 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the reliability of feature attribution methods for speech classification
May 22, 2025As the capabilities of large-scale pre-trained models evolve, understanding the determinants of their outputs becomes more important. Feature attribution aims to reveal which parts of the input elements contribute the most to model outputs. In speech processing, the unique characteristics of the input signal make the application of feature attribution methods challenging. We study how factors such as input type and aggregation and perturbation timespan impact the reliability of standard feature attribution methods, and how these factors interact with characteristics of each classification task. We find that standard approaches to feature attribution are generally unreliable when applied to the speech domain, with the exception of word-aligned perturbation methods when applied to word-based classification tasks.
QE4PE: Word-level Quality Estimation for Human Post-Editing
Mar 04, 2025Word-level quality estimation (QE) detects erroneous spans in machine translations, which can direct and facilitate human post-editing. While the accuracy of word-level QE systems has been assessed extensively, their usability and downstream influence on the speed, quality and editing choices of human post-editing remain understudied. Our QE4PE study investigates the impact of word-level QE on machine translation (MT) post-editing in a realistic setting involving 42 professional post-editors across two translation directions. We compare four error-span highlight modalities, including supervised and uncertainty-based word-level QE methods, for identifying potential errors in the outputs of a state-of-the-art neural MT model. Post-editing effort and productivity are estimated by behavioral logs, while quality improvements are assessed by word- and segment-level human annotation. We find that domain, language and editors' speed are critical factors in determining highlights' effectiveness, with modest differences between human-made and automated QE highlights underlining a gap between accuracy and usability in professional workflows.
Co-creation for Sign Language Processing and Machine Translation
Mar 03, 2025Sign language machine translation (SLMT) -- the task of automatically translating between sign and spoken languages or between sign languages -- is a complex task within the field of NLP. Its multi-modal and non-linear nature require the joint efforts of sign language (SL) linguists, technical experts and SL users. Effective user involvement is a challenge that can be addressed through co-creation. Co-creation has been formally defined in many fields, e.g. business, marketing, educational and others, however in NLP and in particular in SLMT there is no formal, widely accepted definition. Starting from the inception and evolution of co-creation across various fields over time, we develop a relationship typology to address the collaboration between deaf, Hard of Hearing and hearing researchers and the co-creation with SL-users. We compare this new typology to the guiding principles of participatory design for NLP. We, then, assess 110 articles from the perspective of involvement of SL users and highlight the lack of involvement of the sign language community or users in decision-making processes required for effective co-creation. Finally, we derive formal guidelines for co-creation for SLMT which take the dynamic nature of co-creation throughout the life cycle of a research project into account.
Disentangling Textual and Acoustic Features of Neural Speech Representations
Oct 03, 2024



Neural speech models build deeply entangled internal representations, which capture a variety of features (e.g., fundamental frequency, loudness, syntactic category, or semantic content of a word) in a distributed encoding. This complexity makes it difficult to track the extent to which such representations rely on textual and acoustic information, or to suppress the encoding of acoustic features that may pose privacy risks (e.g., gender or speaker identity) in critical, real-world applications. In this paper, we build upon the Information Bottleneck principle to propose a disentanglement framework that separates complex speech representations into two distinct components: one encoding content (i.e., what can be transcribed as text) and the other encoding acoustic features relevant to a given downstream task. We apply and evaluate our framework to emotion recognition and speaker identification downstream tasks, quantifying the contribution of textual and acoustic features at each model layer. Additionally, we explore the application of our disentanglement framework as an attribution method to identify the most salient speech frame representations from both the textual and acoustic perspectives.
Encoding of lexical tone in self-supervised models of spoken language
Apr 03, 2024



Interpretability research has shown that self-supervised Spoken Language Models (SLMs) encode a wide variety of features in human speech from the acoustic, phonetic, phonological, syntactic and semantic levels, to speaker characteristics. The bulk of prior research on representations of phonology has focused on segmental features such as phonemes; the encoding of suprasegmental phonology (such as tone and stress patterns) in SLMs is not yet well understood. Tone is a suprasegmental feature that is present in more than half of the world's languages. This paper aims to analyze the tone encoding capabilities of SLMs, using Mandarin and Vietnamese as case studies. We show that SLMs encode lexical tone to a significant degree even when they are trained on data from non-tonal languages. We further find that SLMs behave similarly to native and non-native human participants in tone and consonant perception studies, but they do not follow the same developmental trajectory.
Homophone Disambiguation Reveals Patterns of Context Mixing in Speech Transformers
Oct 15, 2023



