Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Cute is Pikachu? Gathering and Ranking Pokémon Properties from Data with Pokémon Word Embeddings
Paper and Code
Aug 21, 2021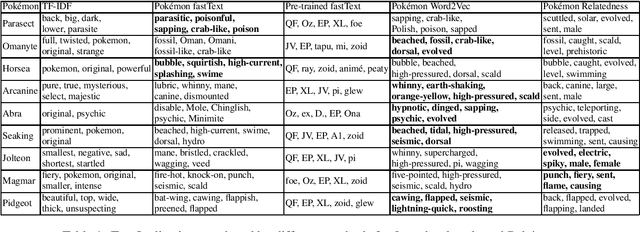
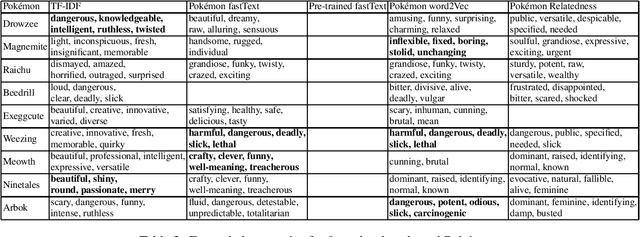
We present different methods for obtaining descriptive properties automatically for the 151 original Pok\'emon. We train several different word embeddings models on a crawled Pok\'emon corpus, and use them to rank automatically English adjectives based on how characteristic they are to a given Pok\'emon. Based on our experiments, it is better to train a model with domain specific data than to use a pretrained model. Word2Vec produces less noise in the results than fastText model. Furthermore, we expand the list of properties for each Pok\'emon automatically. However, none of the methods is spot on and there is a considerable amount of noise in the different semantic models. Our models have been released on Zenodo.
* English translation of H\"am\"al\"ainen, M., Alnajjar, K. \&
Partanen, N. (2021). Nettikorpuksen avulla tuotettuja sanavektorimalleja
Pok\'emonien ominaisuuksien kuvaamiseksi. In Saarikivi, T. \& Saarikivi, J.
(eds.) \textit{Turhan tiedon kirja -- Tutkimuksista pois j\"atettyj\"a
sivuja}
View paper on