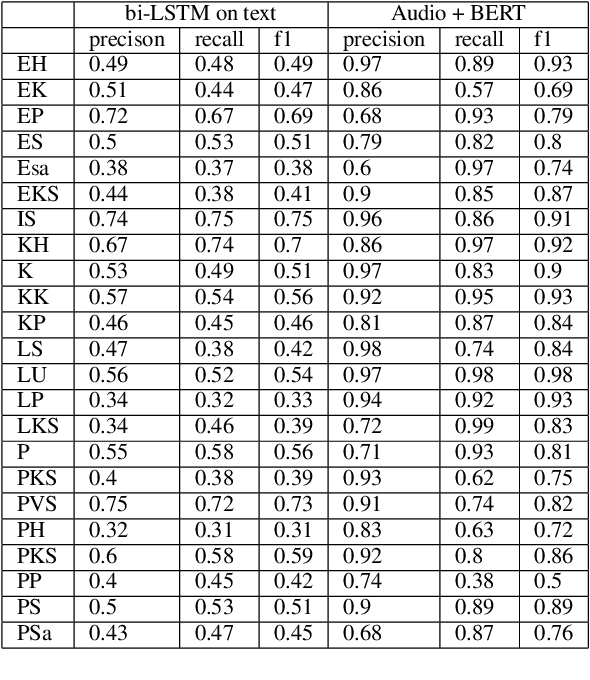
Finnish is a language with multiple dialects that not only differ from each other in terms of accent (pronunciation) but also in terms of morphological forms and lexical choice. We present the first approach to automatically detect the dialect of a speaker based on a dialect transcript and transcript with audio recording in a dataset consisting of 23 different dialects. Our results show that the best accuracy is received by combining both of the modalities, as text only reaches to an overall accuracy of 57\%, where as text and audio reach to 85\%. Our code, models and data have been released openly on Github and Zenodo.
Apurinã Universal Dependencies Treebank
Jun 07, 2021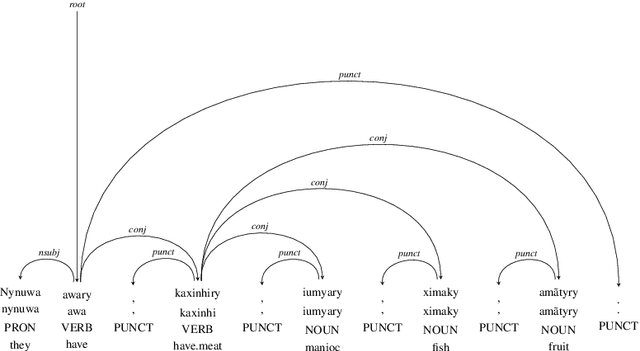

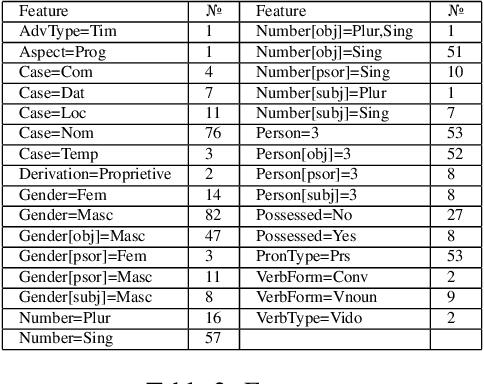
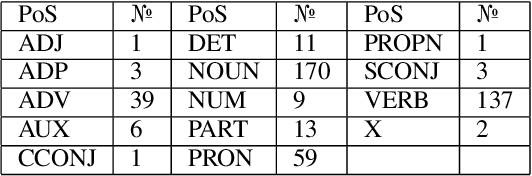
This paper presents and discusses the first Universal Dependencies treebank for the Apurin\~a language. The treebank contains 76 fully annotated sentences, applies 14 parts-of-speech, as well as seven augmented or new features - some of which are unique to Apurin\~a. The construction of the treebank has also served as an opportunity to develop finite-state description of the language and facilitate the transfer of open-source infrastructure possibilities to an endangered language of the Amazon. The source materials used in the initial treebank represent fieldwork practices where not all tokens of all sentences are equally annotated. For this reason, establishing regular annotation practices for the entire Apurin\~a treebank is an ongoing project.
Never guess what I heard Rumor Detection in Finnish News: a Dataset and a Baseline
Jun 07, 2021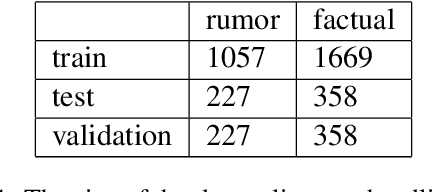

