 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Copyrighted Material on Large Language Models: A Norwegian Perspective
Dec 12, 2024



The use of copyrighted materials in training generative language models raises critical legal and ethical questions. This paper presents a framework for and the results of empirically assessing the impact of copyrighted materials on the performance of large language models (LLMs) for Norwegian. We found that both books and newspapers contribute positively when the models are evaluated on a diverse set of Norwegian benchmarks, while fiction works possibly lead to decreased performance. Our experiments could inform the creation of a compensation scheme for authors whose works contribute to AI development.
Whispering in Norwegian: Navigating Orthographic and Dialectic Challenges
Feb 02, 2024



This article introduces NB-Whisper, an adaptation of OpenAI's Whisper, specifically fine-tuned for Norwegian language Automatic Speech Recognition (ASR). We highlight its key contributions and summarise the results achieved in converting spoken Norwegian into written forms and translating other languages into Norwegian. We show that we are able to improve the Norwegian Bokm{\aa}l transcription by OpenAI Whisper Large-v3 from a WER of 10.4 to 6.6 on the Fleurs Dataset and from 6.8 to 2.2 on the NST dataset.
Boosting Norwegian Automatic Speech Recognition
Jul 04, 2023In this paper, we present several baselines for automatic speech recognition (ASR) models for the two official written languages in Norway: Bokm{\aa}l and Nynorsk. We compare the performance of models of varying sizes and pre-training approaches on multiple Norwegian speech datasets. Additionally, we measure the performance of these models against previous state-of-the-art ASR models, as well as on out-of-domain datasets. We improve the state of the art on the Norwegian Parliamentary Speech Corpus (NPSC) from a word error rate (WER) of 17.10\% to 7.60\%, with models achieving 5.81\% for Bokm{\aa}l and 11.54\% for Nynorsk. We also discuss the challenges and potential solutions for further improving ASR models for Norwegian.
* 10 pages, 10 figures. Published as Proceedings NoDaLiDa 2023, pages 555--564
ALBERTI, a Multilingual Domain Specific Language Model for Poetry Analysis
Jul 03, 2023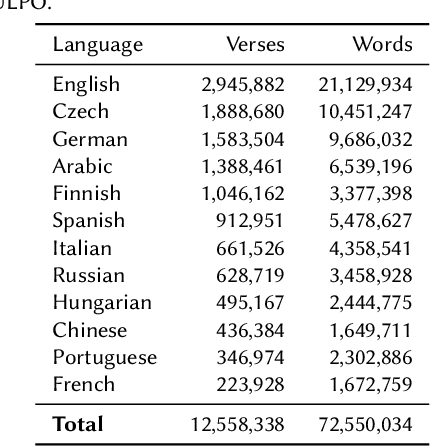

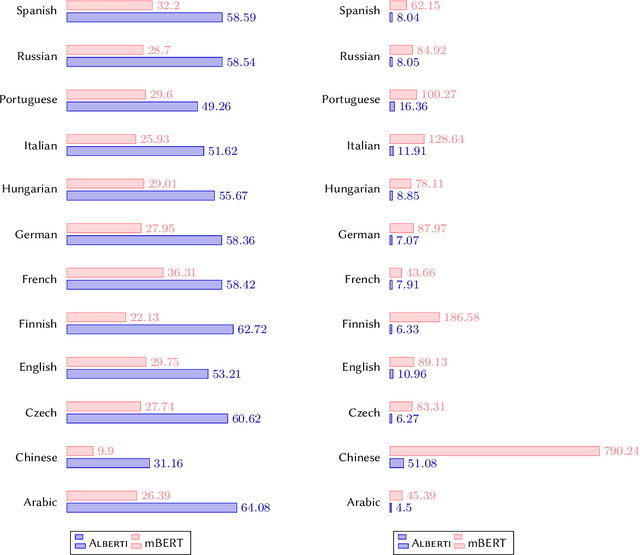
The computational analysis of poetry is limited by the scarcity of tools to automatically analyze and scan poems. In a multilingual settings, the problem is exacerbated as scansion and rhyme systems only exist for individual languages, making comparative studies very challenging and time consuming. In this work, we present \textsc{Alberti}, the first multilingual pre-trained large language model for poetry. Through domain-specific pre-training (DSP), we further trained multilingual BERT on a corpus of over 12 million verses from 12 languages. We evaluated its performance on two structural poetry tasks: Spanish stanza type classification, and metrical pattern prediction for Spanish, English and German. In both cases, \textsc{Alberti} outperforms multilingual BERT and other transformers-based models of similar sizes, and even achieves state-of-the-art results for German when compared to rule-based systems, demonstrating the feasibility and effectiveness of DSP in the poetry domain.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023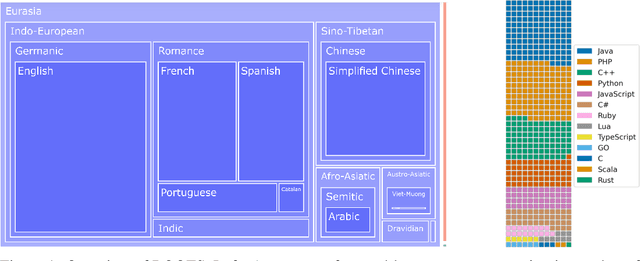

