 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAXOLOTL'24 Shared Task on Multilingual Explainable Semantic Change Modeling
Jul 04, 2024



This paper describes the organization and findings of AXOLOTL'24, the first multilingual explainable semantic change modeling shared task. We present new sense-annotated diachronic semantic change datasets for Finnish and Russian which were employed in the shared task, along with a surprise test-only German dataset borrowed from an existing source. The setup of AXOLOTL'24 is new to the semantic change modeling field, and involves subtasks of identifying unknown (novel) senses and providing dictionary-like definitions to these senses. The methods of the winning teams are described and compared, thus paving a path towards explainability in computational approaches to historical change of meaning.
Processing M.A. Castrén's Materials: Multilingual Typed and Handwritten Manuscripts
Dec 28, 2021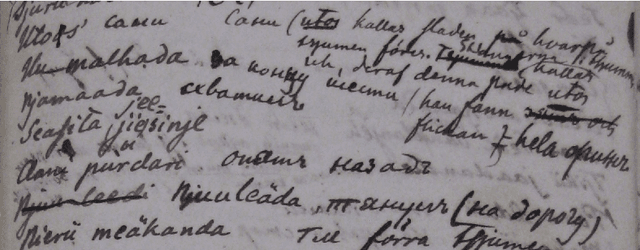
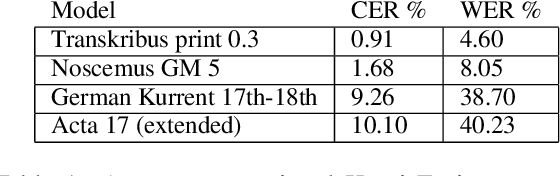
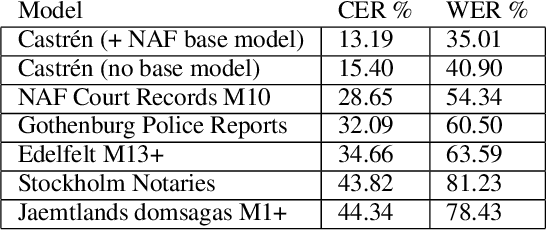
The study forms a technical report of various tasks that have been performed on the materials collected and published by Finnish ethnographer and linguist, Matthias Alexander Castr\'en (1813-1852). The Finno-Ugrian Society is publishing Castr\'en's manuscripts as new critical and digital editions, and at the same time different research groups have also paid attention to these materials. We discuss the workflows and technical infrastructure used, and consider how datasets that benefit different computational tasks could be created to further improve the usability of these materials, and also to aid the further processing of similar archived collections. We specifically focus on the parts of the collections that are processed in a way that improves their usability in more technical applications, complementing the earlier work on the cultural and linguistic aspects of these materials. Most of these datasets are openly available in Zenodo. The study points to specific areas where further research is needed, and provides benchmarks for text recognition tasks.
