 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe futility of STILTs for the classification of lexical borrowings in Spanish
Paper and Code
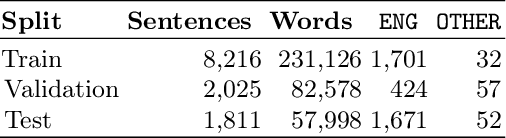
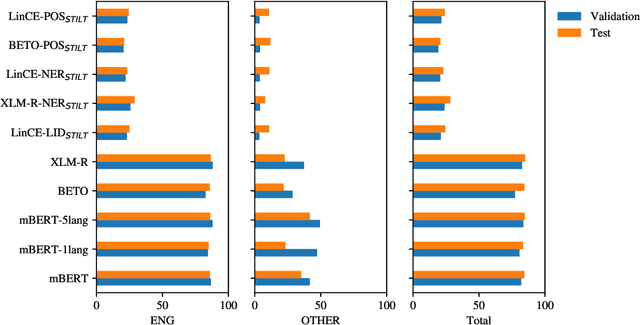
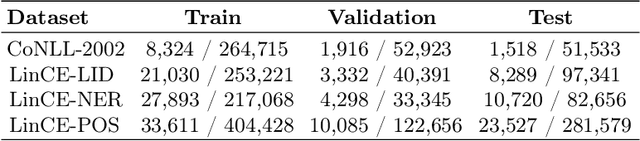
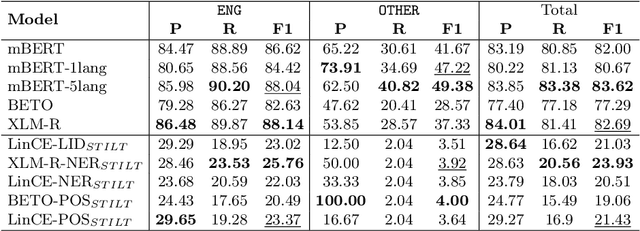
The first edition of the IberLEF 2021 shared task on automatic detection of borrowings (ADoBo) focused on detecting lexical borrowings that appeared in the Spanish press and that have recently been imported into the Spanish language. In this work, we tested supplementary training on intermediate labeled-data tasks (STILTs) from part of speech (POS), named entity recognition (NER), code-switching, and language identification approaches to the classification of borrowings at the token level using existing pre-trained transformer-based language models. Our extensive experimental results suggest that STILTs do not provide any improvement over direct fine-tuning of multilingual models. However, multilingual models trained on small subsets of languages perform reasonably better than multilingual BERT but not as good as multilingual RoBERTa for the given dataset.