Transformers have become a key architecture in speech processing, but our understanding of how they build up representations of acoustic and linguistic structure is limited. In this study, we address this gap by investigating how measures of 'context-mixing' developed for text models can be adapted and applied to models of spoken language. We identify a linguistic phenomenon that is ideal for such a case study: homophony in French (e.g. livre vs livres), where a speech recognition model has to attend to syntactic cues such as determiners and pronouns in order to disambiguate spoken words with identical pronunciations and transcribe them while respecting grammatical agreement. We perform a series of controlled experiments and probing analyses on Transformer-based speech models. Our findings reveal that representations in encoder-only models effectively incorporate these cues to identify the correct transcription, whereas encoders in encoder-decoder models mainly relegate the task of capturing contextual dependencies to decoder modules.
Quantifying the Plausibility of Context Reliance in Neural Machine Translation
Oct 02, 2023Establishing whether language models can use contextual information in a human-plausible way is important to ensure their safe adoption in real-world settings. However, the questions of when and which parts of the context affect model generations are typically tackled separately, and current plausibility evaluations are practically limited to a handful of artificial benchmarks. To address this, we introduce Plausibility Evaluation of Context Reliance (PECoRe), an end-to-end interpretability framework designed to quantify context usage in language models' generations. Our approach leverages model internals to (i) contrastively identify context-sensitive target tokens in generated texts and (ii) link them to contextual cues justifying their prediction. We use PECoRe to quantify the plausibility of context-aware machine translation models, comparing model rationales with human annotations across several discourse-level phenomena. Finally, we apply our method to unannotated generations to identify context-mediated predictions and highlight instances of (im)plausible context usage in model translations.
Wave to Syntax: Probing spoken language models for syntax
May 30, 2023Understanding which information is encoded in deep models of spoken and written language has been the focus of much research in recent years, as it is crucial for debugging and improving these architectures. Most previous work has focused on probing for speaker characteristics, acoustic and phonological information in models of spoken language, and for syntactic information in models of written language. Here we focus on the encoding of syntax in several self-supervised and visually grounded models of spoken language. We employ two complementary probing methods, combined with baselines and reference representations to quantify the degree to which syntactic structure is encoded in the activations of the target models. We show that syntax is captured most prominently in the middle layers of the networks, and more explicitly within models with more parameters.
Putting Natural in Natural Language Processing
May 23, 2023Human language is firstly spoken and only secondarily written. Text, however, is a very convenient and efficient representation of language, and modern civilization has made it ubiquitous. Thus the field of NLP has overwhelmingly focused on processing written rather than spoken language. Work on spoken language, on the other hand, has been siloed off within the largely separate speech processing community which has been inordinately preoccupied with transcribing speech into text. Recent advances in deep learning have led to a fortuitous convergence in methods between speech processing and mainstream NLP. Arguably, the time is ripe for a unification of these two fields, and for starting to take spoken language seriously as the primary mode of human communication. Truly natural language processing could lead to better integration with the rest of language science and could lead to systems which are more data-efficient and more human-like, and which can communicate beyond the textual modality.
Quantifying Context Mixing in Transformers
Feb 08, 2023
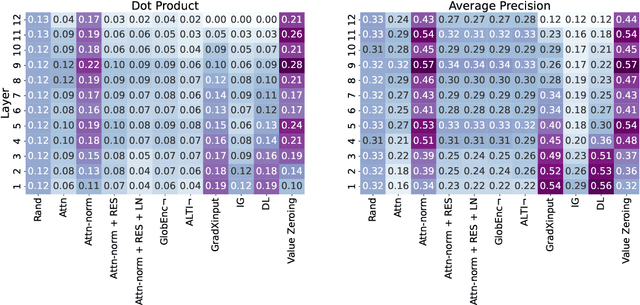
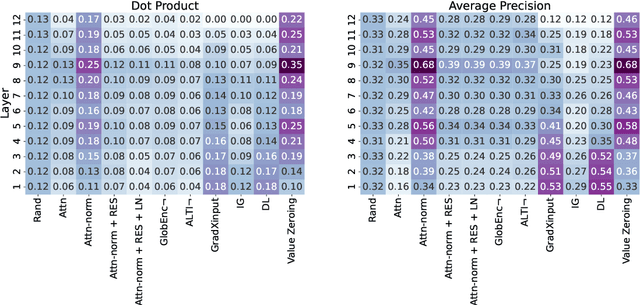

Self-attention weights and their transformed variants have been the main source of information for analyzing token-to-token interactions in Transformer-based models. But despite their ease of interpretation, these weights are not faithful to the models' decisions as they are only one part of an encoder, and other components in the encoder layer can have considerable impact on information mixing in the output representations. In this work, by expanding the scope of analysis to the whole encoder block, we propose Value Zeroing, a novel context mixing score customized for Transformers that provides us with a deeper understanding of how information is mixed at each encoder layer. We demonstrate the superiority of our context mixing score over other analysis methods through a series of complementary evaluations with different viewpoints based on linguistically informed rationales, probing, and faithfulness analysis.