Detecting Depression in Thai Blog Posts: a Dataset and a Baseline
Nov 08, 2021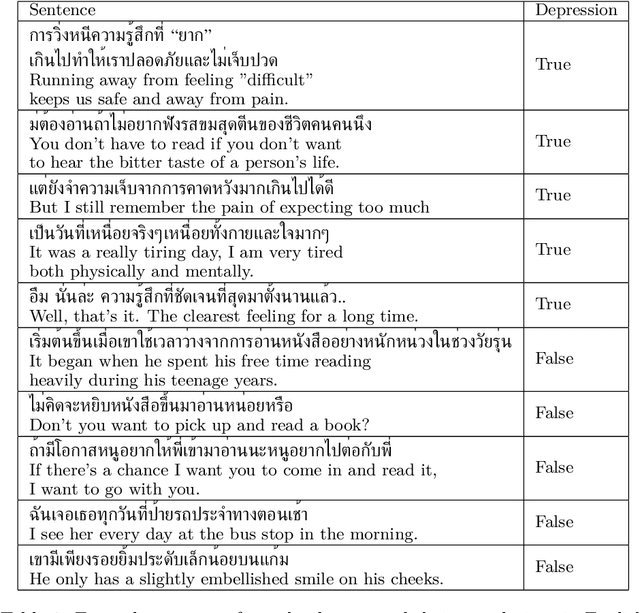
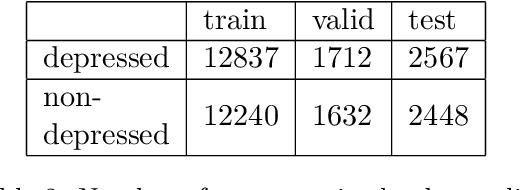
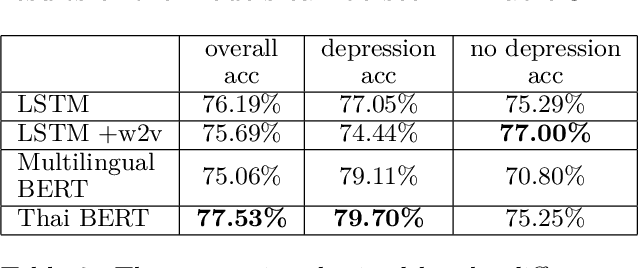
We present the first openly available corpus for detecting depression in Thai. Our corpus is compiled by expert verified cases of depression in several online blogs. We experiment with two different LSTM based models and two different BERT based models. We achieve a 77.53\% accuracy with a Thai BERT model in detecting depression. This establishes a good baseline for future researcher on the same corpus. Furthermore, we identify a need for Thai embeddings that have been trained on a more varied corpus than Wikipedia. Our corpus, code and trained models have been released openly on Zenodo.
Finnish Dialect Identification: The Effect of Audio and Text
Nov 06, 2021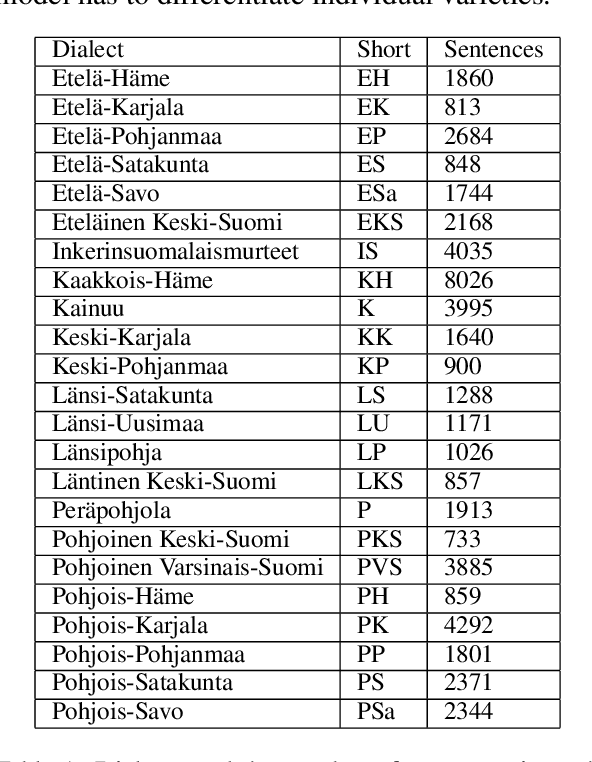
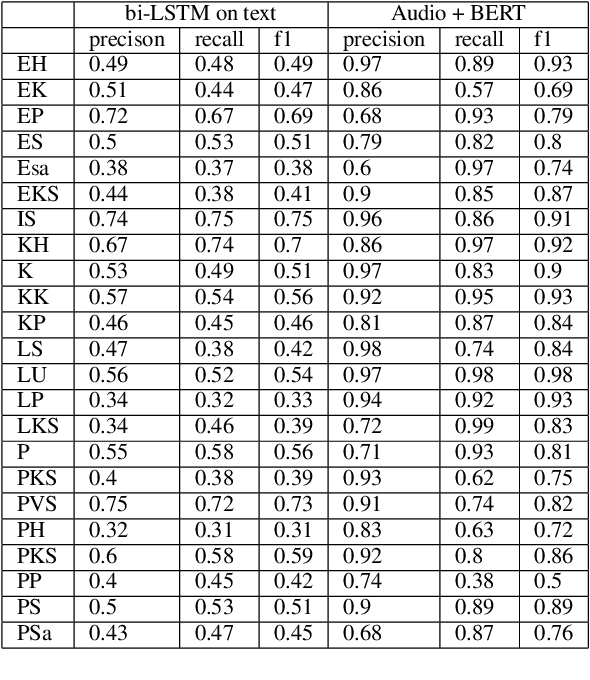
Finnish is a language with multiple dialects that not only differ from each other in terms of accent (pronunciation) but also in terms of morphological forms and lexical choice. We present the first approach to automatically detect the dialect of a speaker based on a dialect transcript and transcript with audio recording in a dataset consisting of 23 different dialects. Our results show that the best accuracy is received by combining both of the modalities, as text only reaches to an overall accuracy of 57\%, where as text and audio reach to 85\%. Our code, models and data have been released openly on Github and Zenodo.
