 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Copyrighted Material on Large Language Models: A Norwegian Perspective
Dec 12, 2024



The use of copyrighted materials in training generative language models raises critical legal and ethical questions. This paper presents a framework for and the results of empirically assessing the impact of copyrighted materials on the performance of large language models (LLMs) for Norwegian. We found that both books and newspapers contribute positively when the models are evaluated on a diverse set of Norwegian benchmarks, while fiction works possibly lead to decreased performance. Our experiments could inform the creation of a compensation scheme for authors whose works contribute to AI development.
Whispering in Norwegian: Navigating Orthographic and Dialectic Challenges
Feb 02, 2024



This article introduces NB-Whisper, an adaptation of OpenAI's Whisper, specifically fine-tuned for Norwegian language Automatic Speech Recognition (ASR). We highlight its key contributions and summarise the results achieved in converting spoken Norwegian into written forms and translating other languages into Norwegian. We show that we are able to improve the Norwegian Bokm{\aa}l transcription by OpenAI Whisper Large-v3 from a WER of 10.4 to 6.6 on the Fleurs Dataset and from 6.8 to 2.2 on the NST dataset.
Boosting Norwegian Automatic Speech Recognition
Jul 04, 2023In this paper, we present several baselines for automatic speech recognition (ASR) models for the two official written languages in Norway: Bokm{\aa}l and Nynorsk. We compare the performance of models of varying sizes and pre-training approaches on multiple Norwegian speech datasets. Additionally, we measure the performance of these models against previous state-of-the-art ASR models, as well as on out-of-domain datasets. We improve the state of the art on the Norwegian Parliamentary Speech Corpus (NPSC) from a word error rate (WER) of 17.10\% to 7.60\%, with models achieving 5.81\% for Bokm{\aa}l and 11.54\% for Nynorsk. We also discuss the challenges and potential solutions for further improving ASR models for Norwegian.
* 10 pages, 10 figures. Published as Proceedings NoDaLiDa 2023, pages 555--564
Operationalizing a National Digital Library: The Case for a Norwegian Transformer Model
Apr 19, 2021
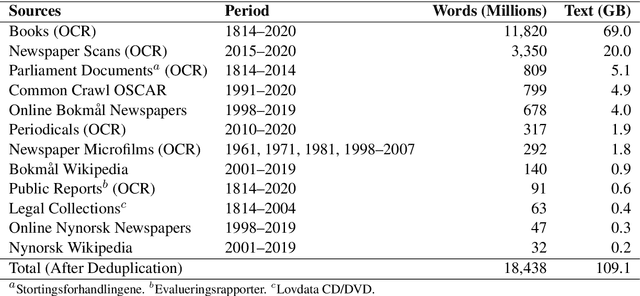
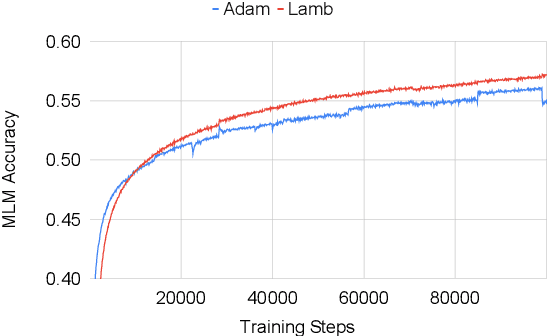
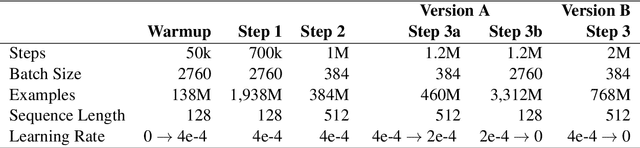
In this work, we show the process of building a large-scale training set from digital and digitized collections at a national library. The resulting Bidirectional Encoder Representations from Transformers (BERT)-based language model for Norwegian outperforms multilingual BERT (mBERT) models in several token and sequence classification tasks for both Norwegian Bokm{\aa}l and Norwegian Nynorsk. Our model also improves the mBERT performance for other languages present in the corpus such as English, Swedish, and Danish. For languages not included in the corpus, the weights degrade moderately while keeping strong multilingual properties. Therefore, we show that building high-quality models within a memory institution using somewhat noisy optical character recognition (OCR) content is feasible, and we hope to pave the way for other memory institutions to follow.