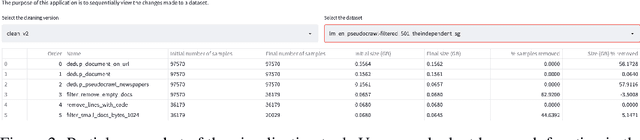

As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
BERTIN: Efficient Pre-Training of a Spanish Language Model using Perplexity Sampling
Jul 14, 2022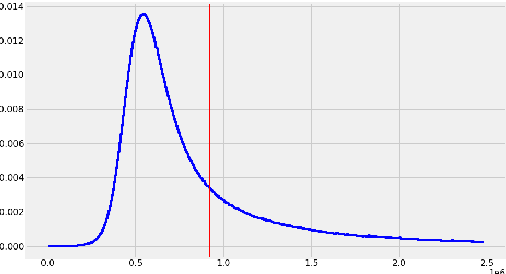
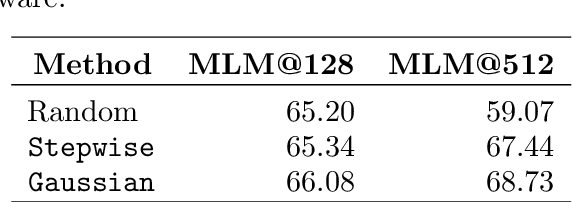
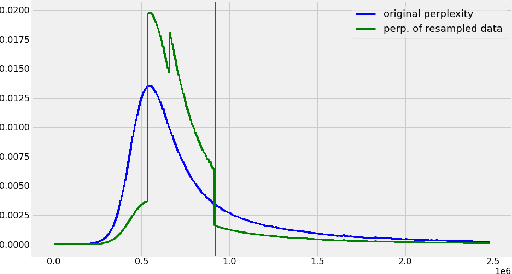
The pre-training of large language models usually requires massive amounts of resources, both in terms of computation and data. Frequently used web sources such as Common Crawl might contain enough noise to make this pre-training sub-optimal. In this work, we experiment with different sampling methods from the Spanish version of mC4, and present a novel data-centric technique which we name $\textit{perplexity sampling}$ that enables the pre-training of language models in roughly half the amount of steps and using one fifth of the data. The resulting models are comparable to the current state-of-the-art, and even achieve better results for certain tasks. Our work is proof of the versatility of Transformers, and paves the way for small teams to train their models on a limited budget. Our models are available at this $\href{https://huggingface.co/bertin-project}{URL}$.
* Published at Procesamiento del Lenguaje Natural
Entities, Dates, and Languages: Zero-Shot on Historical Texts with T0
Apr 11, 2022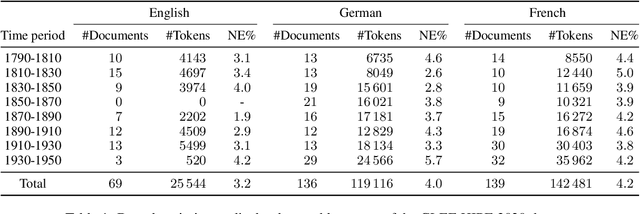



