 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluent Alignment with Disfluent Judges: Post-training for Lower-resource Languages
Dec 09, 2025



We propose a post-training method for lower-resource languages that preserves fluency of language models even when aligned by disfluent reward models. Preference-optimization is now a well-researched topic, but previous work has mostly addressed models for English and Chinese. Lower-resource languages lack both datasets written by native speakers and language models capable of generating fluent synthetic data. Thus, in this work, we focus on developing a fluent preference-aligned language model without any instruction-tuning data in the target language. Our approach uses an on-policy training method, which we compare with two common approaches: supervised finetuning on machine-translated data and multilingual finetuning. We conduct a case study on Norwegian Bokmål and evaluate fluency through native-speaker assessments. The results show that the on-policy aspect is crucial and outperforms the alternatives without relying on any hard-to-obtain data.
NorEval: A Norwegian Language Understanding and Generation Evaluation Benchmark
Apr 10, 2025This paper introduces NorEval, a new and comprehensive evaluation suite for large-scale standardized benchmarking of Norwegian generative language models (LMs). NorEval consists of 24 high-quality human-created datasets -- of which five are created from scratch. In contrast to existing benchmarks for Norwegian, NorEval covers a broad spectrum of task categories targeting Norwegian language understanding and generation, establishes human baselines, and focuses on both of the official written standards of the Norwegian language: Bokm{\aa}l and Nynorsk. All our datasets and a collection of over 100 human-written prompts are integrated into LM Evaluation Harness, ensuring flexible and reproducible evaluation. We describe the NorEval design and present the results of benchmarking 19 open-source pre-trained and instruction-tuned LMs for Norwegian in various scenarios. Our benchmark, evaluation framework, and annotation materials are publicly available.
The Impact of Copyrighted Material on Large Language Models: A Norwegian Perspective
Dec 12, 2024



The use of copyrighted materials in training generative language models raises critical legal and ethical questions. This paper presents a framework for and the results of empirically assessing the impact of copyrighted materials on the performance of large language models (LLMs) for Norwegian. We found that both books and newspapers contribute positively when the models are evaluated on a diverse set of Norwegian benchmarks, while fiction works possibly lead to decreased performance. Our experiments could inform the creation of a compensation scheme for authors whose works contribute to AI development.
Small Languages, Big Models: A Study of Continual Training on Languages of Norway
Dec 09, 2024



Training large language models requires vast amounts of data, posing a challenge for less widely spoken languages like Norwegian and even more so for truly low-resource languages like S\'ami. To address this issue, we present a novel three-stage continual training approach. We also experiment with combining causal and masked language modeling to get more flexible models. Based on our findings, we train, evaluate, and openly release a new large generative language model for Norwegian Bokm\r{a}l, Nynorsk, and Northern S\'ami with 11.4 billion parameters: NorMistral-11B.
AXOLOTL'24 Shared Task on Multilingual Explainable Semantic Change Modeling
Jul 04, 2024



This paper describes the organization and findings of AXOLOTL'24, the first multilingual explainable semantic change modeling shared task. We present new sense-annotated diachronic semantic change datasets for Finnish and Russian which were employed in the shared task, along with a surprise test-only German dataset borrowed from an existing source. The setup of AXOLOTL'24 is new to the semantic change modeling field, and involves subtasks of identifying unknown (novel) senses and providing dictionary-like definitions to these senses. The methods of the winning teams are described and compared, thus paving a path towards explainability in computational approaches to historical change of meaning.
Definition generation for lexical semantic change detection
Jun 20, 2024



We use contextualized word definitions generated by large language models as semantic representations in the task of diachronic lexical semantic change detection (LSCD). In short, generated definitions are used as `senses', and the change score of a target word is retrieved by comparing their distributions in two time periods under comparison. On the material of five datasets and three languages, we show that generated definitions are indeed specific and general enough to convey a signal sufficient to rank sets of words by the degree of their semantic change over time. Our approach is on par with or outperforms prior non-supervised sense-based LSCD methods. At the same time, it preserves interpretability and allows to inspect the reasons behind a specific shift in terms of discrete definitions-as-senses. This is another step in the direction of explainable semantic change modeling.
Enriching Word Usage Graphs with Cluster Definitions
Mar 26, 2024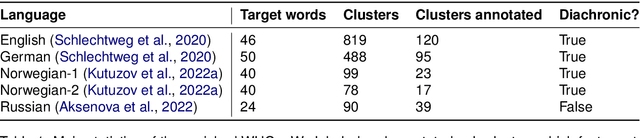
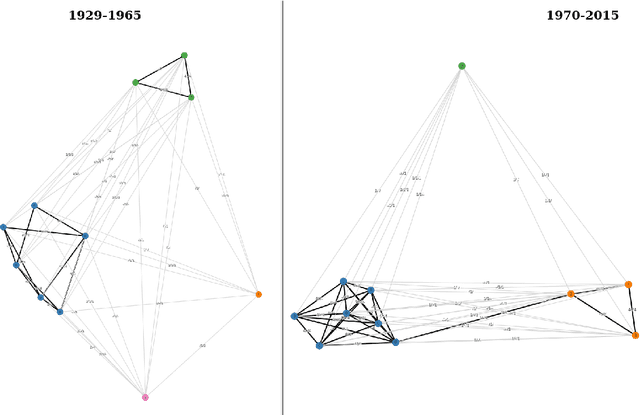