How Cute is Pikachu? Gathering and Ranking Pokémon Properties from Data with Pokémon Word Embeddings
Aug 21, 2021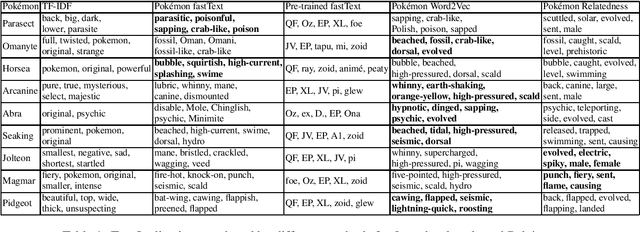
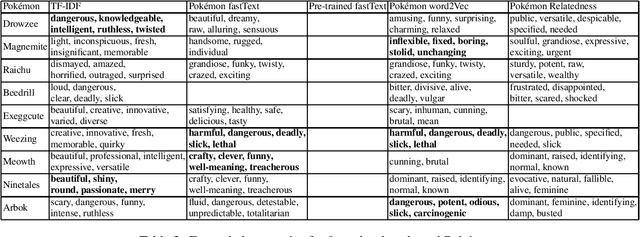
We present different methods for obtaining descriptive properties automatically for the 151 original Pok\'emon. We train several different word embeddings models on a crawled Pok\'emon corpus, and use them to rank automatically English adjectives based on how characteristic they are to a given Pok\'emon. Based on our experiments, it is better to train a model with domain specific data than to use a pretrained model. Word2Vec produces less noise in the results than fastText model. Furthermore, we expand the list of properties for each Pok\'emon automatically. However, none of the methods is spot on and there is a considerable amount of noise in the different semantic models. Our models have been released on Zenodo.
Lemmatization of Historical Old Literary Finnish Texts in Modern Orthography
Jul 07, 2021

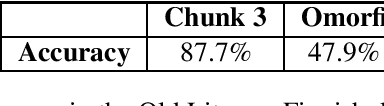
Texts written in Old Literary Finnish represent the first literary work ever written in Finnish starting from the 16th century. There have been several projects in Finland that have digitized old publications and made them available for research use. However, using modern NLP methods in such data poses great challenges. In this paper we propose an approach for simultaneously normalizing and lemmatizing Old Literary Finnish into modern spelling. Our best model reaches to 96.3\% accuracy in texts written by Agricola and 87.7\% accuracy in other contemporary out-of-domain text. Our method has been made freely available on Zenodo and Github.