In this work, we explore whether the recently demonstrated zero-shot abilities of the T0 model extend to Named Entity Recognition for out-of-distribution languages and time periods. Using a historical newspaper corpus in 3 languages as test-bed, we use prompts to extract possible named entities. Our results show that a naive approach for prompt-based zero-shot multilingual Named Entity Recognition is error-prone, but highlights the potential of such an approach for historical languages lacking labeled datasets. Moreover, we also find that T0-like models can be probed to predict the publication date and language of a document, which could be very relevant for the study of historical texts.
The futility of STILTs for the classification of lexical borrowings in Spanish
Sep 17, 2021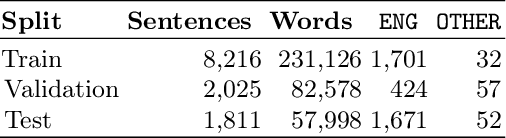
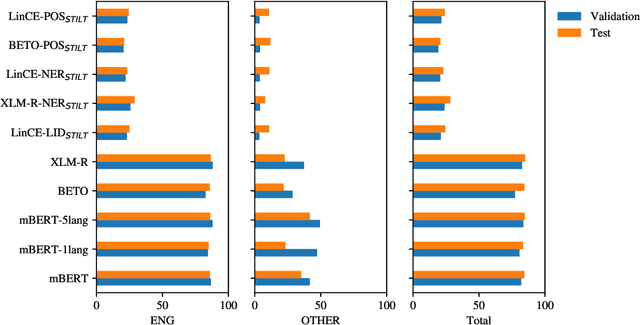
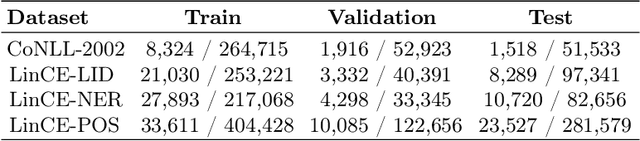
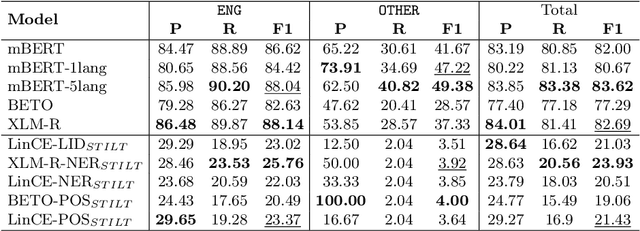
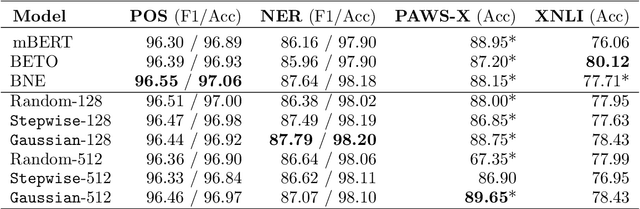
The first edition of the IberLEF 2021 shared task on automatic detection of borrowings (ADoBo) focused on detecting lexical borrowings that appeared in the Spanish press and that have recently been imported into the Spanish language. In this work, we tested supplementary training on intermediate labeled-data tasks (STILTs) from part of speech (POS), named entity recognition (NER), code-switching, and language identification approaches to the classification of borrowings at the token level using existing pre-trained transformer-based language models. Our extensive experimental results suggest that STILTs do not provide any improvement over direct fine-tuning of multilingual models. However, multilingual models trained on small subsets of languages perform reasonably better than multilingual BERT but not as good as multilingual RoBERTa for the given dataset.
Operationalizing a National Digital Library: The Case for a Norwegian Transformer Model
Apr 19, 2021
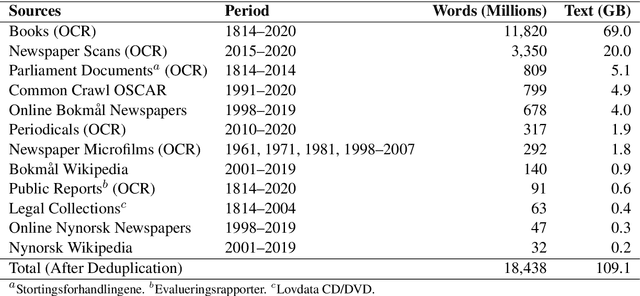
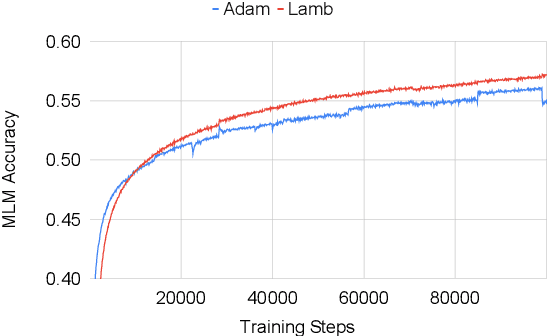
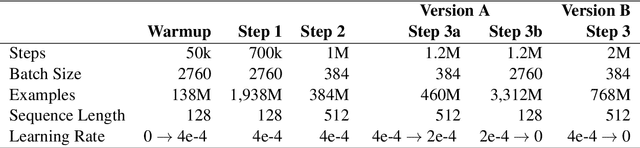
In this work, we show the process of building a large-scale training set from digital and digitized collections at a national library. The resulting Bidirectional Encoder Representations from Transformers (BERT)-based language model for Norwegian outperforms multilingual BERT (mBERT) models in several token and sequence classification tasks for both Norwegian Bokm{\aa}l and Norwegian Nynorsk. Our model also improves the mBERT performance for other languages present in the corpus such as English, Swedish, and Danish. For languages not included in the corpus, the weights degrade moderately while keeping strong multilingual properties. Therefore, we show that building high-quality models within a memory institution using somewhat noisy optical character recognition (OCR) content is feasible, and we hope to pave the way for other memory institutions to follow.