We present a dataset of word usage graphs (WUGs), where the existing WUGs for multiple languages are enriched with cluster labels functioning as sense definitions. They are generated from scratch by fine-tuned encoder-decoder language models. The conducted human evaluation has shown that these definitions match the existing clusters in WUGs better than the definitions chosen from WordNet by two baseline systems. At the same time, the method is straightforward to use and easy to extend to new languages. The resulting enriched datasets can be extremely helpful for moving on to explainable semantic change modeling.
A New Massive Multilingual Dataset for High-Performance Language Technologies
Mar 20, 2024We present the HPLT (High Performance Language Technologies) language resources, a new massive multilingual dataset including both monolingual and bilingual corpora extracted from CommonCrawl and previously unused web crawls from the Internet Archive. We describe our methods for data acquisition, management and processing of large corpora, which rely on open-source software tools and high-performance computing. Our monolingual collection focuses on low- to medium-resourced languages and covers 75 languages and a total of ~5.6 trillion word tokens de-duplicated on the document level. Our English-centric parallel corpus is derived from its monolingual counterpart and covers 18 language pairs and more than 96 million aligned sentence pairs with roughly 1.4 billion English tokens. The HPLT language resources are one of the largest open text corpora ever released, providing a great resource for language modeling and machine translation training. We publicly release the corpora, the software, and the tools used in this work.
Interpretable Word Sense Representations via Definition Generation: The Case of Semantic Change Analysis
May 19, 2023



We propose using automatically generated natural language definitions of contextualised word usages as interpretable word and word sense representations. Given a collection of usage examples for a target word, and the corresponding data-driven usage clusters (i.e., word senses), a definition is generated for each usage with a specialised Flan-T5 language model, and the most prototypical definition in a usage cluster is chosen as the sense label. We demonstrate how the resulting sense labels can make existing approaches to semantic change analysis more interpretable, and how they can allow users -- historical linguists, lexicographers, or social scientists -- to explore and intuitively explain diachronic trajectories of word meaning. Semantic change analysis is only one of many possible applications of the `definitions as representations' paradigm. Beyond being human-readable, contextualised definitions also outperform token or usage sentence embeddings in word-in-context semantic similarity judgements, making them a new promising type of lexical representation for NLP.
NorBench -- A Benchmark for Norwegian Language Models
May 06, 2023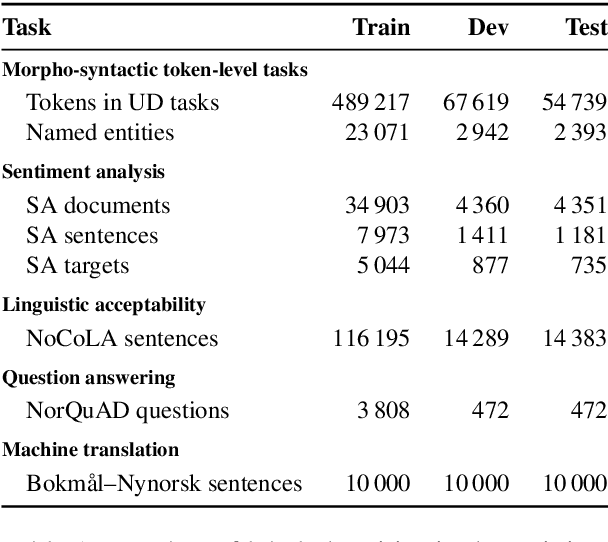


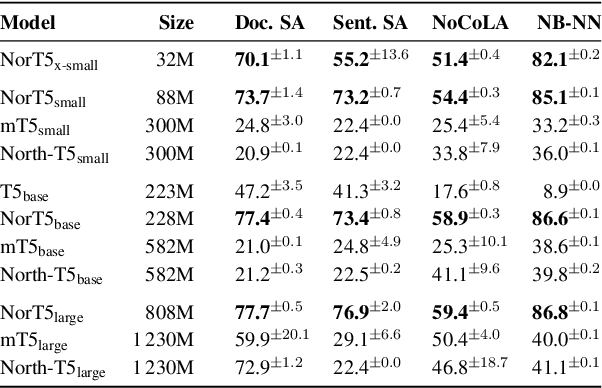
We present NorBench: a streamlined suite of NLP tasks and probes for evaluating Norwegian language models (LMs) on standardized data splits and evaluation metrics. We also introduce a range of new Norwegian language models (both encoder and encoder-decoder based). Finally, we compare and analyze their performance, along with other existing LMs, across the different benchmark tests of NorBench.