 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Entities, Dates, and Languages: Zero-Shot on Historical Texts with T0
Apr 11, 2022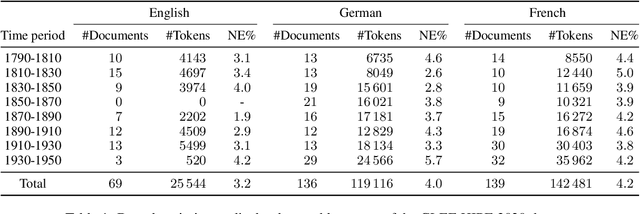



In this work, we explore whether the recently demonstrated zero-shot abilities of the T0 model extend to Named Entity Recognition for out-of-distribution languages and time periods. Using a historical newspaper corpus in 3 languages as test-bed, we use prompts to extract possible named entities. Our results show that a naive approach for prompt-based zero-shot multilingual Named Entity Recognition is error-prone, but highlights the potential of such an approach for historical languages lacking labeled datasets. Moreover, we also find that T0-like models can be probed to predict the publication date and language of a document, which could be very relevant for the study of historical texts.
On the Feasibility of Automated Detection of Allusive Text Reuse
May 08, 2019
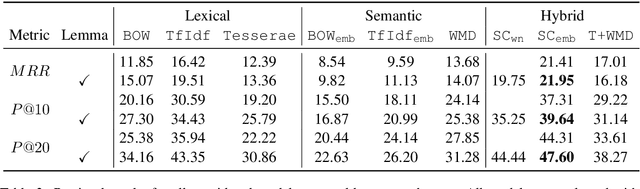
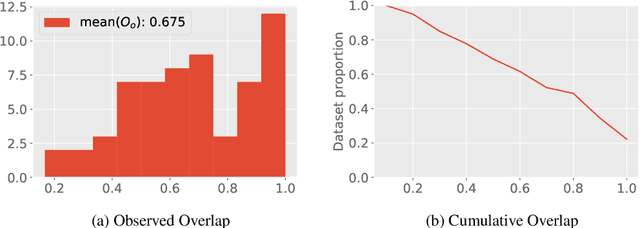
The detection of allusive text reuse is particularly challenging due to the sparse evidence on which allusive references rely---commonly based on none or very few shared words. Arguably, lexical semantics can be resorted to since uncovering semantic relations between words has the potential to increase the support underlying the allusion and alleviate the lexical sparsity. A further obstacle is the lack of evaluation benchmark corpora, largely due to the highly interpretative character of the annotation process. In the present paper, we aim to elucidate the feasibility of automated allusion detection. We approach the matter from an Information Retrieval perspective in which referencing texts act as queries and referenced texts as relevant documents to be retrieved, and estimate the difficulty of benchmark corpus compilation by a novel inter-annotator agreement study on query segmentation. Furthermore, we investigate to what extent the integration of lexical semantic information derived from distributional models and ontologies can aid retrieving cases of allusive reuse. The results show that (i) despite low agreement scores, using manual queries considerably improves retrieval performance with respect to a windowing approach, and that (ii) retrieval performance can be moderately boosted with distributional semantics.
Improving Lemmatization of Non-Standard Languages with Joint Learning
Mar 16, 2019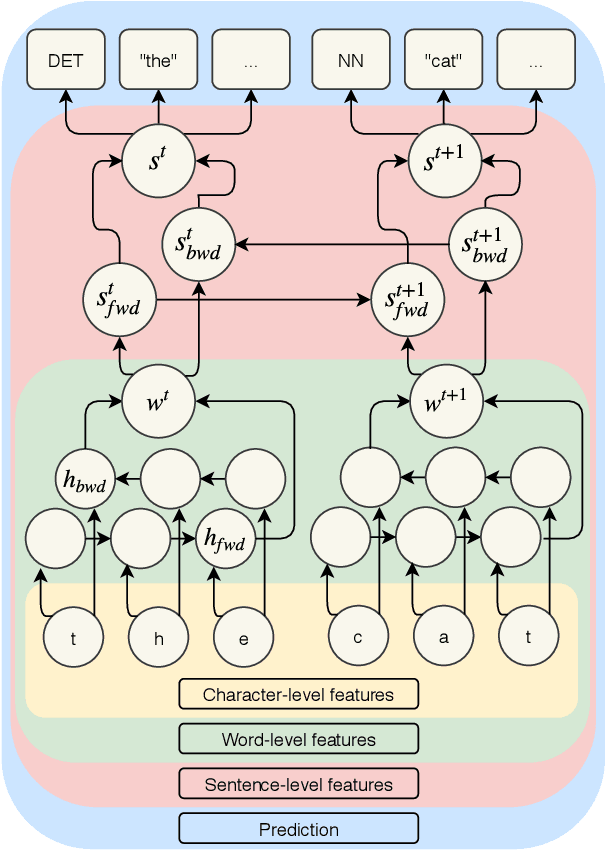
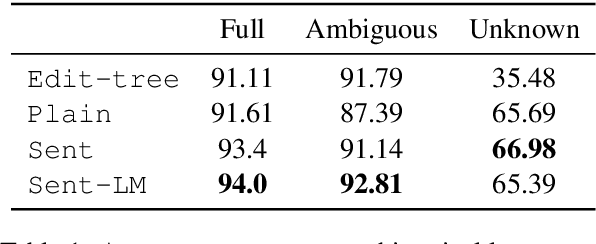
