 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalizing a National Digital Library: The Case for a Norwegian Transformer Model
Paper and Code
Apr 19, 2021
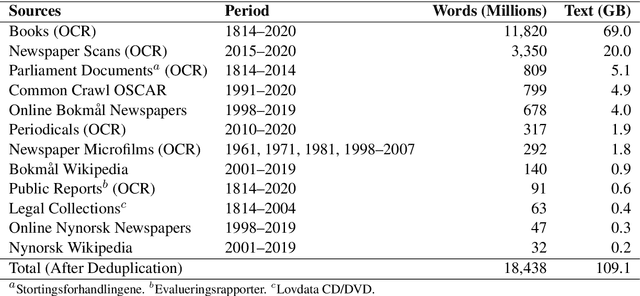
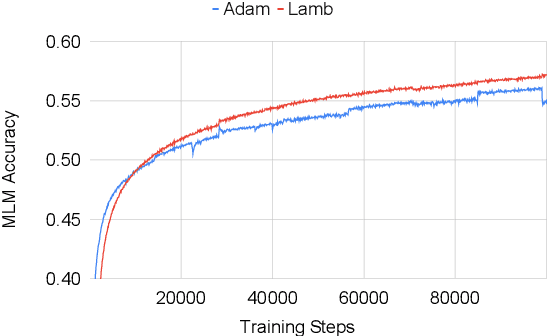
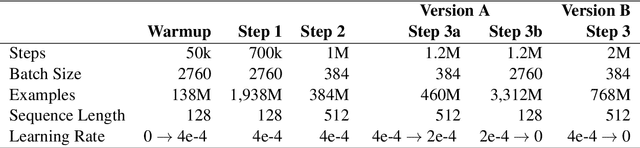
In this work, we show the process of building a large-scale training set from digital and digitized collections at a national library. The resulting Bidirectional Encoder Representations from Transformers (BERT)-based language model for Norwegian outperforms multilingual BERT (mBERT) models in several token and sequence classification tasks for both Norwegian Bokm{\aa}l and Norwegian Nynorsk. Our model also improves the mBERT performance for other languages present in the corpus such as English, Swedish, and Danish. For languages not included in the corpus, the weights degrade moderately while keeping strong multilingual properties. Therefore, we show that building high-quality models within a memory institution using somewhat noisy optical character recognition (OCR) content is feasible, and we hope to pave the way for other memory institutions to follow.