Apurinã Universal Dependencies Treebank
Jun 07, 2021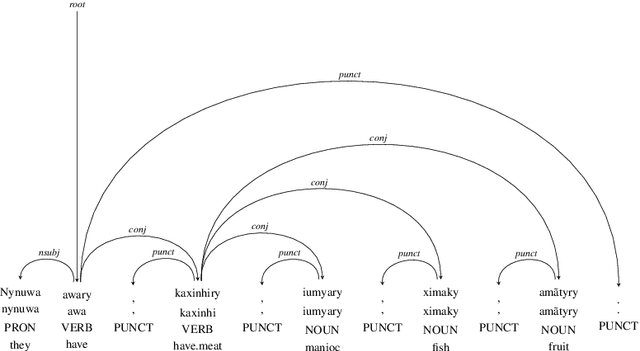

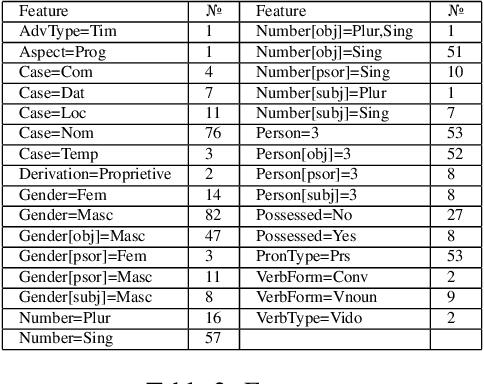
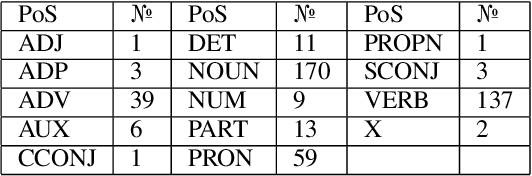
This paper presents and discusses the first Universal Dependencies treebank for the Apurin\~a language. The treebank contains 76 fully annotated sentences, applies 14 parts-of-speech, as well as seven augmented or new features - some of which are unique to Apurin\~a. The construction of the treebank has also served as an opportunity to develop finite-state description of the language and facilitate the transfer of open-source infrastructure possibilities to an endangered language of the Amazon. The source materials used in the initial treebank represent fieldwork practices where not all tokens of all sentences are equally annotated. For this reason, establishing regular annotation practices for the entire Apurin\~a treebank is an ongoing project.
Never guess what I heard Rumor Detection in Finnish News: a Dataset and a Baseline
Jun 07, 2021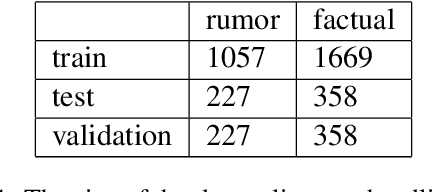

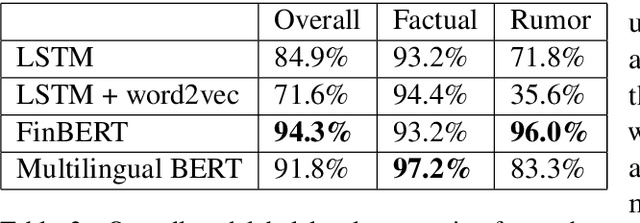
This study presents a new dataset on rumor detection in Finnish language news headlines. We have evaluated two different LSTM based models and two different BERT models, and have found very significant differences in the results. A fine-tuned FinBERT reaches the best overall accuracy of 94.3% and rumor label accuracy of 96.0% of the time. However, a model fine-tuned on Multilingual BERT reaches the best factual label accuracy of 97.2%. Our results suggest that the performance difference is due to a difference in the original training data. Furthermore, we find that a regular LSTM model works better than one trained with a pretrained word2vec model. These findings suggest that more work needs to be done for pretrained models in Finnish language as they have been trained on small and biased corpora.