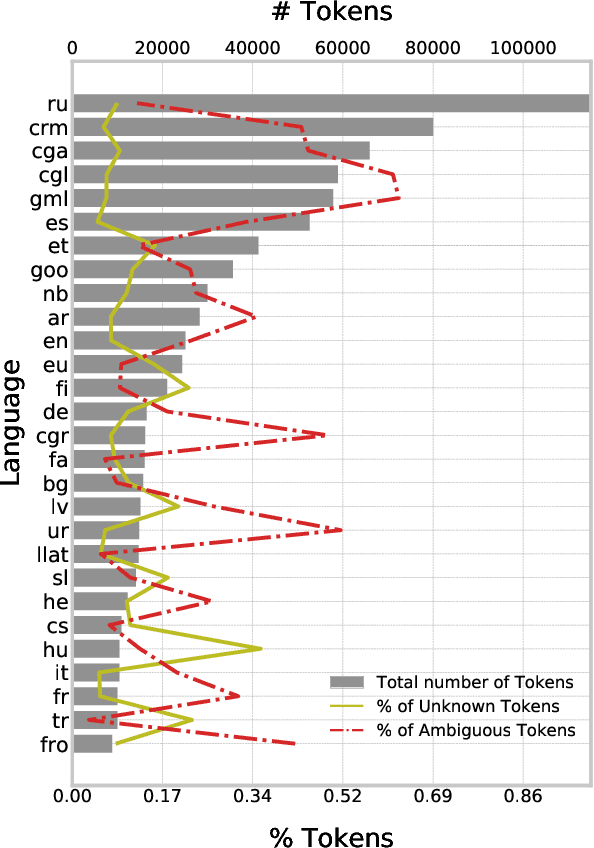

Lemmatization of standard languages is concerned with (i) abstracting over morphological differences and (ii) resolving token-lemma ambiguities of inflected words in order to map them to a dictionary headword. In the present paper we aim to improve lemmatization performance on a set of non-standard historical languages in which the difficulty is increased by an additional aspect (iii): spelling variation due to lacking orthographic standards. We approach lemmatization as a string-transduction task with an encoder-decoder architecture which we enrich with sentence context information using a hierarchical sentence encoder. We show significant improvements over the state-of-the-art when training the sentence encoder jointly for lemmatization and language modeling. Crucially, our architecture does not require POS or morphological annotations, which are not always available for historical corpora. Additionally, we also test the proposed model on a set of typologically diverse standard languages showing results on par or better than a model without enhanced sentence representations and previous state-of-the-art systems. Finally, to encourage future work on processing of non-standard varieties, we release the dataset of non-standard languages underlying the present study, based on openly accessible sources.
Style Obfuscation by Invariance
May 18, 2018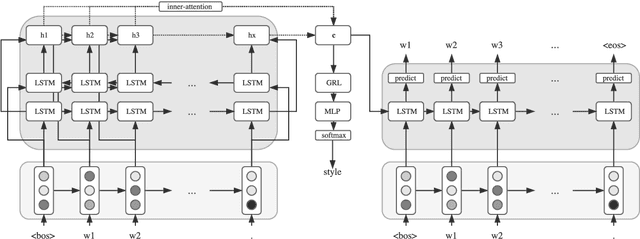
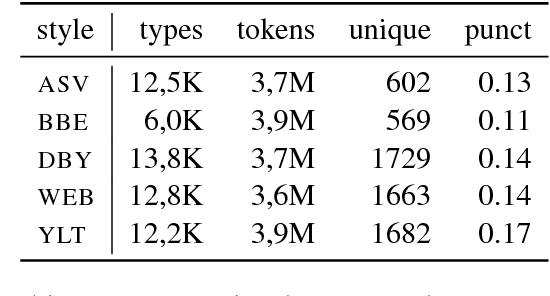
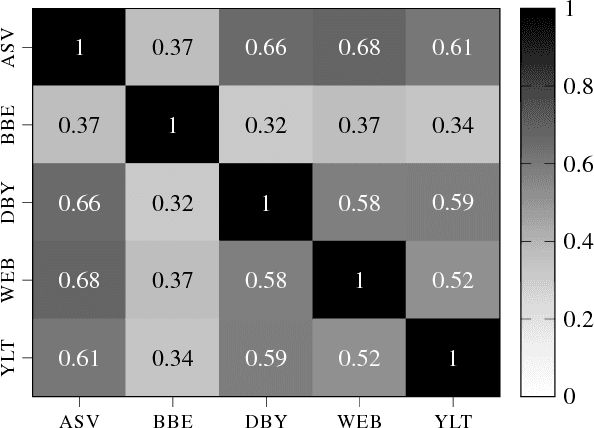
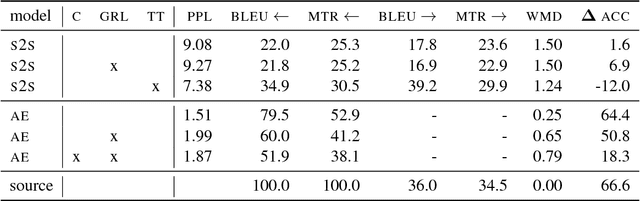
The task of obfuscating writing style using sequence models has previously been investigated under the framework of obfuscation-by-transfer, where the input text is explicitly rewritten in another style. These approaches also often lead to major alterations to the semantic content of the input. In this work, we propose obfuscation-by-invariance, and investigate to what extent models trained to be explicitly style-invariant preserve semantics. We evaluate our architectures on parallel and non-parallel corpora, and compare automatic and human evaluations on the obfuscated sentences. Our experiments show that style classifier performance can be reduced to chance level, whilst the automatic evaluation of the output is seemingly equal to models applying style-transfer. However, based on human evaluation we demonstrate a trade-off between the level of obfuscation and the observed quality of the output in terms of meaning preservation and grammaticality.