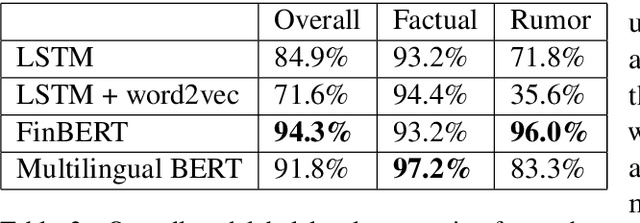
This study presents a new dataset on rumor detection in Finnish language news headlines. We have evaluated two different LSTM based models and two different BERT models, and have found very significant differences in the results. A fine-tuned FinBERT reaches the best overall accuracy of 94.3% and rumor label accuracy of 96.0% of the time. However, a model fine-tuned on Multilingual BERT reaches the best factual label accuracy of 97.2%. Our results suggest that the performance difference is due to a difference in the original training data. Furthermore, we find that a regular LSTM model works better than one trained with a pretrained word2vec model. These findings suggest that more work needs to be done for pretrained models in Finnish language as they have been trained on small and biased corpora.
Neural Morphology Dataset and Models for Multiple Languages, from the Large to the Endangered
May 26, 2021
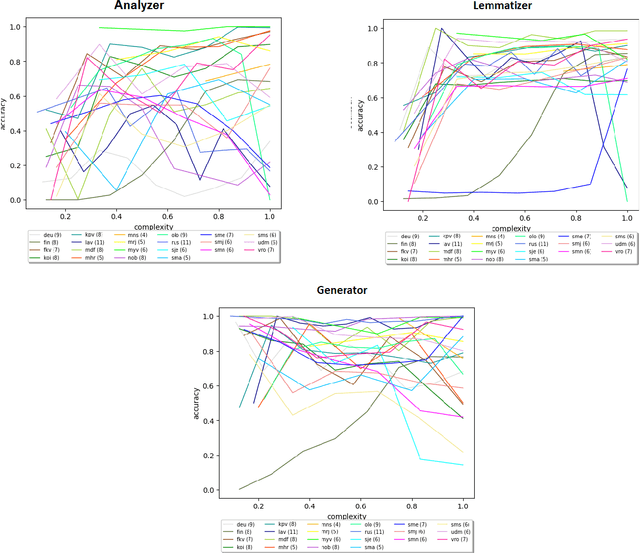


We train neural models for morphological analysis, generation and lemmatization for morphologically rich languages. We present a method for automatically extracting substantially large amount of training data from FSTs for 22 languages, out of which 17 are endangered. The neural models follow the same tagset as the FSTs in order to make it possible to use them as fallback systems together with the FSTs. The source code, models and datasets have been released on Zenodo.
Ve'rdd. Narrowing the Gap between Paper Dictionaries, Low-Resource NLP and Community Involvement
Dec 04, 2020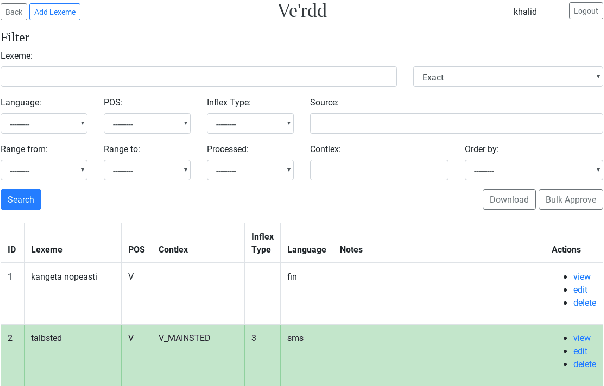
We present an open-source online dictionary editing system, Ve'rdd, that offers a chance to re-evaluate and edit grassroots dictionaries that have been exposed to multiple amateur editors. The idea is to incorporate community activities into a state-of-the-art finite-state language description of a seriously endangered minority language, Skolt Sami. Problems involve getting the community to take part in things above the pencil-and-paper level. At times, it seems that the native speakers and the dictionary oriented are lacking technical understanding to utilize the infrastructures which might make their work more meaningful in the future, i.e. multiple reuse of all of their input. Therefore, our system integrates with the existing tools and infrastructures for Uralic language masking the technical complexities behind a user-friendly UI.