Neural Morphology Dataset and Models for Multiple Languages, from the Large to the Endangered
May 26, 2021
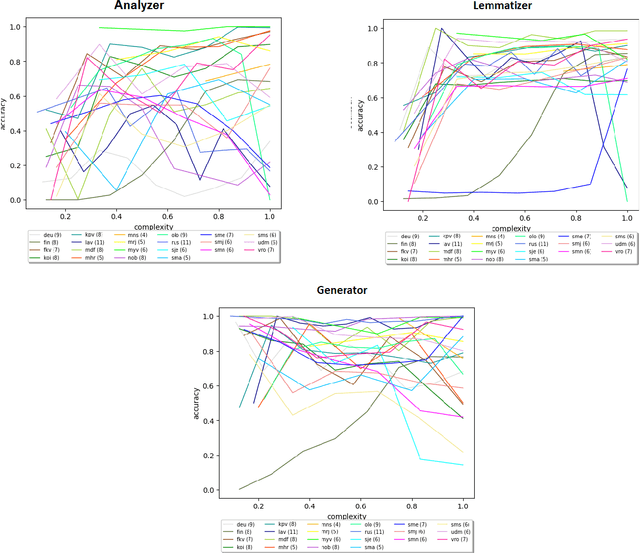


We train neural models for morphological analysis, generation and lemmatization for morphologically rich languages. We present a method for automatically extracting substantially large amount of training data from FSTs for 22 languages, out of which 17 are endangered. The neural models follow the same tagset as the FSTs in order to make it possible to use them as fallback systems together with the FSTs. The source code, models and datasets have been released on Zenodo.
Speech Recognition for Endangered and Extinct Samoyedic languages
Dec 09, 2020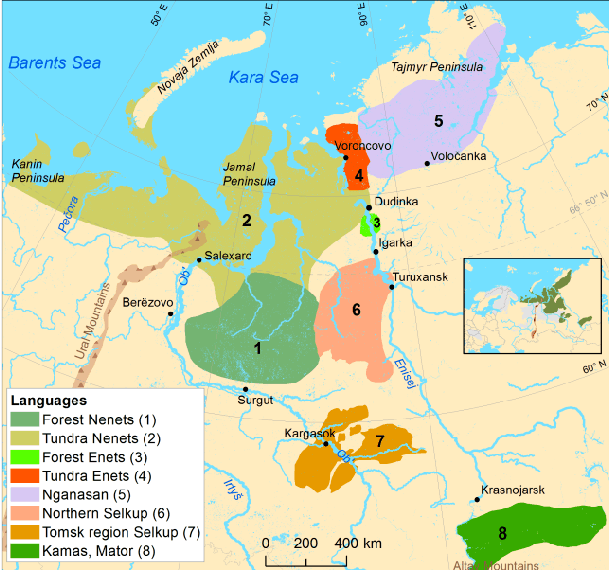
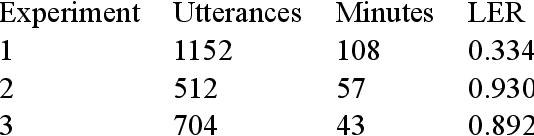

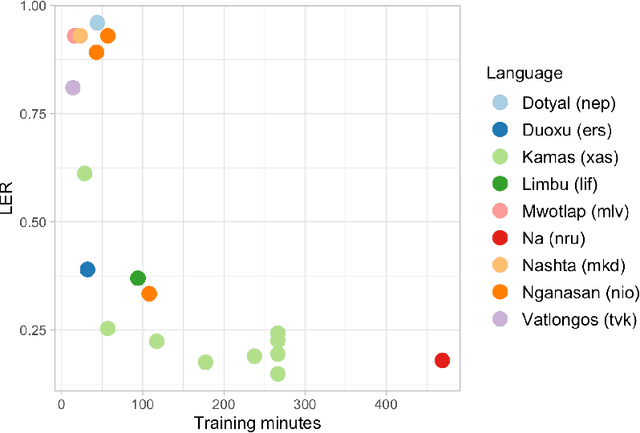
Our study presents a series of experiments on speech recognition with endangered and extinct Samoyedic languages, spoken in Northern and Southern Siberia. To best of our knowledge, this is the first time a functional ASR system is built for an extinct language. We achieve with Kamas language a Label Error Rate of 15\%, and conclude through careful error analysis that this quality is already very useful as a starting point for refined human transcriptions. Our results with related Nganasan language are more modest, with best model having the error rate of 33\%. We show, however, through experiments where Kamas training data is enlarged incrementally, that Nganasan results are in line with what is expected under low-resource circumstances of the language. Based on this, we provide recommendations for scenarios in which further language documentation or archive processing activities could benefit from modern ASR technology. All training data and processing scripts haven been published on Zenodo with clear licences to ensure further work in this important topic.